@TODO
- 链表, 队列
- 平衡树, 红黑树
- 哈希
- 优先队列
- 并查集Union-find(不相交集,第8章)
- 补充: 线段树
树
概念
- 树的阶: 一个节点拥有的子节点最大值, 二叉树的阶是2
- 树的度: 同阶的概念, 为什么 B-tree 在不同著作中度的定义有一定差别? - 知乎
- 叶子节点: 没有子节点的节点,称为叶子节点
- 节点的高度: 到最深树叶的路径长度
- 节点的深度: 节点到根, 根节点深度为0
- 树的高度: 节点的高度
常用树结构
- 二叉树: 每个节点的叶子不超过2
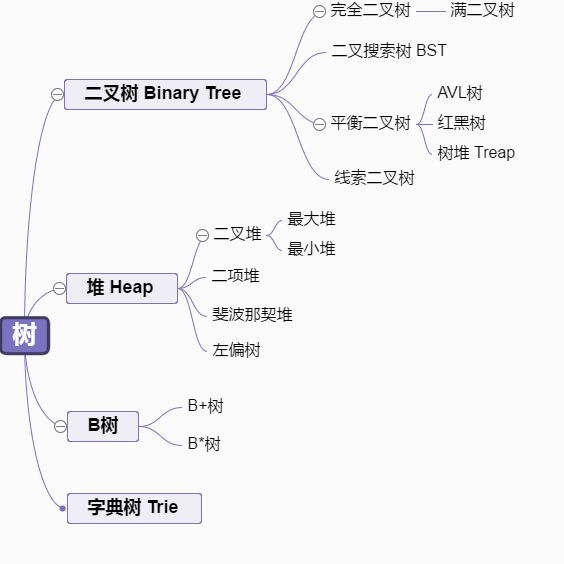
- 完全二叉树: 若设二叉树的深度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树
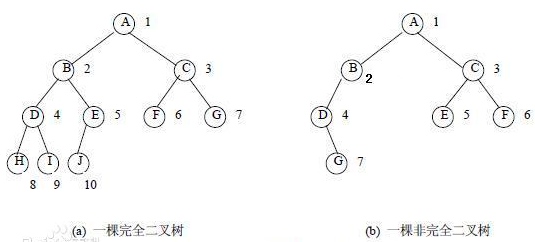
- 二叉搜索树(BinarySearchTree): 对于树中某个节点X, 左子树中所有值都小于X, 右子树所有值都大于X; 不足: 但是当原序列有序时二叉搜索树为右斜树,同时二叉树退化成单链表,搜索效率降低为 O(n)。时间复杂度:
- 索引:
O(log(n)) - 搜索:
O(log(n)) - 插入:
O(log(n)) - 删除:
O(log(n))
- 索引:
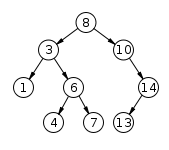
- 二叉堆(Binary Heap) : 二叉堆是”完全二叉树”或者是”近似完全二叉树”, 父节点的键值总是小于或等于子节点(根节点的值是最小的) //优先队列
PriorityQueue
- 平衡二叉树(AVL): 任何节点的左右子树高度差不超过1;
- 红黑树: 红黑树是一种自平衡”二叉查找树”。红黑树在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍.
