—Part 1: ANSI C—
基本数据类型
- C/C++作为一种强类型语言, 一个变量被使用前必须被定义.
- 在32位系统中基本类型的长度(字节): char(1B), short(2B), int(4B), 指针(4B) long(4B), float(4B), double(8B), long long(8B);
- 在64位系统中基本类型的长度(字节): char(1B), short(2B), int(4B), 指针(8B) long(8B), float(4B), double(8B), long long(8B);
- long 和 int 范围是[-2^31,2^31),即-2147483648~2147483647。
- 而unsigned范围是[0,2^32),即0~4294967295。也就是说,常规的32位整数只能够处理40亿以下的数。
- 相比于C++98标准,C++11整型的最大改变就是多了long long。
long long整型有两种:long long和unsigned long long。在C++11中,标准要求long long整型可以在不同平台上有不同的长度,但至少有64位。我们在写常数字面量时,可以使用LL后缀(或是ll)标识一个long long类型的字面量,而ULL(或ull、Ull、uLL)表示一个unsigned long long类型的字面量。比如:
long long int lli = -9000000000000000000LL;
unsigned long long int ulli = -9000000000000000000ULL;比如对于有符号的,下面的类型是等价的:long long、signed long long、long long int、signed long long int;而unsigned long long和unsigned long long int也是等价的。
- 同其他的整型一样,要了解平台上
long long大小的方法就是查看<climits>(或<limits.h>中的宏)。
与long long整型相关的一共有3个:LLONG_MIN、LLONG_MAX和ULLONG_MIN,它们分别代表了平台上最小的long long值、最大的long long值,以及最大的unsigned long long值。
int main() {
long long ll_min = LLONG_MIN;
long long ll_max = LLONG_MAX;
unsigned long long ull_max = ULLONG_MAX;
printf("min of long long: %lld\n", ll_min); // min of long long: -9223372036854775808
printf("max of long long: %lld\n", ll_max); // max of long long: 9223372036854775807
printf("max of unsigned long long: %llu\n", ull_max); // max of unsigned long long: 18446744073709551615
}
// 编译选项:g++ -std=c++11 2-2-1.cpp
// 在代码清单中,将以上3个宏打印了出来,对于printf函数来说,
// 输出有符号的long long类型变量可以用符号%lld,
// 无符号的unsigned long long则可以采用%llu。
大小端存储
大端/小端存储, big endian/little endian:
- MSB高位,LSB地位,比如自然数字0x1A39,1A是MSB,39是LSB,判断大小端存储,可根据数据在内存中存储的地址是以MSB/LSB为地址,
- 比如一个int,其LSB作为此数据的首地址(内存中的低地址),则为小端存储;
- –大端: LSB在高地址,MSB在低地址;
- –小端: MSB在高地址,LSB在低地址;
- 比如书写顺序0x1122,11是高字节MSB,22是低字节LSB.
- 大端存储:高地址22,低地址11;
- 小端存储:高地址11,低地址22;
运算符
- 位与
&, 位或|, 异或^, 取反~, 位左移<<, 位右移>> - sizeof是C语言的一种单目操作符,如C语言的其他操作符++、–等。它并不是函数。sizeof操作符以字节形式给出了其操作数的存储大小。操作数可以是一个表达式或括在括号内的类型名。操作数的存储大小由操作数的类型决定。
- 当操作数具有数组类型时,其结果是数组的总字节数
- 联合类型操作数的sizeof是其最大字节成员的字节数
- sizeof的优先级为2级,比乘除等3级运算符优先级高
当除数和被除数不同符号时:
取余向0方向舍弃小数位, 取模向负无穷方向舍弃小数位
比如4/(-3)约等于-1.3,
取余: 4 rem 3 = -1
取模: 4 mod 3 = -2
格式化输出
格式化输出printf是一个变参函数, 原型为int printf(char *format,...) ,
C语言用宏来处理这些可变参数, 根据参数入栈的特点从最靠近第一个可变参数的固定参数开始, 依次获取每个可变参数的地址. 例如printf ("Decimals: %d %ld\n", 1977, 650000L);
需要注意的是格式要跟变量的长度对应, 比如long long要使用%ll, int类型不能使用%c格式.
数组
数组 & 指针的不同
比如有:
char s[] = "hello"; |
- 初始化的不同
- 在第一句中,以
&s[0]开始的连续6个字节内存分别被赋值为: ‘h’, ‘e’, ‘l’, ‘l’, ‘o’, ‘/0’ - 第二句中,p被初始化为程序data段的某个地址,该地址是字符串”china”的首地址
- 在第一句中,以
- sizeof的不同:
sizeof(s)应为6, 而sizeof(p)应为一个”指针”的大小. &取地址操作符的不同:&s的类型为pointer to array of 6 chars.&p的类型为pointer to pointer to char.
数组退化
数组类型也是一种数据类型, 其本质功能和其他类型无异:定义该类型的数据所占内存空间的大小以及可以对该类型数据进行的操作(及如何操作).
