![]()
概述
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[3]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。
Kafka架构
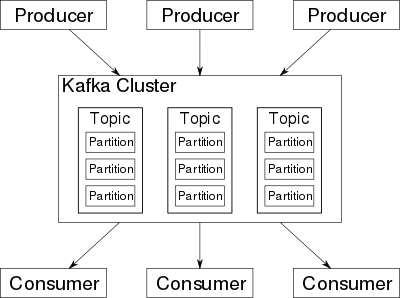
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为群集部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
Kafka架构的主要术语包括Topic、Record和Broker。Topic由Record组成,Record持有不同的信息,而Broker则负责复制消息。Kafka有四个主要API:
- 生产者API:支持应用程序发布Record流。
- 消费者API:支持应用程序订阅Topic和处理Record流。
- Stream API:将输入流转换为输出流,并产生结果。
- Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。
消息队列 | 选型比较:Kafka vs RabbitMQ
▶ Kafka
- 模型: 订阅/发布, 生产者和消费者是多对多
- 存储: 磁盘
- 吞吐量/延迟: 10W, 毫秒级
- 架构: 参考 [[消息队列-Kafka-总体架构]]
- 高可用机制: 参考 [[消息队列-Kafka-特性]]
- 如何保证顺序性: 顺序性指 生产者的(带有顺序性的)消息, 如何保证消费者也按照该顺序消费
- 生产者: 因为kafka 的topic 存储于多个分区, 为了防止一组顺序消息被投放到不同分区, 可以指定消息的key, 相同k的消息一定被发送到相同分区;
- 消费者: @TODO
- 防重复消费: 消费者在消费掉某条数据后, 把该条数据的offset提交给zk, 下次消费者请求数据, kafka 从 offset处开始
- 防消息丢失机制: 因为kafka partition 的多副本机制, 要考虑 如果发生leader-follower切换的情况下, 如何不丢数据
- 生产者丢数据: 设置
acks=all, 生产者投递消息, leader 保证所有 partition 都同步了数据才发送 ack 给生产者, 否则生产者会一直重试投递; - 消费者丢数据: 关闭消费者的自动提交offet, 需要消费者业务代码手动的提交offset
- 生产者丢数据: 设置
▶ RabbitMQ
- 模型: PTP, 生产者消费者1对1
- 存储: 非持久化的消息一般只存在于内存中,在内存紧张的时候会被换入到磁盘中,以节省内存。
- 吞吐量/延迟*: 1W, 微秒级
- 架构: 基于队列实现, 可以”不同业务使用不同MQ实例”来做MQ的垂直切分, 同时RabbitMQ还提供了镜像模式, 即一个队列有多个镜像, 写入队列的数据会被同步到其他镜像队列上去( RbMQ如何实现主队列失效, 切换镜像队列的? )
- 高可用机制: 镜像模式, 每个RabbitMQ节点上都一个queue的镜像
- 如何保证顺序性机制: 队列的FIFO, 消费者多线程的情况下如何保证顺序?
- 防重复消费:
- 防消息丢失机制:
- 生产者防丢: confirm 模式, MQ Server 收到生产者发送的消息, 会返一个ack
- MQ Server防丢: 持久化
- 消费者防丢: 关闭自动ack, 消费者取到消息, 业务代码处理完后, 再调用 ack api通知 MQ Server