- 如果插入一个node引起了树的不平衡,AVL和RB-Tree都是最多只需要2次旋转操作,即两者都是O(1);但是在删除node引起树的不平衡时,最坏情况下,AVL需要维护从被删node到root这条路径上所有node的平衡性,因此需要旋转的量级O(logN),而RB-Tree最多只需3次旋转,只需要O(1)的复杂度。
- B-树: “Balance Tree”, 阶为
M的树, 满足:- 每个非叶子节点由 n 个关键字和 n+1 个指针构成,
- 所有节点关键字是按递增次序排列,并遵循左小右大原则
- 根节点的子节点数在 2 ~ M 之间
- 其他节点的子节点数在 M/2 ~ M 之间
- 所有叶子节点在相同的高度
- 一个度为M的B-Tree,设其索引N个key,则其树高h的上限为 $\log_d((N+1)/2)$,检索一个key复杂度为 $\log_d N$。
- B+树:
- 要存储的数据只在叶子节点中, 非叶子节点不存储数据, 只有关键字;
- 相邻的叶子节点之间都有一个链指针,不需要遍历整棵树就可以得到所存储的全部数据// Mysql执行range-query扫库很方便
二叉树
二叉树遍历
- 先序(preOrder): 中-左-右
- 中序(inOrder):
- 后序(postOrder):
▶ 先序遍历(递归):
public void preOrder(Node<T> n) { |
▶ 先序-非递归, 最简单的一种:
public void preOrder(Node root) { |
▶ 先序-非递归(方法2), 使用栈模拟递归:
public void preOrder(Node root) { |
▶ 中序-非递归与上面类似
▶ 后序-非递归(需要辅助栈):
- Push根结点到第一个栈s1中。
- 从第一个栈s1中Pop出一个结点,并将其Push到第二个栈output中。
- 然后Push该结点的左孩子和右孩子到第一个栈s中。
- 重复过程2和3直到栈s为空。
- 完成后,所有结点已经Push到栈output中,且按照后序遍历的顺序存放,直接全部Pop出来即是二叉树后序遍历结果。
public void postOrder(Node root) { |
▶ 层序遍历(非递归算法):
第一个队列currentLevel用于存储当前层的结点,第二个队列nextLevel用于存储下一层的结点。当前层currentLevel为空时,表示这一层已经遍历完成,可以打印换行符了。
然后将第一个空的队列currentLevel与队列nextLevel交换,然后重复该过程直到结束。
public void levelOrder(Node root) { |
节点删除/插入
AVL树
任何节点的左右子树高度差不超过1
旋转
AVL树在插入/删除节点后, 需要用旋转的操作重新平衡;
概念: 「节点的平衡因子」 每个结点的平衡因子就是该结点的左子树的高度减去右子树的高度,平衡二叉树的每个结点的平衡因子的绝对值不会超过2
以下图表以4列表示4种需要重新做平衡的情况, Root是失去平衡树的根节点(左右子树高度差大于1),
- 左左: 失衡节点root的左子树更高, root左子树的左子树更高
- 右右:
- 左右: 失衡节点root的左子树更高, root左子树的右子树更高
- 右坐:
图: 四种情况的旋转(Root是失去平衡树的根节点,Pivot是旋转后重新平衡树的根节点),
可以看到需要1~2次旋转即可使不平衡节点重新平衡: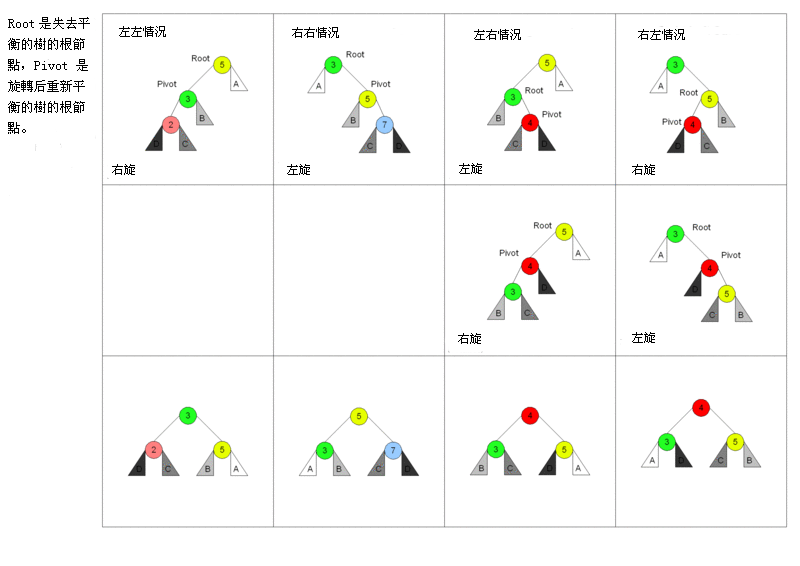
复杂度
- 查找: 可以像普通二叉查找树一样的进行,所以耗费O(log n)时间,因为AVL树总是保持平衡的