数组在某些情况下, “数组类型的变量”会退化成指针类型,
这时候无法再获取数组长度, 会影响sizeof操作符的结果,
数组什么时候会”退化”
数组在除了3种情况外, 其他时候都要”退化”成指向首元素的指针. 这3中例外情况是:
比如有数组 char s[10] = "hello";
sizeof(s)&s- 用
char s[10]作为左值创建”字符串”,s仍然是数组类型
静态数组索引(C99)
下面的代码向编译器保证,你传递给f 的指针指向一个具有至少10个int 类型元素的数组的首个元素。我猜这也是为了优化;例如,编译器将会假定a 非空。编译器还会在你尝试要将一个可以被静态确定为null的指针传入或是一个数组太小的时候发出警告。
void f(int a[static 10]) { |
声明一个不可修改的数组,这和说明符int * const a.作用是一样的
void f(int a[const]) { |
柔性数组(flexible array)
C99中,结构中的最后一个元素允许是未知大小的数组,这就叫做柔性数组成员,但结构中的柔性数组成员前面必须至少一个其他成员。
柔性数组成员允许结构中包含一个大小可变的数组。sizeof返回的这种结构大小不包括柔性数组的内存。
包含柔性数组成员的结构用malloc ()函数进行内存的动态分配,并且分配的内存应该大于结构的大小,以适应柔性数组的预期大小。
柔性数组到底如何使用呢?看下面例子:
typedef struct st_type |
有些编译器会报错无法编译可以改成:
typedef struct st_type |
这样我们就可以定义一个可变长的结构体,用 sizeof(type_a)得到的只有 4,就是sizeof(i)=sizeof(int)。
那个 0 个元素的数组没有占用空间,而后我们可以进行变长操作了。通过如下表达式给结构体分配内存:
type_a *p = (type_a*)malloc(sizeof(type_a) + 100*sizeof(int));
这样我们为结构体指针 p 分配了一块内存(该内存块大小远大于结构的大小)。用 p->item[n]就能简单地访问可变长元素。
但是这时候我们再用 sizeof(*p)测试结构体的大小,发现仍然为 4。
已经确定不包含柔性数组的内存大小。只是说在使用柔性数组时需要把它当作结构体的一个成员,仅此而已。再说白点,柔性数组其实与结构体没什么关系,算不得结构体的正式成员。
需要说明的是:C89不支持这种东西,C99把它作为一种特例加入了标准。但是,C99
所支持的是 incomplete type,而不是 zero array,形同 int item[0];这种形式是非法的,C99支
持的形式是形同 int item[];只不过有些编译器把 int item[0];作为非标准扩展来支持,而且在
C99发布之前已经有了这种非标准扩展了,C99发布之后,有些编译器把两者合而为一了。
当然,上面既然用 malloc函数分配了内存,肯定就需要用 free函数来释放内存:free(p);
参考:
- 结构体对齐 http://blog.csdn.net/yinkaizhong/archive/2009/12/06/4951288.aspx @Ref
- 柔性数组 http://blog.csdn.net/yiruirui0507/archive/2010/07/22/5756328.aspx @Ref
指针&引用
指针
- 函数指针:
typedef void (*pf)(int, int); restrict关键词是一个限定词,可以被用在指针上。它向编译器保证,在这个指针的生命周期内,任何通过该指针访问的内存,都只能被这个指针改变。比如,
int f(const int* restrict x, int* y) { |
引用
inline String& String::operator=(const String& other) |
结构体
在C99之前,你只能按顺序初始化一个结构体。在C99中你可以这样做
struct Foo { |
这段代码首先初始化了foo.z,然后初始化了foo.x. foo.y 没有被初始化,所以被置为0。
这一语法同样可以被用在数组中。以下三行代码是等价的:
int a[5] = {[1] = 2, [4] = 5}; |
结构体字节对齐
一般结构体的
sizeof, gcc和cl编译器有所不同,以cl为例,- cl编译器下,
- (1)结构体成员变量的首地址能够被这个成员(该成员可能是个结构体)最宽基本类型成员的大小所整除;
- (2)sizeof(struct)的值等于struct内最大基本元素长度的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
- (3)每个成员相对结构体首地址的偏移量是该成员长度的整数倍,
- gcc以4的整数倍对齐;
- cl编译器下,
包含结构体成员的结构体,
- (1)在寻找最宽基本类型成员时,应当包括“子结构体”的成员;
(2)“子结构体变量”的首地址能够被其最宽基本类型成员的大小所整除;
struct S1 {
char c;
int i;
}; //sizeof(S1) = 8
struct S3 {
char c1;
S1 s; //8 bytes
char c2
};S1或S3的最宽简单成员的类型都为int,所以S3的最宽简单类型为int;
S3::s的类型是struct S1,其起始地址是sizeof(int)的整数倍(struct S1最宽的成员是int型);
S3占用内存如下:
S3:c1占1字, 填充3字, S1:c占一字, 填充3字, S1:i占4字, S3:c2占1字, 填充3字, 故sizeof(struct S3) = 16;
改变缺省的对齐条件, 即“成员相对于结构体首地址的偏移量,是成员大小的整数倍”,变成了“成员相对于结构体首地址的偏移量,是对齐字节的整数倍”
VC6中使用语法如下:
struct S1
{
char c;
int i;
}; // 6 bytes
struct S2{
char c1;
struct S1 sss;
char c2
};#pragma pack(n),如果n比结构体成员的sizeof值小,那么该成员的偏移量应该以此值为准,结构体成员的偏移量应该取二者的最小值。
上面对定义中最宽的int,和#pragma pack(2)比较,所以对齐条件是2字节;
char S1::c占1字,int S1::i宽度是4,这里不以4而是以2对齐,所以int S1::i的起始位置是2,sizeof(S1) == 6。
注: 没有任何成员的“空结构体”占1byte;
含位域结构体的sizeof
使用位域的主要目的是压缩存储,其大致规则为:
- 1) 如果相邻位域字段的类型相同,且其位宽之和小于类型的sizeof大小,则后面的字段将紧邻前一个字段存储,直到不能容纳为止;
- 2) 如果相邻位域字段的类型相同,但其位宽之和大于类型的sizeof大小,则后面的字段将从新的存储单元开始,其偏移量为其类型大小的整数倍;
- 3) 如果相邻的位域字段的类型不同,则各编译器的具体实现有差异,VC6采取不压缩方式,Dev-C++采取压缩方式;
- 4) 如果位域字段之间穿插着非位域字段,则不进行压缩;
- 5) 整个结构体的总大小为最宽基本类型成员大小的整数倍。
字符串
String flows("ffc");# flows分配在?
函数
重载函数
C++ 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。
重载运算符
头文件:
class MyString |
源文件:
|
宏(macro)
C/C++的宏定义将一个标识符定义为一个字符串,源程序中的该标识符均以指定的字符串来代替。宏的替换是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进行的处理。
宏主要用在宏定义和条件编译
宏定义
宏常量
#define MAX 1000: 在《Effective C++》中,这种做法却并不提倡,书中更加推荐以const常量来代替宏常量。因为在进行词法分析时,宏的引用已经被其实际内容替换,因此宏名不会出现在符号表中。所以一旦出错,看到的将是一个无意义的数字,比如上文中的1000,而不是一个有意义的名称,如上文中的MAX。而const在符号表中会有自己的位置,因此出错时可以看到更加有意义的错误提示。
宏函数
为什么大量的宏定义中用到了do-while:
|
所以正确的写法:
|
do{...} while(condition)语句最后可以有分号也可以没有, 这两种语法上都正确
宏定义中的”#”和”##”
#的功能是将其后面的宏参数进行字符串化操作(Stringfication):
|
#func替换后, 作为字符串拼接, 相当于printf("entry:" + funcName + "\n")
####被称为连接符(concatenator),用来将两个Token连接为一个Token。
struct command |
条件编译
#define常与#ifdef, #ifndef, defined指令配合使用,用于条件编译。
用宏控制debug日志:
|
通过DEBUG宏,我们可以在代码调试的过程中输出辅助调试的信息。当DEBUG宏被删除时,这些输出的语句就不会被编译。更重要的是,这个宏可以通过编译参数来定义。因此通过改变编译参数,就可以方便的添加和取消这个宏的定义,从而改变代码条件编译的结果。
—Part 2: C++—
类
访问控制
- private:只能由1.该类中的函数、2.其友元函数访问。不能被任何其他访问,该类的对象也不能访问。
- protected:可以被1.该类中的函数、2.子类的函数、以及3.其友元函数访问。但不能被该类的对象访问。
- public:可以被1.该类中的函数、2.子类的函数、3.其友元函数访问,也可以由4.该类的对象访问。
注:友元函数包括3种:设为友元的普通的非成员函数;设为友元的其他类的成员函数;设为友元类中的所有成员函数。
类实例占用的内存结
@TODO: 虚函数表
继承
虚函数
- 析构函数virtual的必要性? 如果一个类是作为基类的,那么该类的析构应该写为virtual; 这样在
delete 基类指针时, 会自动选择相应版本的析构函数.
类的继承后方法属性变化
- private 属性不能够被继承。
- 使用private继承,父类的protected和public属性在子类中变为private;
- 使用protected继承,父类的protected和public属性在子类中变为protected;
- 使用public继承,父类中的protected和public属性不发生改变;
多重继承
class Divide: public Base1, protected Base2 { ... };- Base的private在Divide中是否占用空间 // yes
- Base类的static成员, static成员是在堆还是全局区 ?
- 继承了多个基类的派生类, 有多个虚函数表,
- 如果派生类没有重写任何基类的virtual函数, 派生类也有虚函数表(vtable), 里面是指向基类的函数
- 如果派生类没有重写任何基类的virtual函数, 且派生类新建了一个virtual函数, 派生类的虚函数表(vtable)里面依次基类虚函数指针, 派生类自己的虚函数指针
虚继承
@TODO
类型转换
充满风险的隐式类型转换
施工中
现实类型转换
- 旧风格的类型转换:
- C 风格(C-style)强制转型:
(T) exdivssion// cast exdivssion to be of type T - 函数风格(Function-style)强制转型:
T(exdivssion)// cast exdivssion to be of type T
- C 风格(C-style)强制转型:
static_cast: 用法static_cast < type-id > ( expression ),- 上行转换(把子类的指针或引用转换成基类表示)是安全的;
- 进行下行转换(把基类指针或引用转换成子类指针或引用),由于没有动态类型检查,所以是不安全的
- 用于基本数据类型之间的转换,如把int转换成char,把int转换成enum。这种转换的安全性也要开发人员来保证
static_cast不能转换掉expression的const、volitale、或者__unaligned属性static_cast转换失败会…[?]// static_cast 示例
Base *a = new Base;
Derived *b = static_cast<Derived *>(a);
double d = 3.14159265;
int i = static_cast<int>(d);
dynamic_cast: 主要用来在继承体系中的安全向下转型。它能安全地将指向基类的指针转型为指向子类的指针或引用,- 为什么需要
dynamic_cast强制转换? 当无法使用virtual函数的时候 - 如果转型失败会返回null(转型对象为指针时)或抛出异常(转型对象为引用时)
dynamic_cast会动用运行时信息(RTTI)来进行类型安全检查,因此dynamic_cast存在一定的效率损失。- 基类要有虚函数,否则会编译出错;
static_cast则没有这个限制。
- 为什么需要
智能指针
STL
@TODO
C++ 设计技巧
RAII
资源获取即初始化( Resource Acquisition Is Initialization ),或称 RAII。
它将必须在使用前请求的资源(被分配的堆内存、执行的线程、打开的接头、打开的文件、被锁的互斥、磁盘空间、数据库连接等——任何存在于受限供给中的事物)的生命周期绑定到一个对象的生存期。
RAII 可总结如下:
- 将资源的操作封装入一个RAII类里:
- 构造函数请求资源,并建立所有类不变量或在它无法完成时抛出异常,
- 析构函数释放资源并决不抛出异常;
- 始终经由RAII类的实例使用资源,在栈上创建RAII类型的函数内变量,当函数退出时依靠”Stack winding”来保证一定调用RAII类的析构函数完成资源释放
例子1
template <TYPENAME T> |
问题: new Example()生成的Example实例, 如果没有调用delete(), RAII类的析构函数会被调用到吗?
例子2
错误的加锁:
void bad() |
正确的方法, 使用std::lock_guard:
std::mutex mutex; // 定义全局的mutex |
注:lock_guard是互斥封装器, 构造/析构函数定义如下:
explicit lock_guard(Mutex& m_): |
参考:
- RAII - cppreference.com @Ref
- 【C++设计技巧】C++中的RAII机制 @Ref
Pimpl
这个机制是”Private Implementation”的缩写: 也即 实现私有化,力图使得头文件对改变不透明。
“实现私有化”必要性
在C++中, 头文件(类的声明)和源文件(类的实现)是分开的,
举个例子, 头文件base.h里声明了一个基类Base, 如果改动Base的公有接口, 会导致所有包含base.h的类(调用Base类的代码, 以及Base的派生类)都有重新编译, 在一个大工程中,这样的修改可能导致重新编译时间的激增。你可以使用Doxygen或者SciTools看看头文件依赖。
改动公有接口导致的编译时间激增是可以理解的, 但是如果我们改动了Base的私有接口或者成员, 也会导致上面编译时间激增的情况, 这就有些不可接受了.
如何Pimpl
MyClass.h 文件内容如下:
class MyClassImpl; // forward declaration |
MyClass.cpp 文件内容如下:
// 定义MyClass的函数: |
总结
- Pimpl要实现的是, 在对类的私有函数/成员做改动时, 不希望(所有包含该头文件的)源文件被重新编译.
- 如果一个类被设计为基类,应避免在头文件中出现private函数或成员, 如果该类有private的函数或成员,最好把它们放进“前置声明(forward declaration)”的类里面,以避免private的声明出现在头文件;
- Java需要这种机制吗 ? 不需要, java里有
interface, interface里不包含私有数据的, 所以不会有“改动上层类的私有数据导致编译量增加”这种问题.
前置声明(forward declaration)
如果类A中, 有C类型的成员, 则可以在A.h中声明该成员之前, 用class C;的方式来前置声明类型C, 而不再需要在A.h中包含C.h文件:
A.h头文件:
// #include "C.h" // 不再需要这一行了 |
但是使用类型的前置声明是有条件的。假设有一个类C,那么如果你的类中如果有定义类型为C的非静态成员,抑或你的类继承了C的话,就不能使用类Test的前置声明,只能用include C.h的方式
大概有三种情况可以使用前置声明:
- 参数或返回类型为C的函数声明;
- 类型为C的类静态成员;
- 类成员变量的类型是 C类型的指针或引用:
C*或C&;
参考:
- 【C++程序设计技巧】Pimpl机制 @Ref
NVI
NVI(Non-Virtual Interface )机制:将虚函数声明为非公有,而将公有函数都声明为非虚 —— 虚拟和公有选其一。
- 如果在基类中作为”对外接口”(public)的函数, 一定设计成非virtual的
- 当且仅当子类需要调用基类的虚函数时才将虚函数设置为protected
- NVI机制不适用于析构函数,对于析构函数,如果是public的也应该是virtual的
如果一个类是作为基类的,那么该类的析构应该写为virtual; 这样在”delete 基类指针” 时, 会自动选择相应版本的析构函数.
为什么需要NVI
在标准C++库中我们可以看到这样的一个现象:6个公有虚函数,并且都是std::exception::what()和其重载。142个非公有虚函数。
这样设计的目的何在呢,为什么“多此一举”的把虚函数设置为非公有呢?
先看示例代码:
class Base { |
因为C++没有Interface的概念, 我们把基类里定义的 public且非虚的函数 视作”接口”, 与java中的接口不同的是, 基类的”接口”函数有自己的函数体.
- 一般在基类的”接口”里定义更上层的代码(参件
Foo()函数), 而把具体的实现放进private/protected的虚函数, 这样做的好处是实现了接口和实现的分离; - 派生类可以从基类继承的函数声明为
protected virtual的; - 需要派生类自己实现的函数声明为
private virtual的;
Pimpl和NVI都实现了:接口和实现的分离,将不经常变动的控制代码放入public非虚函数,经常变更或者需要派生类重写的放进非public的虚函数。
从设计模式上来看,Pimpl用的是委托,NVI用的继承.
参考:
—Part3: OS—
内存对齐
自然对齐 naturally aligned(我没找到英文定义,不知道源自哪里)
比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。
如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
对于C/C++中的基本数据类型,假设它的长度为n字节,那么该类型的变量会被编译器默认分配到n字节对齐的内存上。
例如,char的长度是1字节,char类型变量的地址将是1字节对齐的(任意值均可);int的长度是4字节,所以int类型变量将被分配到4字节对齐的地址上。这种默认情况下的变量对齐方式又称作自然对齐(naturally aligned)
What is natural alignment? Why should a generic pointer be aligned? - Quora
struct对齐方式:
- 每个成员相对结构体首地址的偏移量是该成员长度的整数倍,如果不是整数倍需要填充字节(gcc以4的整数倍对齐);
- “struct类型”的成员的首地址能够被这个成员(该成员是个结构体)最宽基本类型成员的大小所整除;
- sizeof(struct)的值等于struct内最大基本元素长度的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
写代码时,通常只需要关注:尽量将数据宽度大的字段(也即较长的double/longlong型变量)放到结构体的前面即可,数据宽度较小的字段无需编译器补齐,从而可以节约内存。
问题: 函数堆栈里的局部变量, 是不是按照上面的规则对齐的?
内存分配
回顾: 进程的虚拟内存地址布局
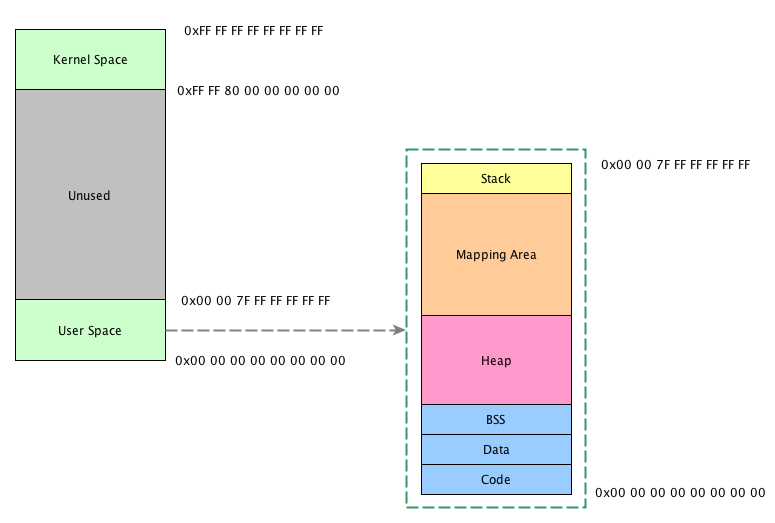
对用户来说,主要关注的空间是User Space。将User Space放大后,可以看到里面主要分为如下几段:
- Code:这是整个用户空间的最低地址部分,存放的是指令(也就是程序所编译成的可执行机器码)
- Data:这里存放的是初始化过的全局变量
- BSS:这里存放的是未初始化的全局变量
- Heap:堆,这是我们本文重点关注的地方,堆自低地址向高地址增长,后面要讲到的
brk相关的系统调用就是从这里分配内存 - Mapping Area:这里是与
mmap系统调用相关的区域。大多数实际的malloc实现会考虑通过mmap分配较大块的内存区域,本文不讨论这种情况。这个区域自高地址向低地址增长 - Stack:这是栈区域,自高地址向低地址增长
深入理解malloc
void *ptr = malloc(N) 之后发生了什么?
- 函数
malloc()通过brk()给进程分配了N bytes的线性地址区域(VM) 此时系统并没有随即分配页框(RAM), 进程也没有占用N bytes的物理内存. // 这也表明了, 你时常在使用top的时候VIRT值增大, 而RES值却不变的原因. - 当第一次通过指针使用此内存页, 在RAM中找不到与之相对应的页框. 发生缺页异常, 系统灵敏地捕获这一异常, 进入缺页异常处理阶段:接下来, 系统会分配一个页框(RAM)映射给它, 我们把这种情况(被访问的页还没有被放在任何一个页框中, 内核分配一新的页框并适当初始化来满足调用请求)称为Demand Paging.
- 过了很长一段时间, 通过
*ptr再次引用内存第一页. 若系统在RAM找不到它映射的页框(可能交换至磁盘了). 发生缺页异常, 并被系统捕获进入缺页异常处理. 接下来, 系统则会分配一页页框(RAM), 找到备份在磁盘的那“页”, 并将它换入内存(其实因为换入操作比较昂贵, 所以不总是只换入一页, 而是预换入多页. 这也表明某些文档说:”vmstat某时出现不少si并不能意味着物理内存不足”).
凡是类似这种会迫使进程去睡眠(很可能是由于当前磁盘数据填充至页框(RAM)所花的时间), 阻塞当前进程的缺页异常处理称为主缺页(major falut), 也称为大缺页. 相反, 不会阻塞进程的缺页, 称为次缺页(minor fault). - 通过指针使用到了N bytes的第二页. 参见第一次访问N bytes第一页, “Demand Paging”
- 通过
free()释放了内存, 线性地址区域被删除, 页框也被释放. - 再次通过
*ptr引用内存页, 已被free()了(用户进程本身并不知道). 发生缺页异常, 缺面异常处理程序会检查出这个缺页不在进程内存空间之内. 对待这种编程错误引起的缺页异常, 系统会杀掉这个进程, 并且报告著名的段错误(Segmentation fault).
主缺页异常处理过程示意图,参见 Handling Page Fault
Mapping Area和Heap
- 如果malloc申请的字节数N > 128k, 那么malloc会调用
mmap在Mapping Area区申请一块内存. - 对于小于128k的内存, malloc会调用
brk在Heap区申请内存. - Mapping Area和Heap的不同在于:
- malloc在Mapping Area区申请的内存块, 当调用free时, 虚拟内存和物理内存一起被释放了;
- malloc在Heap区申请的内存, 当调用
free(p)时, 如果p指向这块内存的更高的地址还有未free的内存块, p的内存块的虚拟内存/物理内存都不会立刻释放, 而是仅仅标示为”可再分配的”, - 实际上Linux维护了一个结构体链来维护已经分配过的Heap区, 每个结构体都对应一块malloc申请的内存块, 当调用malloc申请内存时(如果小于128k), 系统则会在这个链表里寻找一个”已经free且足够大”的块, 如果找不到符合条件的块, 则会在Heap的
Mapped Region申请新的; - 寻找”已经free且足够大”的块有first fit和best fit两种, 如果使用first fit不可避免的有空间浪费
- 因为Heap区都是小于128k的细碎内存块, 上面的链表可以防止反复申请/释放带来的内存碎片, 但mmap对应的区域都是大块(大于128K)的内存, 所以不用采用上面的机制.
+-----------+ |
Linux维护一个break指针,这个指针指向堆空间的某个地址。从堆起始地址到break之间的地址空间为映射好的,可以供进程访问;
而从break往高地址,是未映射的地址空间,如果访问这段空间则程序会报错。
参考:
深入理解new
C++中的new, operator new, placement new:
- operator new:
void* buf = operator new(100); operator new只负责申请内存, 在程序中遇到char* buf = new char[100]语句时,它将转换为对函数operator new的调用 - new(new operator):
A *a = new A();// 申请内存和构造 - placement new expression(定位表达式) :
A *p = new(pArea) A();// prt是被分配好内存的指针delete *p和delete pArea的区别?
new(new operator)
- new(
new operator或者叫new运算符): 负责分配内存并调用构造函数, 有new和::new之分,前者位于std - 对应的删除
delete operator, 调用析构函数并释放内存
A* a = new A(); |
通过反汇编可以看出A* = new A会被gcc解析成operator new(sizeof(A))和A()两个步骤, delete a被解析为~A()和operator delete(a)两个步骤。
通过下面的operator new一节可以得知, 如果一个类重载了operator new函数, new运算符会调用该类自己的operator new版本,
但是下面的语句可以指定使用全局的operator new: A *p = ::new A;
operator new
operator new指对new的重载形式,它是一个函数,并不是运算符。只负责分配内存而不会调用构造, 对于operator new来说,分为全局重载和类重载- 全局重载:
void* ::operator new(size_t size) - 类中重载:
void* A::operator new(size_t size), 注意operator new的参数是size_t, 返回是void指针
- 全局重载:
operator new()完成的操作一般只是分配内存,事实上系统默认的全局::operator new(size_t size)也只是调用malloc分配内存,并且返回一个void*指针。而构造函数的调用(如果需要)是在new(new operator或者叫new运算符)中完成的。- 如果调用
operator new分配内存失败, 会尝试调用new_handler, 如果仍然失败, 则抛出std::bad_alloc - 对应的删除operator delete:
operator delete(buf);
全局operaotr new 源码:
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc) |
如何调用operator new:
// 指定调用全局的operator new , 而不是类自己重载的版本 // 存疑 |
operator new有三种形式:
- (1)throwing
void* operator new (std::size_t size) throw (std::bad_alloc); - (2)nothrow
void* operator new (std::size_t size, const std::nothrow_t& nothrow_value) throw(); - (3)placement
void* operator new (std::size_t size, void* ptr) throw();
- (1)throwing
A* a = new A;这句代码里的new先是调用了throwing版本的operator new分配内存, 然后调用构造;A* a = new(std::nothrow) A;new先调用nothrow版本的operator new, 然后调用构造;- placement版本的operator new,它也是对operator new的一个重载,定义于
<new>中, 它多接收一个ptr参数,但它只是简单地返回ptr, 内部什么都没有做, 当使用 placement new expression 的时候会调用这个版本的operator new
重载::operator new
Effective C++ 第三版第 50 条列举了定制 new/delete 的几点理由
- 检测代码中的内存错误
- 优化性能
- 获得内存使用的统计数据
- 不改变operator new的默认参数重载: 用这种方式的重载,使用方不需要包含任何特殊的头文件,也就是说不需要看见这两个函数声明。“性能优化”通常用这种方式。
void* operator new(std::size_t sz) { |
- 增加新的参数的operator new, 为了跟踪内存分配的错误
void* operator new(size_t size, const char* file, int line); // 其返回的指针必须能被普通的 ::operator delete(void*) 释放 |
重载class::operator new
struct X { |
重载时的优先顺序
在使用 new运算符分配类类型的对象时(如果该类重载了operator new),将调用该类的operator new。
在使用 new运算符分配内置类型的对象、未重载operator new函数的类类型的对象、任何类型的数组时,将调用全局operator new 函数。
new_handler
operator new失败, 会调用new_handler, 如果new_handler不存在则抛出一个std::bad_alloc异常,std::set_new_handler可以为当前operator new指定一个new_handler
typedef void (*p_new_handler)(); |
如何设计一个良好的new_handler ? 《Effective C++》建议以下几种做法(选1即可):
- 让更多的内存可以被使用(也就是清理内存,让出更多的空间给这里的内存分配操作)
- 安装另一个new_handler(当这个new_handler无法处理当前分配失败的情况时,我们可以装在另外一个new_handler试图处理这种情况)
- 卸载new_handler(如果当前的new_handler确实无法处理当前错误,那么就将当前的new_handler卸载,例如nullptr,让new抛出bad::alloc的异常)
- 直接抛出bad::alloc的异常
- 调用abort()或exit()直接终止程序
placement new expression
char* ptr = new char[sizeof(T)]; // 分配内存 |
第二行的new(ptr) T("hello")会调用operator new的placement形式
delete tptr能释放ptr指向的内存吗?
delete和operator delete
- delete: 调用析构函数并释放内存
- operator delete:
operator delete(buf)
参考
- C++ 工程实践(2):不要重载全局 ::operator new() - CSDN博客 @Ref
- new 表达式 - cppreference.com @Ref
- operator new, operator new[] - cppreference.com @Ref
—Part4: Debug & Perf—
排查指针/内存问题 & 解决方案
指针引起的内存问题:
- 野指针读写: 野指针指的是未经初始化的指针(似乎
int *p;定义的指针没有自动置为Null) - 悬垂指针读写: 被free释放但是没有置为Null的指针
- 数组等类型读写越界
- 内存释放两次(DF,Double Free),第二次释放导致coredump
- 内存泄漏, 通常是不匹配地使用 malloc/new/new[] 和 free/delete/delete[]
Core Down问题排查
引起core down的原因可能有:
- 数组访问越界, 读到错误的数据, 这种情况一般直接Core down?
- 数组/指针写越界, 破坏了其他的数据, 这种情况可能当时不引起Core down
- Double Free, 第二次
free()直接Core down
不使用第三方工具
重载new/ malloc, 申请的内存添加头部/尾部特殊字节(线程id), 并用magic number填充, core down时可以分析是被哪个线程写入了
使用第三方工具/库解决方案:
一些满足特殊现象的分析方法:
- 对于固定会越界的代码位置来说,计算好数据位置,使得越界后第一个字节的内存起始的内存页
mprotect写保护中就可以了。随后像man文档的例子一样注册SIGSEGV信号的处理函数即可,这里可以用backtrace(3)和backtrace_symbols(3)等函数来打出调用栈,轻松找过越界的罪魁祸首 gdb调试支持对内存位置设置修改断点,而且gdb的内存断点不像直接用mprotect()有那么多限制
静态分析工具
代码静态分析工具, google有很多, 可以检查疑似写内存的问题
分析coredump文件
一般方法仍然是分析coredump文件, coredump文件里有哪些有用的信息?
- glibc的MALLOC_CHECK环境变量, 适用于“double free”, “free(invalid )”
- 实现: 实际上malloc()分配的内存会比用户实际申请的长度大一点,在返回给用户代码的指针位置的前面有一个固定大小的结构,放置着该块内存的长度、属性和管理的数据结构。
- 每当在程序运行过程free内存给glibc时,glibc会检查其隐藏的元数据的完整性,如果发现错误就会立即abort。
- electric-fence内存调试库: 适用于内存被写坏, 延后引发的core down。
- 原理是采用Linux的虚拟内存机制来保护动态分配的内存,在申请的内存的位置放置只读的哨兵页,在程序越界读写时直接coredump退出。
- 因为对内存做保护使用了mprotect(2)等API,这个API对内存设置只读等属性要求内存页必须是4K对齐的(本质上是Intel CPU的页属性设置的要求),所以内存使用率较低的程序可以用该库进行检查,但是内存使用率很高的程序在使用过程中会造成内存暴涨而不可用。
- Valgrind仿真工具(最常用的是Memcheck) 可以检查: 使用未初始化的内存,使用已经释放了的内存,内存访问越界等。
- 以上两种工具都很明显影响性能, 新版本的gcc(gcc49)提供了很好的内存访问检查机制
命令行参数 -fsanitize=address -fno-omit-frame-pointer- 检查内存越界的实现是..?
- 另外, Google的 address sanitizer(简称asan)是一个用来检测c/c++程序的快速内存检测工具。相比valgrind的优点就是速度快,官方文档介绍对程序性能的降低只有2倍。
内存泄漏排查
- 代码静态检查工具
- Valgrind仿真
- 重载全局的malloc / free函数,申请和释放内存的时候打印函数和返回地址(用异步日志库)
C++考虑使用shared_ptr, RAII机制来避免内存泄漏
多线程 & 高并发情况下
在增加debug log/ efence动态库 / 都会严重影响qps导致Core down无法重现, 另外特殊网络环境(高延迟, 丢包)下才会重现的问题
- 弱网络环境模拟
traffic control: 能够控制网络速率、丢包率、延时等网络环境,作为iproute工具集中的一个工具,由linux系统自带 - Http压测工具
wrk, 类似ab
手动异常测试请求:
- 异常的tcp连接。即在客户端 tcp connent系统调用时,10%概率直接close这个socket。
- 异常的ssl连接。考虑两种情况,full handshake第一阶段时,即发送 client hello时,客户端10%概率直接close连接。full handshake第二阶段时,即发送 clientKeyExchange时,客户端 10%概率直接直接关闭 TCP连接。
- 异常的HTTPS请求,客户端10%的请求使用错误的公钥加密数据,这样nginx解密时肯定会失败。
使用 tcpcopy等工具在线上引流到测试机器进行压测,如果常规流量达不到重现标准,可以对流量进行放大。若线上搭建环境测试有困难,可以对线上流量抓包,然后在线下重放(tcpdump、tcpreplay和tcprewrite等工具)。
这一步之后,一般情况下都能增大重现的概率。如果还难以重现,往往都是一些代码本身的竞态条件(Race Condition)造成的,一般需要在引流测试的同时对CPU或者IO加压,以增大资源竞争的概率来增加问题复现的概率。甚至有些问题是出现网络抖动等情况下,需要模拟弱网络的环境(Linux 2.6内核以上有netem模块,可以模拟低带宽、传输延迟、丢包等情况,使用tc这个工具就可以设置netem的工作模式)。
参考
- Linux环境下多线程C/C++程序的内存问题调试 | 浅墨的部落格 @Ref
- 高并发性能调试经验分享 - 腾讯WeTest @Ref
- 定位多线程内存越界问题实践总结 - DJ IN MUSIC - 博客园 @Ref
程序性能分析
@Ref: Perf – Linux下的系统性能调优工具,第 1 部分
perf
perf应该是最全面最方便的一个性能检测工具。由 linux内核携带并且同步更新,基本能满足日常使用。
- 使用 perf,您可以分析程序运行期间发生的硬件事件,比如 instructions retired ,processor clock cycles 等;您也可以分析软件事件,比如 Page Fault 和进程切换。
- 使用 Perf 可以计算每个时钟周期内的指令数,称为 IPC,IPC 偏低表明代码没有很好地利用 CPU。
- Perf 还可以对程序进行函数级别的采样,从而了解程序的性能瓶颈究竟在哪里等等。
通过perf top就能列举出当前系统或者进程的热点事件,函数的排序。 perf record能够纪录和保存系统或者进程的性能事件,用于后面的分析,比如火焰图。
oprofile
基本被perf取代
gprof
gprof主要是针对应用层程序的性能分析工具,缺点是需要重新编译程序,而且对程序性能有一些影响。不支持内核层面的一些统计,优点就是应用层的函数性能统计比较精细,接近我们对日常性能的理解,比如各个函数时间的运行时间,,函数的调用次数等,很人性易读。
原理是 编译期前在每个函数增加一个mcount函数调用, 用来记录函数耗时和调用次数。
systemtap
systemtap 其实是一个运行时程序或者系统信息采集框架,主要用于动态追踪,当然也能用做性能分析,功能最强大,同时使用也相对复杂。不是一个简单的工具,可以说是一门动态追踪语言。如果程序出现非常麻烦的性能问题时,推荐使用 systemtap。