- 插入: 向AVL树插入,可以透过如同它是未平衡的二叉查找树一样,把给定的值插入树中,接着自底往上向根节点折回,于在插入期间成为不平衡的所有节点(平衡因子>1, 即左右子树高度差)上进行旋转来完成。上面分析了四种情况, 旋转1~2次即可完成, 所以也是
O(log n) - 删除:
- 先看二叉查找树(BST)的删除操作: 当删除一个结点P,首先需要定位到这个结点P,这个过程需要一个查找的代价。然后稍微改变一下树的形态。如果被删除结点的左、右子树只有一个存在,则改变形态的代价仅为O(1)。如果被删除结点的左、右子树均存在,只需要将当P的左孩子的右孩子的右孩子的…的右叶子结点与P互换(左的右右右, 也即比P小但是p最大的孩子 ),在改变一些左右子树即可。因此删除操作的时间复杂度最大不会超过
O(logN)。 - 从AVL树中删除,AVL删除结点的算法可以参见上面BST的删除结点,但是删除之后必须检查从删除结点开始到根结点路径上的所有结点的平衡因子。因此删除的代价稍微要大一些。每一次删除操作最多需要O(logN)次旋转。因此,删除操作的时间复杂度为 O(2logN)
- 先看二叉查找树(BST)的删除操作: 当删除一个结点P,首先需要定位到这个结点P,这个过程需要一个查找的代价。然后稍微改变一下树的形态。如果被删除结点的左、右子树只有一个存在,则改变形态的代价仅为O(1)。如果被删除结点的左、右子树均存在,只需要将当P的左孩子的右孩子的右孩子的…的右叶子结点与P互换(左的右右右, 也即比P小但是p最大的孩子 ),在改变一些左右子树即可。因此删除操作的时间复杂度最大不会超过
红黑树
红黑树的5个性质:
- 每个结点要么是红的要么是黑的。
- 根结点是黑的。
- 每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
- 如果一个结点是红的,那么它的两个儿子都是黑的。
- 对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。
正是红黑树的这5条性质,使一棵n个结点的红黑树始终保持了logn的高度,从而也就解释了上面所说的“红黑树的查找、插入、删除的时间复杂度最坏为O(log n)”这一结论成立的原因。
下图中,”叶结点” 或着叫”NULL结点”,它不包含数据而只充当树在此结束的指示,这些节点在绘图中经常被省略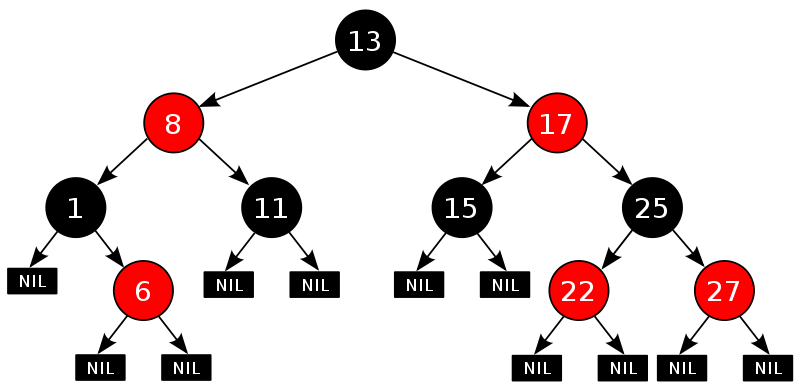
如何平衡
复杂度
- 查找代价:由于红黑树的性质(最长路径长度不超过最短路径长度的2倍),可以说明红黑树虽然不像AVL一样是严格平衡的,但平衡性能还是要比BST要好。其查找代价基本维持在O(logN)左右,但在最差情况下(最长路径是最短路径的2倍少1),比AVL要略逊色一点。
- 插入代价:RBT插入结点时,需要旋转操作和变色操作。但由于只需要保证RBT基本平衡就可以了。因此插入结点最多只需要2次旋转,这一点和AVL的插入操作一样。虽然变色操作需要O(logN),但是变色操作十分简单,代价很小。
- 删除代价:RBT的删除操作代价要比AVL要好的多,删除一个结点最多只需要3次旋转操作。
B树
→ [MySQL#索引原理]
几种树的复杂度比较
线段树
优先队列(堆)
二叉堆就结构性质上来说就是一个完全填满的二叉树,满足树的结构性和堆序性。堆序性指的是:父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
散列表(Hash Table)
- 解决冲突
- 链表分离: Java的HashMap
- 开放定址: