JDK
Java Development Kit(JDK),包括一个完整的Java运行环境(Java Runtime Environment,JRE),还包括一系列用于Java开发的组件和工具(javac、jar、javap、javadoc、jdb、jps、jhat、jstack ……)
JDK 组件
java, javac, jar
- 编译Java源码:
javac -classpath PATH;PATH/xx.jar -sourcepath SOURCE_DIR -d OUTPUT_DIR - 把.class文件打成Jar包:
jar cvf JAR_FILE_NAME CLASS_FILE_NAMES - 运行executable的Jar包(Jar包指定了Main-Class):
java -jar JAR_FILE_NAME - 执行Jar包里的类(该类有main方法):
java -cp JAR_FILE_NAME CLASS_FULL_NAME - 执行Jar包里的类的指定方法:
java -cp JAR_FILE_NAME CLASS_FULL_NAME METHOD_NAME, 例如Tomcat 的启动脚本最终是执行了 Bootstrap这个主类中的start方法:java
-Djava.util.logging.config.file=/data0/tomcat/tomcat_8080/conf/logging.properties
-Xms2048m -Xmx2048m -XX:MaxPermSize=256m
-classpath /data0/tomcat/tomcat_8080/bin/bootstrap.jar:/data0/tomcat/tomcat_8080/bin/tomcat-juli.jar -Dcatalina.base=/data0/tomcat/tomcat_8080 -Dcatalina.home=/data0/tomcat/tomcat_8080 -Djava.io.tmpdir=/data0/tomcat/tomcat_8080/temp
org.apache.catalina.startup.Bootstrap start
javap, javah
- javah:根据class文件生成h头文件
javah -jni ClassFileName - javap:反编译class文件成字节码
javap -c ClassFileName
jdb
@TODO
javadoc
@TODO
jps, jstack, jhat, jmap
详见 [#JVM分析工具]
rt.jar, tools.jar, dt.jar
rt.jar, tools.jar, dt.jar 都包含于JRE(除此之外还JRE包括Java虚拟机):
- rt.jar: rt = runtime, 包括了Java核心类库,
java.*包下的类; - tools.jar: Jar包工具类, 我们执行的诸如
javac等命令实际上是通过java命令调用了tools.jar, 比如javac ClassName.java相当于java -cp tools.jar xx.Main ClassName.java; - dt.jar: 主要是Swing类库;
jar文件结构
- jar包中的 META-INFO/MANIFEST.MF:
Main-Class: com.xxx.Test#指定该选项可以更简单执行jar:java -jar JAR_FILE_NAMEClass-Path: libXX.jar#libXX.jar在相同目录下?
Oracle JDK vs Open JDK
区别与联系
免费 vs 付费
本节参考:
- OpenJDK 每6个月发布一个新版本,不过每次新的版本发布后,旧的就不维护了,比如OpenJDK 12发布之后,11版本便停止更新,停留在11.0.2版本,没有LTS版本;
- Oracle JDK同样每6个月发布一个新版本,其中9、10、12是 non-LTS版本,Oracle提供的免费更新只有6个月;
- Oracle JDK 8、11是 LTS版本,提供6个月免费更新,但在这之后的更新不再免费(仅针对商业用户)。
| Java 版本 | 发布日期 | Oracle 提供的免费更新 |
|---|---|---|
| Java 8(LTS) | 2014.3 | 2019.1 |
| Java 9 | 2017.9 | 2018.3 |
| Java 10 | 2018.3 | 2018.9 |
| Java 11(LTS) | 2018.9 | 2019.3 |
| Java 12 | 2019.3 | 2019.9 |
使用 Oracle JDK的解决方案:
- Oracle Java 8 (LTS):
- 免费:用 8u192以及更早版本(有安全隐患)
- 交钱使用 Oracle提供的更新(8u211之后的更新)
- Oracle Java 11 (LTS):
- 交钱
- Oracle Java 10、12、13 non-LTS
- 每6个月都升级到下一个版本的JDK
使用其他 OpenJDK的方案:
- Alibaba JDK, 阿里开源自用OpenJDK版本,Java社区迎来中国力量-InfoQ
- Azul Systems发布的Zulu产品线中的Java SE产品, 链接, 下图是Azul JDK的 LTS维护周期:

关于 Oracle的许可协议:
- Oracle JDK 的许可协议有两种:
- BCL(Oracle Binary Code License Agreement): 个人/开发使用免费,商用免费(但商用免费仅限于”通用计算”设备, 移动设备/嵌入式设备不包括在免费领域)。JDK中的某些商业特性(使用
-XX:+UnlockCommercialVMOptions打开的特性)仍是需要付费才可以使用的; - OTN(Oracle Technology Network License Agreement): 个人/开发使用免费,商用收费;
- BCL(Oracle Binary Code License Agreement): 个人/开发使用免费,商用免费(但商用免费仅限于”通用计算”设备, 移动设备/嵌入式设备不包括在免费领域)。JDK中的某些商业特性(使用
- Oracle 9/10是 BCL, 11/12变成了OTN,Oracle Java SE 11开始,按照OTN(Oracle Technology Network License Agreement)协议规定,只有在开发、测试及原型证明的场景下提供有限的授权。关于授权政策的一些具体问题可以参考下面网页: https://www.java.com/zh_CN/download/faq/distribution.xml @Ref
- Oracle JDK 8 在 8u211 和 8u212之后, 许可协议也变成了 OTN(因为 Oracle JDK 8 u192 是2019年1月前发布的最新版本,所以只要一直使用 JDK 8 u192 以及更早的版本,就不需付费)
JDK 版本历史
→ Java version history - Wikipedia
JSR, JCP …
- JSR 是Java Specification Requests的缩写,意思是Java 规范提案。是指向JCP(Java Community Process)提出新增一个标准化技术规范的正式请求。任何人都可以提交JSR,以向Java平台增添新的API和服务。JSR已成为Java界的一个重要标准。
- JCP, Java Community Process,Java 社区进程,JCP维护的规范包括J2ME、J2SE、J2EE,XML,OSS,JAIN等。组织成员可以提交JCR(Java Specification Requests),通过特定程序以后,进入到下一版本的规范里面。
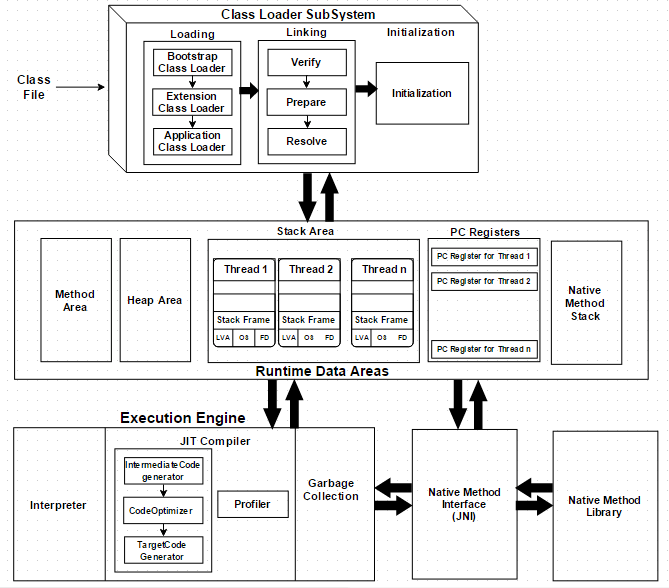
JVM Architecture Explained
- JVM 三个子系统: Class Loader, Runtime Data Area, Execution Engine
- Execution Engine: The bytecode, which is assigned to the Runtime Data Area, will be executed by the Execution Engine. The Execution Engine reads the bytecode and executes it piece by piece (// Execution Engine 又分为三个子系统: 解释器, JIT编译器, 垃圾收集器) :
- Interpreter: The interpreter interprets the bytecode faster but executes slowly. The disadvantage of the interpreter is that when one method is called multiple times, every time a new interpretation is required. // 解释器,每次执行同一段代码需要创建多个解释器?
- JIT Compiler: Execution Engine 使用 Interpreter解释代码并执行, 当 Execution Engine 检测到重复执行的代码时, JIT编译器将字节码便以为 native code
- Intermediate Code Generator: 中间代码生成器–产生中间代码
- Code Optimizer: 代码优化器–负责优化上面生成的中间代码
- Target Code Generator: 目标代码生成器–负责生成机器代码(或 native code)
- Profiler: 负责查找热点,即是否多次调用该方法。
- Garbage Collector: 垃圾收集器
JVM implementation
- HotSpot VM: Oracle / Sun JDK、OpenJDK的各种变种(例如IcedTea、Zulu),用的都是相同核心的HotSpot VM。
- OpenJ9 VM: OpenJ9
HotSpot VM 对比 Open J9
JVM内存分代
JDK6时期
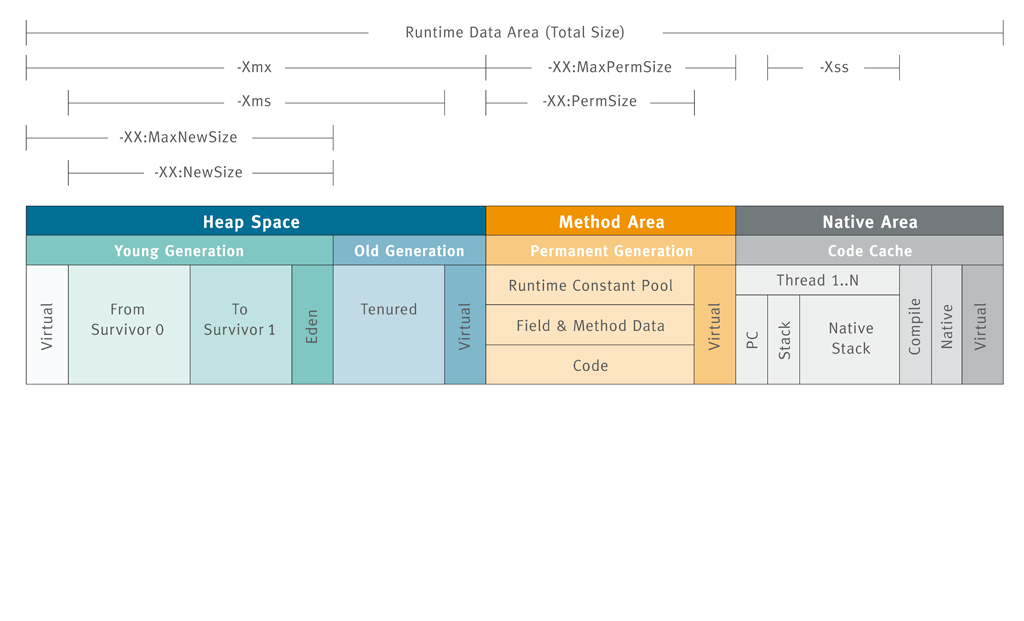
如上图, JDK6时代的JVM内存分为下面几个部分:
- 堆区(Heap Space): 这部分被所有线程共享, 包括:
- 年轻代:
eden:s0:s1的默认比例是8:1:1, 可见eden区大部分对象都是要被回收的; - 老年代:
老年代:年轻代的比例默认是2:1, 也就是说默认情况下堆区的2/3都属于老年代,
- 年轻代:
- 栈区(Stack Space): 每个线程独有, 包括: PC, Stack, Native Stack
- 方法区(Method Area)
JVM标准定义的内存区域为Heap/Stack Space/Medhod Area; 分代的名称(年轻代/老年代/永久代)是HotSpot中定义的, 并不是JVM标准中定义的, 注意区分 @Uncertain
Heap
- 这块区域被同一JVM实例的所有线程共享, Java对象全都创建在堆上.
- 堆的大小由
-Xms~-Xmx指定:-Xmx2048m -Xms2048m-Xmx堆的最大值默认是内存的1/4;-Xms堆的最小值;
YoungGen(新生代)
大小由参数-XX:NewSize ~ -XX:MaxNewSize (jdk 1.3)指定, jdk1.4之后统一成一个参数 -Xmn512m
新生代又被分为三个区域:
- Eden: 新创建的对象被分配在这里;
- To Survivor & From Survivor: 发生Young GC时, 有用的对象从
Eden区域 和From Survivor区域 移动到 →To Survivor, Eden 和 From被清空, 同时From 和 To 交换角色 ;
Eden区的TLAB
在Eden区创建对象时, JVM为了保证Eden区数据的线程安全, 会对分配过程加锁, 对于频繁的对象分配, 加锁会引起额外的性能开销.
所以 Hotspot 1.6的实现中引入了TLAB技术, 每个线程在Eden都独占一块缓存区 – TLAB(Thread Local Allocation Buffer), 每个线程创建的对象会被优先放入TLAB中, 因为在TLAB区域分配内存无需加锁, 可以提升对象创建效率.
当线程的”TLAB区”满了时, 会触发 “TLAB refill”: 线程把TLAB的所有权交回给共享的Eden, 然后重新从Eden里分配一块空间作为新的TLAB.
图-Eden区的结构:
参考列表:
OldGen(老年代)
- 也叫Tenured(晋升代), 在GC里被称为老年代(Old Generation)
- 没有参数可以指定大小, 但可以通过
Heap-新生代计算出来
Stack
每个线程都在这里开辟一块内存栈, 每个线程栈的大小可以由-Xss指定, 这块区域是每个线程私有的, 该区域内存包括:
- Program Counter Register: 计数器, 记录当前线程执行Java字节码的行号 // JVM中唯一没有规定任何 OutOfMemoryError 的区域;
- Stack: 即每个线程执行时的 栈帧, 栈帧里存储了当前方法的临时变量/函数的返回地址和参数/函数调用的上下文. 线程中每次有方法调用时,会创建一个 Frame,方法调用结束时 Frame 销毁。; // 该区域会抛出 StackOverflowError 和 OutOfMemoryError
- Native Method Stack: 除了上面的栈, 每个线程都有自己的Native方法执行栈(前者是线程执行字节码的栈, 后者是线程执行Native代码的栈, Java代码可以和Native代码互相调用), // 该区域会抛出 StackOverflowError 和 OutOfMemoryError
线程栈大小由参数
-Xss指定, 默认1m, 在tomcat这种多线程web服务器上, 保持1m或者更小可以处理更多的并发请求
Stack 和 Native Stack 都会抛出StackOverFlowError 和 OutOfMemoryError两种错误,StackOverFlowError: 若Java虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前Java虚拟机栈的最大深度的时候,就抛出StackOverFlowError异常。
OutOfMemoryError: 若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出OutOfMemoryError异常。
Method Area
- 方法区与堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做 Non-Heap(非堆),目的应该是与 Java 堆区分开来。
- HotSpot 虚拟机中方法区也常被称为 “永久代”,本质上两者并不等价。仅仅是因为 HotSpot 虚拟机设计团队用永久代来实现方法区而已,这样 HotSpot 虚拟机的垃圾收集器就可以像管理 Java 堆一样管理这部分内存,能够省去专门为方法区编写内存管理代码的工作。对于其他的虚拟机(如Oracle JRockit、IBM J9等)来说是不存在永久代的概念的。
- 所以在 HotSpot VM, 永久代也是有GC的, GC时机与老年代相同(再次提醒永久代不属于堆)
- HotSpot VM的永久代大小由
-XX:PermSize~-XX:MaxPermSize指定, 一般服务器设置为:-XX:MaxPermSize=500m
JDK 1.6的HotSpot 的永久代包括:
- Runtime Constant Pool, 运行时常量池, 详见 [#Java中的常量池]
- String Pool: 字符串常量池, 以”Hello”字面量方式创建的字符串会存储在这里.
如果运行时有大量的类产生,可能会导致方法区被填满,直至溢出。常见的应用场景如:
- Spring和ORM框架使用CGLib操纵字节码对类进行增强,增强的类越多,就需要越大的方法区来保证动态生成的Class可以加载入内存。
- 大量JSP或动态产生JSP文件的应用(JSP第一次运行时需要编译为Java类)。
- 基于OSGi的应用(即使是同一个类文件,被不同的类加载器加载也会视为不同的类)。
这些都会导致方法区溢出,报出java.lang.OutOfMemoryError: PermGen space
JDK7时期
String Pool被从 PermGen里移除了, 放在了Heap里, 并且可以通过-XX:StringTableSize指定其大小;
Runtime Constant Pool 也在1.7之后放入了Heap里? @Uncertain
此外JDK7的内存模型基本和6一样;
JDK6~7的VM参数总结
<JVM 6 & 7 Memory options> |
JDK8时期
在HotSpot JDK7以及更早的版本里, 永久代最大大小由-XX:MaxPermSize指定, 一旦超过这个大小就不能再扩展, 假如加载的类过多会导致Medhod Area过大而导致OOM,
HotSpot JDK8 移除 了JDK7的 PermGen(永久代), 类的元信息被移到了 Meta space(元空间), 这块内存放在 Native memory当中, 不再属于JVM线程内的内存区.
JDK7 移除了PermGen 的 运行时常量池 & 字符串常量池;
JDK8 移除了整个PermGen, 类的元信息被放在 MateSpace; // 运行时常量池呢?
JDK8的堆空间变得更加简单:
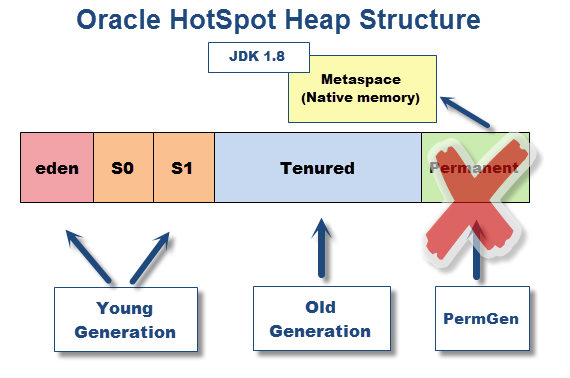
JDK8 使用 -XX:MetaspaceSize 和 -XX:MaxMetaspaceSize 指定 Meta space(元空间)的大小:
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=512m |
以上设置的MetaspaceSize 并不是永久代初始大小, 这个JVM参数是指Metaspace扩容时触发FullGC的初始化阈值,也是最小的阈值。这里有几个要点需要明确:
- 如果没有配置
-XX:MetaspaceSize,那么触发FGC的阈值是21807104(约20.8m),可以通过jinfo -flag MetaspaceSize pid命令得到这个值; - 如果配置了
-XX:MetaspaceSize,那么触发FGC的阈值就是配置的值; - Metaspace由于使用不断扩容到
-XX:MetaspaceSize参数指定的量,就会发生FGC;且之后每次 Metaspace扩容都可能会发生FGC(至于什么时候会,比较复杂,跟几个参数有关); - 如果 Old区配置 CMS垃圾回收,那么扩容引起的 FGC也会使用 CMS算法进行回收;
对于一个64位的服务器端JVM来说,其默认的 –XX:MetaspaceSize值为21MB. 这就是初始的高水位线. 一旦触及到这个水位线, Full GC 将会被触发并卸载没有用的类(即这些类对应的类加载器不再存活),然后这个高水位线将会重置. 新的高水位线的值取决于GC后释放了多少元空间. 如果释放的空间不足,这个高水位线则上升. 如果释放空间过多,则高水位线下降. 如果初始化的高水位线设置过低,上述高水位线调整情况会发生很多次. 通过垃圾回收器的日志我们可以观察到 Full GC 多次调用. 为了避免频繁的GC,建议将–XX:MetaspaceSize设置为一个相对较高的值.
以上参考: @Ref Java永久代去哪儿了
JVM分代设置大小(经验值)
- 堆区的默认值最大size是256MB, 永久代默认最大size是64MB,
堆:永久代大约是是4:1(Test @ JDK6 + Windows 32 bit) - 每个分代大小比例(经验值):
Eden : Survivor0 : Survivor1 : OldGen : PermGen = 8 : 1 : 1 : 20 : 5 - 每个分代具体设置多大, 还可以根据 JVM活跃数据 的大小进行估算:
活跃数据的大小是指,应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是Full GC后堆中老年代占用空间的大小。可以通过GC日志中Full GC之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取GC数据,通过取平均值的方式计算活跃数据的大小。活跃数据和各分区之间的比例关系如下

例如,根据GC日志获得老年代的活跃数据大小为300M,那么各分区大小可以设为:
总堆:1200MB = 300MB × 4 |
内存分区可能抛出的错误
- Stack :
StackOverflowError&OutOfMemoryError - Heap:
OutOfMemoryError - Method:
OutOfMemoryError: PermGen space(1.8之前) - MetaSpace(1.8+): @TODO
Java中的常量池
Class Constant Pool, 每个.class文件都包含的一块常量区, 存储了: 1 该类定义字面量(Literal, 字面量的字符串/final字段常量值/基本数据类型), 2 符号引用(Symbolic References, 类的完全限定名/方法名称和描述/字段名称和描述);Runtime Constant Pool, 位于PermGen的 Method Area里, .class文件常量池在类被加载后存放在此区域. class文件常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。而经过解析(resolve)之后,也就是把符号引用替换为直接引用;String Pool(也叫String Literal Pool, 字符串常量池), 在JDK6~JDK7u40版本是在PermGen里, JDK7u40之后的版本被移到了Heap里;- String Pool中存的是字面量的字符串,比如
String s = "Hello"之后字面量”Hello”就存储在这里 // pool中是保存的引用还是对象? - String Pool可以动态增长, 典型的是
String.intern方法; - 在HotSpot VM里实现的string pool功能的是一个
StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的);
- String Pool中存的是字面量的字符串,比如
对象在内存中的存储
- 堆区(年轻代/老年代):
- 每个类在被ClassLoader载入时会创建该类的
Class对象, 存放在堆区; - 类的
static members:- 如果是基本类型(int,float等)的static members, 在方法区跟类型信息在一起;
- 如果类类型的static members, 被new创建的对象本身在堆区, 引用(内存地址)还是在方法区;
- 字符串常量(字面量): JDK7之后移到了堆区;
- 每个类在被ClassLoader载入时会创建该类的
- 方法区(永久代): JDK8之后方法区被移动到了Native Memory中的 Meta space(元空间)
- 类的元信息:
- 类的完整有效名, 类的直接父类的完整有效名, 方法的形参类型以及返回类型,
- 类的方法字节码(bytecodes)
- 类的加载器的引用(ClassLoader)
- 运行时常量池
Runtime Constant Pool
- 类的元信息:
类信息在方法区的内存布局有些类似
.class文件结构, 参考后面的 “class文件结构”一节
字符串在内存中的存储
String pool: 全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
String Pool与String.intern()
Java并不要求常量只在编译期产生, 并非只有class文件常量池的内容才能进入方法区的”运行时常量池”,
运行期间可以添加常量进入常量池, 比如String.intern()方法;
运行str.intern()后, “首先在String Pool里查找是否有equals的字符串, 如果没有则在String Pool创建一个字面量字符串, 并返回其引用”
JDK6和JDK7的intern方法实现有差异, 具体看下面.
JDK6,7,8的String Pool
- JDK6: GermGen的大小在64位机器上一般为96MB, 由
-XX:MaxPermSize指定, String Pool(主要是个C++描述的StringTable)的大小默认是1009(StringTable “桶”的大小), 且这个大小不能扩展, StringTable的实现原理类似HashMap, hash值相同的会放进同一个桶的链表里. 如果太多调用了String.intern(), 会导致这个StringTable性能下降. - JDK7: String Pool从PermGen移到Heap, 并且增加了
-XX:StringTableSize参数可以配置String Pool的大小,-XX:StringTableSize=1000003. - JDK8: String Pool与7相比没有太大变化,
-XX:StringTableSize默认是60013, 可以用-XX:+PrintFlagsFinal获取当前你使用的值是多少.
以上参考自String.intern in Java 6, 7 and 8 - string pooling - Java Performance Tuning Guide @Ref
下面代码运行结果是 ?
String s = new String("1"); // 两个对象, 一个存储于String Pool, 一个在Heap |
先说答案: 在JDK6 下结果是 “false false”, 在JDK8下是 “false, true”.
没有在JDK8上验证, 但我觉得 7和8在 String Pool 上改动不大, 8仅仅是把 Method Area 移动到了 Native Memory 中 –被叫做 Metespace(元空间)的区域.
因为看不到 HotSpot的 native层源码, 所以只能看 OpenJDK的, 但是不保证 OpenJDK 与 HotSpot 实现一样 @TODO 有时间一定要看了才能解惑.
从JDK6 到 JDK7 的 String Pool 和 intern方法的改变都比较大(String Pool从 PermGen移动到了 Heap, String.intern()改变见下面的分析)
in JDK6:
String s = new String("Hello")会创建两个字符串对象, 一个在 String Pool里的字面值, 一个是 Heap里的对象.intern()方法首先在String Pool里查找是否有 equals的字符串, 如果没有则在 String Pool创建一个字面量字符串, 并返回其引用. 已经存在的话返回在String Pool里的引用.
String s = new String("1"), s创建后, String Pool 和 Heap各创建一个”1”, s指向的是Heap里的对象;String s2 = "1", s2指向的是 String Pool里的字面值;String s3 = new String("1") + new String("1")这时”11”在内存里只有 Heap里的一个, s3指向这个 Heap里的对象,s3.intern之后 String Pool里也创建一个”11”;String s4 = "11"s4指向的是 String Pool里的对象
in JDK7:
String s = new String("Hello")的行为跟6一样;str.intern()执行后, 如果再 String Pool里没有到 equals的字符串, 就不再在 String Pool里创建对象了, 而是直接把 Heap里的对象引用放进来. // 这也是6->7的 String的一个重要改变, 减少重复的字符串创建, 也更节省内存.
String s = new String("1"), s创建后, String Pool 和 Heap各创建一个”1”, s指向的是Heap里的对象;s.intern()检查 String Pool里已经存在”1”的字面值了, 什么都不做;String s2 = "1", s2指向的是 String Pool里的字面值;String s3 = new String("1") + new String("1")这时”11”在内存里只有 Heap里的一个, s3指向这个 Heap里的对象,s3.intern()在String Pool里找不到”11”, 但是不再创建新的, 而是直接把s3的引用复制进 String Pool,String s4 = "11"这种方式创建是指明在 String Pool里创建, 但是 String Pool里已经存在一个”11”的引用了, 那么s4直接指向这个引用. 所以s3和s4指向的都是 Heap里的”11”;
以上参考自深入解析String#intern - ImportNew @Ref
垃圾收集
Minor/Major/Full GC
我们把新生代 / 老年代 / 全部堆空间(包括新生代,老年代)对应的GC, 分别称为 Minor GC / Major GC / Full GC,
三个不同内存区域的GC细节如下:
① Minor GC: 在年轻代Young space(包括Eden区和Survivor区)中的垃圾回收称之为 Minor GC,或 Young GC
- 触发条件: 无法为一个新的对象分配空间时,比如 Eden区满了 。所以分配率越高,越频繁执行Minor GC。
- STW: Minor GC会Stop the World,如果Eden区大部分对象都要被GC(这也是正常情形)Minor GC耗时可以基本不记,但是如果Eden区大部分对象都不符合GC条件,暂停时间将会长很多。
- GC过程: 一般使用Copy GC, 具体步骤如下
- 用new或者newInstance等方式创建的对象默认都是存放在Eden区,Eden满了触发Minor GC,把存活的对象放入S0,并清空Eden;
- 第二次Eden满了,会把Eden和S0的存活对象放入S1,并清空Eden和S0区;
- 在几次Minor GC后, 有些对象在S0/S1之间来回拷贝几次, 将会进入老年代(Tenured), 所以young GC后OldGen的占用量通常会有所升高;
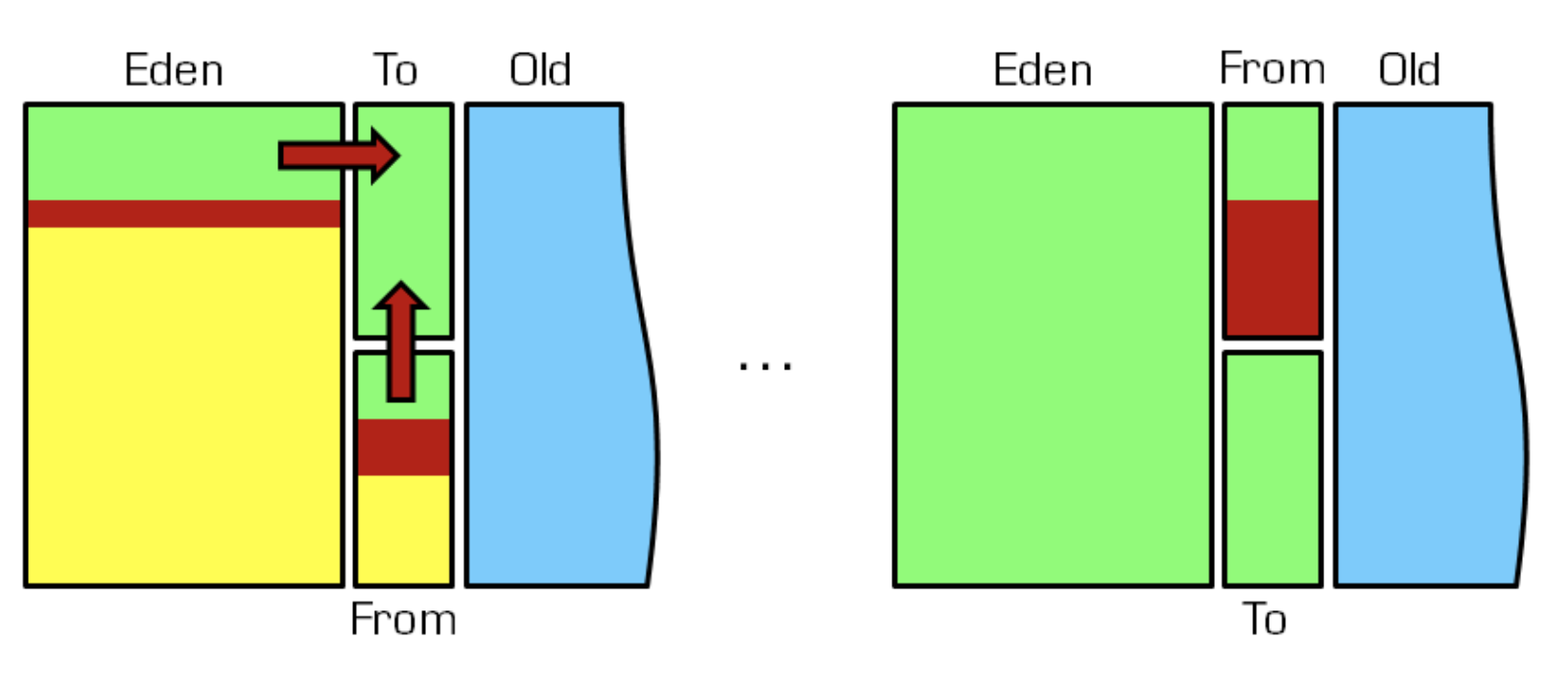
↑ Minor GC 图例: 左边是 Minor GC 前(黄色是垃圾对象, 红色是存活对象), 右边是 Minor GC 后
② Major GC: 清理老年代(Tenured space)
- 触发条件: 老年代使用率超过某个阈值,默认大约90%,许多Major GC是由Minor GC触发的。
- STW: 一般Tracing GC在标记和清理阶段都会有STW, 具体STW耗时根据使用哪种GC收集器而定;
- GC过程: 使用Mark-Sweep 或Mark-Compact算法;
③ Full GC: 清理整个堆,包括YoungGen / OldGen / PermGen(1.8之前) / Matespace(1.8+)等所有部分的全局范围的GC。
- 触发条件:
- 在将要进行(Young GC)时, 如果发现要晋升至OldGen的对象大小比OldGen剩余大小更大, 则不会触发young GC而是转为触发full GC; // 如果是用的CMS收集器可以在日志中看到 “promotion failed” 和 “concurrent mode failure”
- 当OldGen使用率大过某个比例; // ?
- 方法区满了触发(在Java8之前);
- Metaspace Space使用达到MaxMetaspace阈值(Java8+);
- 调用
System.gc(): 此方法的调用是建议JVM进行Full GC,虽然只是建议而非一定,但很多情况下它会触发 Full GC,从而增加Full GC的频率,也即增加了间歇性停顿的次数 - 当执行
jmap -histo:live或者jmap -dump:live
- STW: 视不同的GC收集器而定
- GC过程: 同上
需要明白的一点, 我们在jstat或GC日志中看不到Minor GC/ Major GC / Full GC这些名词, 这些术语无论是在 JVM 规范还是在垃圾收集研究论文中都没有正式的定义.
- 在jstat中, GC事件只分为两种: Young GC和 Full GC, 这里把Major GC和Full GC都算作了Ful GC。实际上
需要注意的是jstat返回的FGC并不是真正的Full GC发生次数, CMS的老年代GC分两个阶段(初始标记和Remark)都会Stop the World, 这两次STW在jstat里被视作了两次Full GC,所以jstat的FGC更接近于统计“Stop the World”的次数;- 在GC日志中, GC事件是由GC回收器命名的, 比如ParNew是清理年轻代(等同于Young GC), 日志里出现”CMS”等字样的都是指老年代的清理事件。
GC算法
主要GC算法有Copy GC 和Tracing GC, 后者又根据是否压缩内存分为Mark-Sweep 和 Mark-Compact GC算法.
Copy GC 算法
Copy GC算法(用于新生代的Minor GC): 把空间分成两部分,一个叫分配空间(Allocation Space),一个是幸存者空间(Survivor Space)。创建新的对象的时候都是在分配空间里创建。在GC的时候,把分配空间里的活动对象复制到Survivor Space,把原来的Allocation Space全部清空。然后把这两个空间交换角色。
- Copy GC是从GC roots对象开始对象图的深度优先遍历,访问到一个对象则在Survivor Space分配一个与该对象大小相同的一块内存,然后把这个对象的所有数据都拷贝过去(copy data),然后把它的visited标记为true,它的forwarding记为新的地址。
- 当存活对象少的时候,Copying GC算法的效率就有很高的吞吐量。Copying GC 是典型的采用空间换时间的方式来提升性能。
- Copying GC可以避免内存碎片。
Tracing GC 算法
Tracing GC算法(用于老年代的Major GC), 根据是否压缩内存又分两种 Mark-Sweep和 Mark-Compact
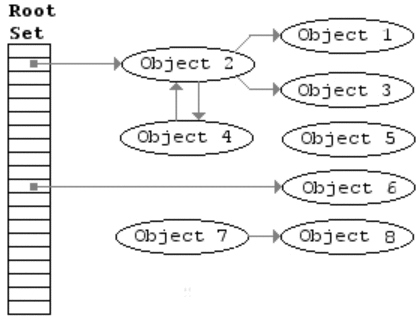
在介绍Tracing GC之前, 需要先熟悉几个名词, 可达性分析和GC Roots:
判断对象存活的两种方法:
- ① 引用计数法:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,无法解决对象相互循环引用的问题:比如对象a和b互相有一个对方的引用,虽然两个对象都没用了但是计数却不为0。
现在主流的JVM无一使用引用计数方式来实现Java对象的自动内存管理,但Py和PHP似乎是用的这种方法; - ② 可达性分析法(Reachability Analysis):它的处理方式就是,设立若干种roots对象,roots对象作为起点在图中进行深度优先遍历,每访问到一个对象,则该对象称为“可达对象”,也就是还活着的对象。否则就是不可达对象,可以被回收。
JVM里适用于老年代的GC收集器都使用了”可达性分析”来判断对象是否存活,是否可以回收
什么是 GC Roots:对于一个正在回收的空间,所有不在这个空间里又指向本空间中的对象的引用的集合就是“GC roots”。
一般而言,GC Roots 包括(但不限于)如下几种:
- Java 方法栈桢中的局部变量
- 已启动且未停止的Java线程以及线程栈帧内引用的对象
- 方法区中类静态属性实体引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI引用的对象
- 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的
Mark-Sweep
标记-清除算法 (Mark-Sweep)如同它的名字一样,算法分为“标记”和“清除”两个阶段:
- mark,从 root 开始进行树遍历,每个访问的对象标注为「使用中」
- sweep,扫描整个内存区域,对于标注为「使用中」的对象去掉该标志,对于没有该标注的对象直接回收掉
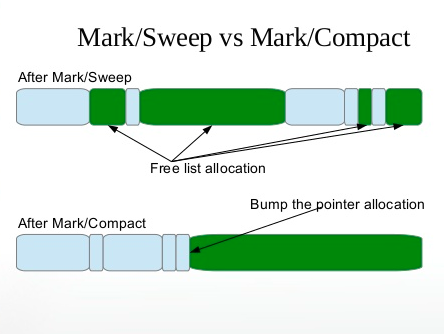
标记-清除算法最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。它的主要不足有两个:
- 效率问题,标记和清除两个过程的效率都不高, 回收时间与 heap 大小成正比;
- 空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
Mark-Compact
标记-整理算法 (Mark-Compact):
- mark: 从 root 开始进行树遍历,每个访问的对象标注为「使用中」
- compact: 扫描整个内存区域,把标注为「使用中」的对象移动到内存另一端,没有标注的对象回收掉。标记-整理算法是在标记-清除算法的基础上,又进行了对象的移动,因此成本更高,但是却解决了内存碎片的问题。
GC收集器
GC收集器是上面提到的几种GC算法的具体实现, 有些GC收集器只能用于新生代(比如ParNew), 有些只用于老年代(比如CMS), 有些可以同时用于两个代(Serial);
对于每种GC收集器, 都要注意以下几个问题:
a. 这种GC收集器可以用于哪个区, 如何启用;
b. 实现是什么样的, 分几个阶段, 哪些阶段有STW;
c. 并行(Parallel)还是并发(Concurrent)的, 注意“并发”和“并行”的不同:
并行(Parallel):使用多个线程同时执行GC任务,但此时用户线程仍然处于等待状态。并行GC的两个例子,一个是ParNew,一个是parallel scavenge。这两种GC的特点都是启动了多个GC线程来做垃圾回收。
名字Par(allel)开头的一般都是并行GC, 多个线程同时进行GC, 但仍会停顿;
并发(Concurrent):指用户任务与GC任务同时执行(但不一定是并行的,可能会交替执行),用户任务不会停顿。并发GC的一个典型例子,是CMS,看它的名字就知道了Concurrent Mark Sweep。
名字C(oncurrent)开头的是并发GC, GC线程和工作线程并发的执行;
下图是说明了不同分代可以使用的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用: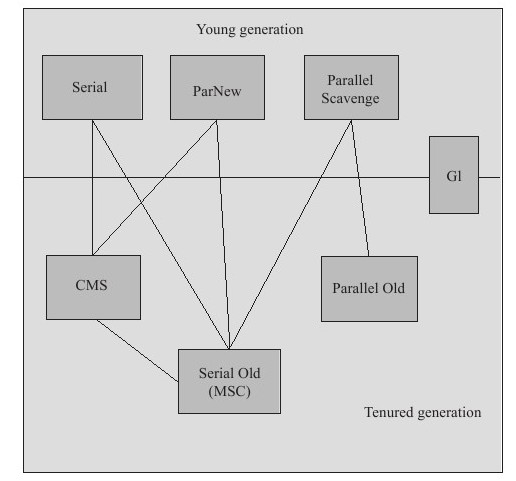
几种常见的GC收集器组合:
新生代Parallel + 老年代Parallel Old
新生代ParNew + 老年代CMS
新生代, 老年代都使用G1
下面介绍7种GC收集器 :
① 串行回收器(Serial Garbage Collector), 可以用于新生代和老年代, 下面都使用Serial New和Serial Old表示两代的GC回收器
- 通过JVM参数
-XX:+UseSerialGC可以使用串行垃圾回收器。 - 特性:
- 新生代、老年代都可以使用串行回收器, 新生代复制算法, 老年代标记-压缩算法.
- 串行垃圾回收器通过持有应用程序所有的线程进行工作。它为单线程环境设计,只使用一个单独的线程进行垃圾回收,可能会产生较长的停顿,所以可能不适合服务器环境。它依然是HotSpot虚拟机运行在Client模式下的默认的新生代收集器。
② ParNew回收器:Serial收集器新生代的多线程版本, 只适用于新生代.
- -XX:+UseParNewGC(new代表新生代,所以适用于新生代),-XX:ParallelGCThreads 线程数量
- 特性:
- ParNew收集器就是Serial收集器的多线程版本,它也是一个新生代收集器。除了使用多线程进行垃圾收集外,其余行为包括Serial收集器可用的所有控制参数、收集算法(复制算法)、Stop The World、对象分配规则、回收策略等与Serial收集器完全相同,两者共用了相当多的代码
- ParNew收集器是许多运行在Server模式下的虚拟机中首选的新生代收集器,原因是: 除了Serial收集器外,目前只有它能和CMS收集器(Concurrent Mark Sweep)配合工作
③ 并行回收器(Parallel Garbage Collector): 可以用于新生代和老年代, 新生代是Parallel Scavenge 收集器( 复制算法), 老年代是Parallel Old( 标记整理算法).
- JVM参数:
-XX:+UseParallelGC:新生代使用Parallel收集器 + 老年代使用串行收集器-XX:+UseParallelOldGC:新生代+老年都使用Parallel
- 特性:
- 使用多线程进行扫描堆并标记对象, 缺点是在minor和full GC的时候都会Stop the world
- CMS等收集器的关注点是尽可能缩短垃圾收集时用户线程的停顿时间,而Parallel Scavenge收集器的目标是达到一个可控制的吞吐量(Throughput)。
④ CMS(Concurrent Mark Sweep), 仅适用于老年代的回收器, 是一种以获取最短回收停顿时间为目标的收集器,它非常符合那些集中在互联网站或者B/S系统的服务端上的Java应用,这些应用都非常重视服务的响应速度。从名字上(“Mark Sweep”)就可以看出它是基于“标记-清除”算法实现的。
- JVM参数:
- 通过JVM参数
-XX:+UseConcMarkSweepGC打开 -XX:+ExplicitGCInvokesConcurrent: 使System.gc()触发的Full GC改为CMS,防止过长的STW时间
- 通过JVM参数
- 特性:
- 只适用于老年代GC, 新生代可以搭配ParNew收集器;
- 特点是尽可能降低STW停顿,但是因为与用户任务一起并发进行GC,所以吞吐量下降;
- “初始标记”和”重新标记”阶段仍然Stop the World, 但耗时最长的”并发标记”和”并发清除”过程收集器线程都可以与用户线程一起”并发的”工作;
- 因为是Mark-Sweep的, GC后有内存碎片, 所以很多情况下Old Gen有足够空间但是仍会由Minor GC触发Major GC;
- 当CMS失败出现Concurrent Mode Failure会转换到Serial Old, 将导致非常长时间的Stop The World
- 实现步骤:
- 初始标记(CMS initial mark):仅仅只是标记一下GC Roots能直接关联到的对象(标记直接被GC root引用 或者 被年轻代存活对象所引用的所有对象),速度很快,需要“Stop The World”。
- 并发标记(CMS concurrent mark): 由上一阶段标记过的”可达对象”出发进行标记(遍历老年代),用户任务不停顿
- 预清理(CMS preclean): 仍旧与用户任务并行, 主要是标记由新生代晋升的对象, 预清理阶段还可能包括一个”可中断预清理”等待一次 Minor GC, 详见 [GC日志实例分析];
- 重新标记(CMS remark): 这一阶段会暂停所有用户线程,因为并发标记阶段是和用户线程并发执行的过程,所以该过程中可能有用户线程修改某些活跃对象的字段,指向了一个未标记过的对象(变为可达),这个阶段需要重新标记出此类对象,防止在下一阶段被清理掉。特别需要注意一点,这个阶段是 以新生代中对象为根 来判断对象是否存活的(CMS只做老年代的Major GC,但判断老年代对象是否被引用到需要扫描新生代对象)详见[GC日志实例分析]部分的解释。该阶段会“Stop The World”;
- 并发清除(CMS concurrent sweep):用户任务不停顿
⑤ G1回收器 : 在JDK 7u4版本被正式推出,用于逐步替换掉CMS收集器, G1适用于新生代和老年代:
- 通过参数
-XX:+UseG1GC来启用 - 特性:
- 采用标记整理(Mark-Compact)算法,不会产生内存空间碎片。
- 可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒
- 实现步骤:
- G1将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留新生代和老年代的概念,每个区域都可以充当 Eden 区、Survivor 区或者老年代的一部分。
- 建立可预测的停顿时间模型,G1跟踪各个Region里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大(死亡对象最多)的Region(这也就是Garbage-First名称的来由)。
- GC步骤: @TODO 重新整理
- 初始标记(Initial Marking) 仅仅只是标记一下GC Roots 能直接关联到的对象,并且修改TAMS(Nest Top Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可以的Region中创建对象,此阶段需要STW,但耗时很短。
- 并发标记(Concurrent Marking) 从GC Root 开始对堆中对象进行可达性分析,找到存活对象,此阶段耗时较长,但可与用户程序并发执行。
- 最终标记(Final Marking) 为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs里面,最终标记阶段需要把 Remembered Set Logs的数据合并到 Remembered Set中,这阶段需要STW。
- 筛选回收(Live Data Counting and Evacuation) 首先对各个Region中的回收价值和成本进行排序,根据用户所期望的GC 停顿是时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
⑥ ZCG: ZGC是JDK11引入的, 特点是极短的STW时间, 无论堆的大小(上T级的情况)能保证10ms以下的JVM停顿。
- 特性:
- 采用标记整理(Mark-Compact)算法
- 实现细节:
- ZGC将堆划分为Region作为清理,移动,以及并行GC线程工作分配的单位。不过G1一开始就把堆划分成固定大小的Region,而ZGC 可以有2MB,32MB,N× 2MB 三种Size Groups,动态地创建和销毁Region,动态地决定Region的大小。所以ZGC能更好的处理大对象的分配。
- ZGC的堆没有分代
- 与标记对象的传统算法相比,ZGC在指针上做标记,在访问指针时加入Load Barrier(读屏障),比如当对象正被GC移动,指针上的颜色就会不对,这个屏障就会先把指针更新为有效地址再返回,也就是,永远只有单个对象读取时有概率被减速,而不存在为了保持应用与GC一致而粗暴整体的Stop The World。
- GC步骤:
- Pause Mark Start -初始停顿标记
- Concurrent Mark -并发标记
- Relocate - 移动对象: 将被标记的对象(仍在使用的)移动到新的Region
- Remap - 修正指针
下图是SPECjbb 2015基准测试,在128G的大堆下,最大停顿时间只有 1.68ms, 相比之下Parallel和G1都超过了200ms, 最坏高达800ms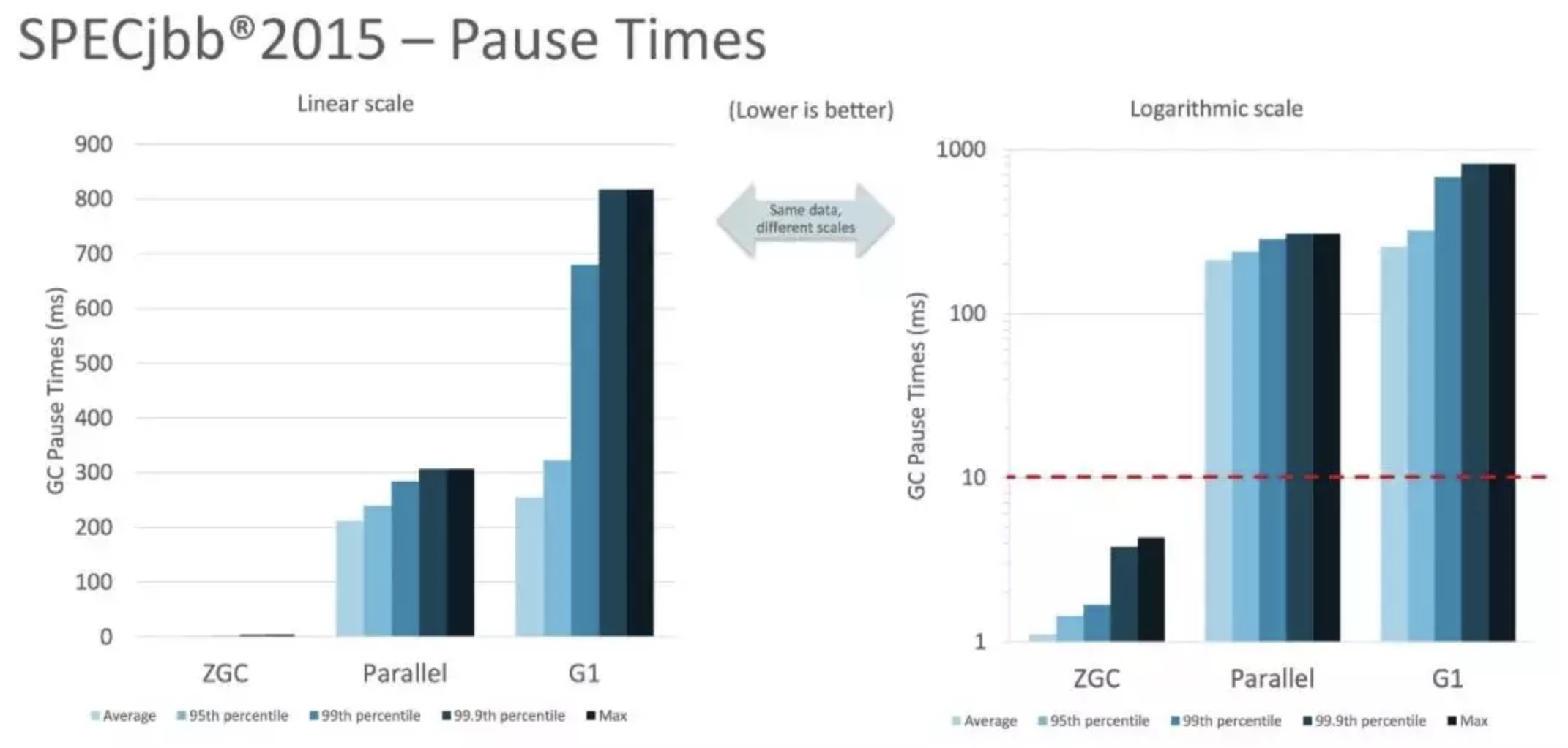
参考: 一文读懂Java 11的ZGC为何如此高效 - CSDN博客 @Ref
GC优化
GC策略的评价指标
- 吞吐量: 系统的生命周期内,应用程序所花费的时间和系统总运行时间的比值。系统总运行时间 = 应用程序耗时 + 总GC耗时。
如果系统运行了100分钟,全部GC耗时1分钟,则系统吞吐量=99% - 停顿时间: 是否需要STW,以及STW耗时多少
- 垃圾回收频率: 一般而言,频率越低越好,通常增大堆空间可以有效降低垃圾回收发生的频率,但是会增加回收时产生的停顿时间。
- 反应时间: 当一个对象成为垃圾后,多长时间内,它所占用的内存空间会被释放掉。
给出一些经验性的参考值:
- Young CG发生频率很高, 可能几秒一次, 每次YGC的STW耗时很短, 可能不超过10ms;
- Major GC 正常情况大约1-2次/天, 如果几小时就出现一次 Major GC属于不正常,
- Full GC尽量杜绝
一些参考案例:
- 探索StringTable提升YGC性能 - 简书
- StringTable 过大导致的YGC时间过长 // String Table在Young Gen ?
- 如何降低young gc时间
- Hystrix信号量+RPC异步化, 减少线程池数目, 降低YGC
- 从实际案例聊聊Java应用的GC优化
- 案例1: 优化TP99、TP90时间
- 案例2: 优化耗时波动
- 案例3: 避免Full GC
- 25ms GC的影响有多大
- Garbage Collection Optimization for High-Throughput and Low-Latency Java Applications | LinkedIn Engineering
GC日志解读
GC日志相关参数:-XX:+PrintGC 输出GC日志
-XX:+PrintGCDetails 输出GC的详细日志
-XX:+PrintGCTimeStamps 输出GC的时间戳(以基准时间的形式)
-XX:+PrintGCDateStamps 输出GC的时间戳(以日期的形式,如 2013-05-04T21:53:59.234+0800)
-XX:+PrintHeapAtGC 在进行GC的前后打印出堆的信息
-Xloggc:../logs/gc.log 日志文件的输出路径
一般GC日志格式
图1: Young GC日志格式解释如下(ParallelGC):

图2: Full GC日志格式解释如下(ParallelGC):
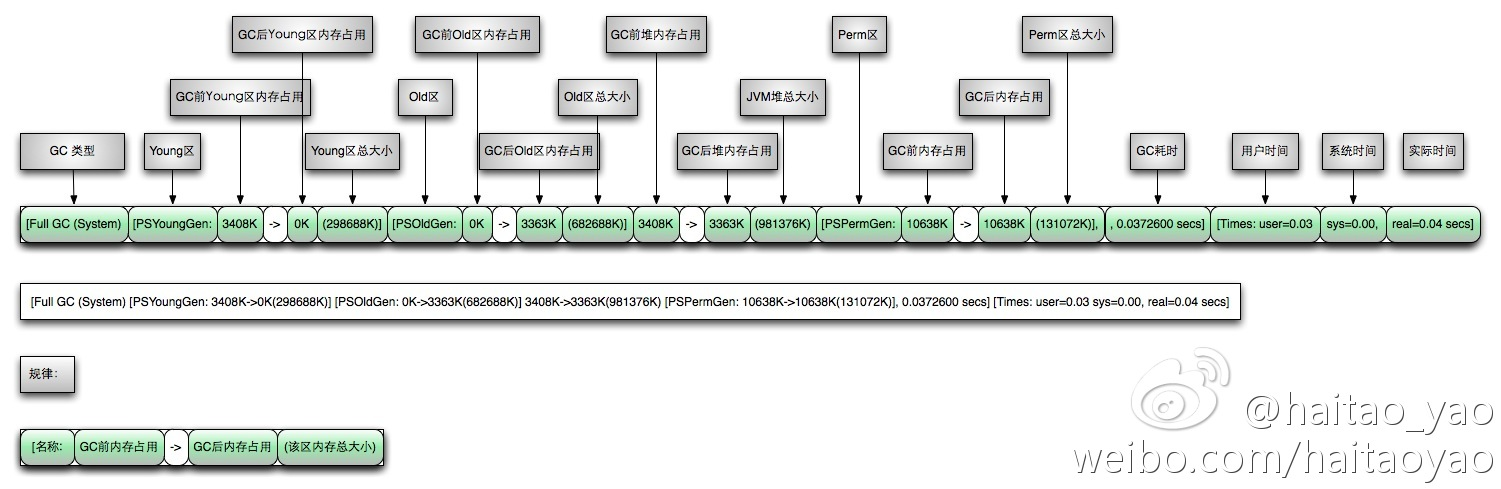
GC日志实例分析
Serial收集器
一次YGC和Full GC:
33.125: [GC [DefNew: 3324K->152K(3712K), 0.0025925 secs] 3324K->152K(11904K), 0.0031680 secs] |
ParNew + CMS收集器
正常的CMS GC日志, 可以看到CMS标记的三个阶段:
# 初始标记, STW |
阶段1:Initial Mark, 这个是 CMS 两次 stop-the-wolrd 事件的其中一次,这个阶段的目标是:标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象,
40.146: [GC [1 CMS-initial-mark: 26386K(786432K)] 26404K(1048384K), 0.0074495 secs]
阶段2:并发标记, 在这个阶段 Garbage Collector 会根据上个阶段找到的 GC Roots 遍历查找,标记所有存活的对象。这一阶段,Garbage Collector 与用户的应用程序并发运行。
40.683: [CMS-concurrent-mark: 0.521/0.529 secs]
阶段3:Concurrent Preclean, 这也是一个并发阶段,与应用的线程并发运行,不会 stop-the-wolrd 。这一阶段会查找前一阶段中从新生代晋升或者有更新的对象。这一阶段可以减少 stop-the-world 的remark阶段的工作量
40.701: [CMS-concurrent-preclean: 0.017/0.018 secs]
阶段4:Concurrent Abortable Preclean (可中断的预清理) 这也是一个并发阶段,同样不会不会 stop-the-wolrd 。该阶段主要工作仍然是并发标记对象是否存活,只是这个过程可被中断。此阶段在 Eden区使用超过2M时启动,当然 2M是默认的阈值,可以通过参数修改。如果此阶段执行时等到了 Minor GC,或者等了超过
CMSMaxAbortablePrecleanTime的时间(默认5s)都没有发生 Minor GC,则会进入下一阶段 – Remark。// 该阶段尽量等一次Minor GC来减少新生代对象数量,减少remark阶段需要扫描新生代对象的数量,减少remark阶段 STW耗时。 通过CMSScavengeBeforeRemark参数,可以在这一阶段强制进行一次Minor GC。15581.905: [CMS-concurrent-abortable-preclean: 3.506/3.514 secs] [Times: user=11.93 sys=6.77, real=3.51 secs]
阶段5:Remark, 这是第二个 STW 阶段,暂停所有用户线程,从GC Root开始重新扫描整堆,标记存活的对象。需要注意的是,虽然CMS只回收老年代的垃圾对象,但是这个阶段依然需要扫描新生代,因为很多GC Root都在新生代,而这些GC Root指向的对象又在老年代,这称为“跨代引用”。
15582.032: [weak refs processing, 0.0027800 secs]15582.035: [class unloading, 0.0033120 secs]15582.038: [scrub symbol table, 0.0016780 secs]15582.040: [scrub string table, 0.0004780 secs] [1 CMS-remark: 6299829K(20971520K)] 6348225K(24746432K), 0.1365130 secs] [Times: user=1.24 sys=0.00, real=0.14 secs]
阶段6:Concurrent Sweep,并发清理,不需要 STW,需要注意的: 因为CMS是 Mark-Sweep算法, 仍会存在内存碎片。
15590.327: [CMS-concurrent-sweep: 8.193/8.284 secs] [Times: user=30.34 sys=16.44, real=8.28 secs]
@Ref 参考: JVM 之 ParNew 和 CMS 日志分析
有GC问题的日志例子:
106.641: [GC 106.641: [ParNew (promotion failed): 14784K->14784K(14784K), 0.0370328 secs]106.678: [CMS106.715: [CMS-concurrent-mark: 0.065/0.103 secs] [Times: user=0.17 sys=0.00, real=0.11 secs] |
上面是因为执行 ParNew GC的时候, 因为需要晋升至老年代的对象超过了老年代的可用大小, 所以 promotion failed, 而触发了 Full GC,
还存在一种情况, 老年代大小足够的情况下仍然会触发 promotion failed, 可以通过 -XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5 参数, 在5次 Full GC后进行一次 Compaction操作避免内存碎片.
总结 CMS GC常见的两种错误解决方案:
- promotion failed
解决办法:-XX:UseCMSCompactAtFullCollection -XX:CMSFullGCBeforeCompaction=5或者 调大新生代或S0/S1空间; - concurrent mode failure
解决办法: 或增加老年带的空间, 或者调节+XX:CMSInitiatingOccupancyFraction=70使老年代使用更高比例(这里是70%)后才开始CMS GC;
GC引起的Error
什么代码会导致GC引起的内存错误: OutOfMemoryError:Java Heap, OutOfMemoryError:PermGen, OutOfMemoryError:Matespace, OutOfMemoryError: Direct buffer memory ? (以及堆栈错误StackOverflowError)
- Java虚拟机栈和本地方法栈: 在JVM规范中,对Java虚拟机栈规定了两种异常:
- 如果线程请求的栈大于所分配的栈大小,则抛出 StackOverFlowError错误,比如进行了一个不会停止的递归调用;
- 如果虚拟机栈是可以动态拓展的,拓展时无法申请到足够的内存,则抛出 OutOfMemoryError错误。
- 堆内存: OutOfMemoryError
- 直接内存: 在JDK1.4中引入的NIO使用Native函数库在堆外内存上直接分配内存,但直接内存不足时,也会导致OOM。
- 方法区: 随着Metaspace元数据区的引入,方法区的OOM错误信息也变成了 “java.lang.OutOfMemoryError:Metaspace”。
对于旧版本的Oracle JDK,由于永久代的大小有限,而JVM对永久代的垃圾回收并不积极,如果往永久代不断写入数据,例如String.Intern()的调用,在永久代占用太多空间导致内存不足,也会出现OOM的问题,对应的错误信为 “java.lang.OutOfMemoryError:PermGen space”
引用类型(Reference)
- 强引用: 只要强引用还在就不会被 GC,JVM宁愿抛出 OutOfMemoryError错误也不会回收;
- 软引用(SoftReference): 用来描述非必需对象, GC时发现内存不够时(Heap内存超阈值)将会被回收。当垃圾回收器决定对其回收时,会先清空它的 SoftReference,也就是说 SoftReference 的
get()方法将会返回 null,然后再调用对象的finalize()方法,并在下一轮 GC 中对其真正进行回收。 - 弱引用(WeakReference): 也是用来描述非需对象的, 无论内存够不够,下次GC时一定都被回收;
- 虚引用(PhantomReference): PhantomReference的get方法永远返回null,为一个对象设置虚引用关联的唯一目的是跟踪对象被垃圾回收的状态,通过查看引用队列中是否包含对象所对应的虚引用来判断它是否即将被垃圾回收,当
PhantomReference被放入队列时,说明referent的finalize()方法已经调用,并且垃圾收集器准备回收它的内存了。 - FinalReference 以及 Finzlizer:@TODO
How to Use:
ReferenceQueue<String> queue = new ReferenceQueue<>(); // 对象被回收后, 被放入q里 |
WeakReference内部如何实现:
WeakHashMap
How to Use:
public static void weakHashMapTest() { |
WeakHashMap 自动回收的特性可以作为缓存来用, 例如 tomcat的ConcurrentCache
源码解析:
WeakHashMap 的主要属性:public class WeakHashMap<K,V>
extends AbstractMap<K,V> implements Map<K,V> {
// 桶数组
Entry<K,V>[] table;
// 回收队列
private final ReferenceQueue<Object> queue = new ReferenceQueue<>();
}
同时, WeakHashMap 的内部类Entry(也就是实际存储数据的节点)继承自WeakReference<T>,看一下Entry的构造:
Entry(Object key, V value, |
调用WeakHashMap 的 put(k,v), 首先创建Entry对象, Entry构造里首先调用了WeakReference(K, Queue),
用一个WeakReference指向key,key会在下次GC被回收(null),value被一个强引用指向了,不会被回收,可以通过queue.poll取出所有被释放的Key,
A: 那么WeakHashMap 是如何回收value的?
Q: 在get, put, size 方法里都会先调用一个expungeStaleEntries()方法,
遍历ReferenceQueue 取出每个Entry(即被回收的Key), 找到Entry 对应的table[i],table[i]是 Entry组成的链表(当hash冲突的时候), 遍历这个链表, 取出每一个Entry, 如果ReferenceQueue 取出的那个Entry,
把这个 Entry.value置为null, 帮助回收;
private void expungeStaleEntries() { |
// 疑问, 只有Key是WeakReference, GC发生时, 应该只有Key 被放入ReferenceQueue, 而不是Entry对象
// 解释, queue 里存储的是 Reference<K> 类型, 而Entry 是Reference的子类, 所以可以转换
// WeakHashMap中关于queue的疑惑 ? - 知乎
JVM参数和性能
JVM的模式
- 使用
java -version命令查看出当前虚拟机处于哪种类型模式: Server or Client - JVM启动时采用何种模式是在名为jvm.cfg的配置文件中配置的:
- 在32位JDK中,jvm.cfg位置为:JAVA_HOME/jre/lib/i386/jvm.cfg
- 在64位JDK中,jvm.cfg位置为:JAVA_HOME/jre/lib/amd64/jvm.cfg
Server 和 Client 的区别:
These two systems are different binaries. They are essentially two different compilers (JITs)interfacing to the same runtime system. The client system is optimal for applications which need fast startup times or small footprints, the server system is optimal for applications where the overall performance is most important. In general the client system is better suited for interactive applications such as GUIs. Some of the other differences include the compilation policy,heap defaults, and inlining policy.
Client JVM适合需要快速启动和较小内存空间的应用,它适合交互性的应用,比如GUI;而Server JVM则是看重执行效率的应用的最佳选择。不同之处包括:编译策略、默认堆大小、内嵌策略。使用
java -X可以看到Jvm工作模式 // JVM有以下几种模式:-Xint, -Xcomp, 和 -Xmixed- -Xint代表解释模式(interpreted mode),-Xint标记会强制JVM以解释方式执行所有的字节码
- -Xcomp代表编译模式(compiled mode),与它(-Xint)正好相反,JVM在第一次使用时会把所有的字节码编译成本地代码,从而带来最大程度的优化
- -Xmixed代表混合模式(mixed mode),前面也提到了,混合模式是JVM的默认工作模式。它会同时使用编译模式和解释模式。对于字节码中多次被调用的部分,JVM会将其编译成本地代码以提高执行效率;而被调用很少(甚至只有一次)的方法在解释模式下会继续执行,从而减少编译和优化成本
JVM相关日志
-XX:+HeapDumpOnOutOfMemoryError XX:HeapDumpPath=../开启jvm内存不足时生成dump文件, 指定位置-XX:ErrorFile=/var/log/hs_err_pid.logjvm崩溃日志-XX:+PrintGC -XX:+PrintGCDateStamps -Xloggc:../logs/gc.log开启GC日志, 输出时间戳, 指定GC日志位置
JVM参数: -D -X -XX
查看当前JVM默认参数的命令: java -XX:+PrintFlagsFinal -version, 下面是需要注意的参数说明:
-D参数:
- -D: JVM系统参数, 可以自定义, 在代码里通过
System.getProperty("xxx")获取到-Djava.ext.dirs=/path:-classpath参数只能指定jar包, 如果需要把某个目录的jar都包含进来, 可以使用-Djava.ext.dir=-Dfile.encoding=UTF-8:-Djava.io.tmpdir=/tmp: 在此路径下生成pid文件, jps命令读取此文件返回结果, 默认是/tmp/hsperfdata_<username>/目录下
-X参数:
- -X: 设置JVM扩展参数, 非标准的, 不保证任何JVM都实现
-Xms512m: 堆的初始化大小,默认物理内存的1/64(<1GB),-Xmx512m: 最大堆大小,物理内存的1/4(<1GB)-Xss1m: 线程栈大小, JDK5.0以后每个线程堆栈大小为1M
-XX参数:
-XX: 不稳定的参数, 不推荐在生产环境中使用:
-XX:AutoBoxCacheMax: JAVA进程启动的时候,会加载rt.jar这个核心包的,rt.jar包里的Integer自然也是被加载到JVM中, VM在加载Integer这个类时,会优先加载静态的代码。当JVM进程启动完毕后, -128 ~ +127 范围的数字会被缓存起来,调用valueOf方法的时候,如果是这个范围内的数字,则直接从缓存取出。
因此可以根据实际情况把AutoBoxCacheMax的值设置的更多一些: -XX:AutoBoxCacheMax=2000-XX:+AlwaysPreTouch: JAVA进程启动的时候,虽然我们可以为JVM指定合适的内存大小,但是这些内存操作系统并没有真正的分配给JVM,而是等JVM访问这些内存的时候,才真正分配.
这个参数可以让让操作系统在启动JVM时, 把内存真正的分配给JVM;-XX:CMSInitiatingOccupancyFraction: 当老年代堆空间的使用率达到75%的时候就开始执行垃圾回收, CMSInitiatingOccupancyFraction默认值是92%,这个就太大了
如-XX:CMSInitiatingOccupancyFraction=75, 注意CMSInitiatingOccupancyFraction参数必须跟下面两个参数一起使用才能生效:-XX:+UseConcMarkSweepGC
-XX:+UseCMSInitiatingOccupancyOnly-XX:MaxTenuringThreshold默认情况下, 这个值是15, 意思是 当新生代执行了15次 young gc后, 如果还有对象存活在Survivor区中,那么就可以直接将这些对象晋升到老年代.
但是由于新生代使用copy算法,如果 Survivor区存活的对象太久的话, Survivor区存活的对象就越多, 这个就会影响copy算法的性能,使得 young gc停顿的时间加长,建议设置成6。
有个例外的情况, 可能导致GC收集器 不按照MaxTenuringThreshold的值进行晋升,
[动态年龄计算] :JVM遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了survivor区的一半时,取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。例如age=2的所有对象占用了超过一半Survivor区大小, 那么晋升至老年代的age阈值会调整为2-XX:ExplicitGCInvokesConcurrent如果系统使用堆外内存,比如用到了Netty的DirectByteBuffer类,那么当想回收堆外内存的时候,需要调用System.gc(), 而这个方法将进行full gc,整个应用将会停顿,
如果是使用CMS垃圾收集器,那么可以设置-XX:+ExplicitGCInvokesConcurrent, 来改变System.gc()的行为,让其从 full gc 变为 CMS GC,
CMS GC 是并发收集的,且中间执行的过程中,只有部分阶段需要 STW;-XX:PermSize: 设置持久代(perm gen)初始值 物理内存的1/64, 例XX:PermSize=512M-XX:MaxPermSize设置持久代最大值 物理内存的1/4-XX:SurvivorRatio: Eden和Survivor的大小比例,-XX:SurvivorRatio=8表示Eden:Survivor=8:1,这是默认值-XX:NewRatio: 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代),-XX:NewRatio=2表示老年代:年轻代=2:1, 这也是Server JVM的默认值;
如果Young GC很频繁, 可以降低老年代的比例:-XX:NewRatio=1;-XX:MaxTenuringThreshold: 控制进入老年前生存次数等, 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率, 该参数只有在串行GC时才有效.-XX:+DisableExplicitGC: 关闭System.gc() 这个参数需要严格的测试-XX:+UseParallelGC: 选择垃圾收集器为并行收集器.此配置仅对年轻代有效-XX:+UseParNewGC: 设置年轻代为并行收集-XX:+UseParallelOldGC: 老年代垃圾收集方式为并行收集(Parallel Compacting)-XX:+UseConcMarkSweepGC: 使用CMS内存收集-XX:+PrintGC-XX:+PrintGCDetails-XX:+PrintGC:PrintGCTimeStamps-XX:+HeapDumpOnOutOfMemoryError: 当JVM因内存不足崩溃时产生dump文件-XX:ErrorFile=/var/log/hs_err_pid.log: JVM崩溃, 产生的日志位置
JVM参数最佳实践
-Xmx4g -Xms4g -Xmn1G |
JVM分析工具
包括 jps, jstat, jstack, jmap, JProfiler, VisualVM.
JDK提供的命令行
以下每个工具都可以
cmd --help的方式查看说明
jps
查看当前用户启动jvm进程
jps -m: 显示传递给Main方法的参数jps -l: 显示Java进程的完整包名jps -v: 显示JVM的参数jps -lvm
jvm启动后会在
/tmp/hsperfdata_<username>/目录下生成一个pid为名的文件, 这个目录由-Djava.io.tmpdir参数指定, 如果因为某些原因这个文件没有生成, jps也就不起作用
文件内容:?
jstat
查看每个分代的使用率和GC次数,在没有GUI图形的服务器上是运行期定位虚拟机性能问题的首选。
注意jstat返回只有 YGC和 FGC,并不区分 Major GC和 Full GC;
jstat和-XX:+PrintGCDetails提供的结果有不同,在于:
jstat无法统计并行的任务,比如UseConcMarkSweepGC情况下,初始mark和remark阶段都会有 Stop the World的耗时,jstat的输出会把两个STW阶段视作两次 Full GC;
而在GC日志里可以清楚的看到 UseConcMarkSweepGC情况下,每个阶段的耗时。
例如, 如果配置了CMS垃圾回收器,那么 jstat中的 FGC增加1并不表示就一定发生了 Full GC,很有可能是发生了老年代的 CMS GC,而且每发生一次老年代的 CMS GC,jstat中的 FGC就会+2
常用jstat命令:
jstat -gc pid: 统计JVM内存(Young/Old/Method)的已使用/总空间大小,以及Young GC和Full GC发生次数和耗时;jstat -gcutil pid: 统计JVM内存(Young/Old/Method)的占用百分比,以及Young GC和Full GC发生次数和耗时;jstat -class pid: 类装载、卸载数量、总空间, 及类装载所耗费的时间jstat -gccapacity pid: 查看三代(young,old,perm)对象的使用量大小(字节)jstat -gcnew pid: 年轻代的容量和GC情况jstat -gcnewcapacity pid:jstat -gcold pid: 老年代的容量和GC情况jstat -gcoldcapacity pid:
如果用jstat查看远程机器上的jvm, 需要在远程主机启动jstatd(详见 jstatd)
jstat -gc pid@remote_IP # 用jstat连接远端的jstatd
jstat -gc返回列解析
示例1: attaches 到pid=14542的进程上, -h3表示每三行打印一次列名称, 采样间隔5sjstat -gc -h3 14542 5s
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
10240.0 10752.0 0.0 0.0 133120.0 10215.4 87552.0 9225.3 27904.0 26661.4 3328.0 3007.2 20 0.305 13 1.410 1.715
10240.0 10752.0 0.0 0.0 133120.0 10659.2 87552.0 9225.3 27904.0 26661.4 3328.0 3007.2 20 0.305 13 1.410 1.715
10240.0 10752.0 0.0 0.0 133120.0 10659.2 87552.0 9225.3 27904.0 26661.4 3328.0 3007.2 20 0.305 13 1.410 1.715
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
10240.0 512.0 0.0 0.0 133120.0 79.2 87552.0 9224.0 27904.0 26662.1 3328.0 3007.2 21 0.318 14 1.522 1.840
10240.0 512.0 0.0 0.0 133120.0 523.0 87552.0 9224.0 27904.0 26662.1 3328.0 3007.2 21 0.318 14 1.522 1.840
10240.0 512.0 0.0 0.0 133120.0 523.0 87552.0 9224.0 27904.0 26662.1 3328.0 3007.2 21 0.318 14 1.522 1.840
每列说明如下:
- S0C: S0 Capacity(KB)
- S0U: S0 Utilization(KB)
- EC: Current eden space capacity (kB).
- EU: Eden space utilization (kB).
- MC: Metaspace capacity (kB).
- MU: Metacspace utilization (kB).
- YGC: 从JVM进程启动到当前采样,发生young gen GC总次数
- YGCT: 从JVM进程启动到当前采样,young gen GC总消耗时间(秒), 相邻两次相减就是该次耗时
- FGC: 从JVM进程启动到当前采样,发生full GC总次数
- FGCT: 从JVM进程启动到当前采样,full GC总消耗时间(秒), 相邻两次相减就是该次耗时
注: 上面是java 1.8的jstat的返回值, 可以看到有Metaspace(元空间), 如果是java 1.7或更老版本, 则没有MC/MU, 而是PC/PU:
- PC:Perm Capacity(KB)
- PU: Perm Utilization(KB)
jstat -gcutil返回列解析
示例2: attaches 到pid=14542的进程上, -h3表示每三行打印一次列名称, 采样间隔250msjstat -gcutil -h3 14542 3s
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
16.35 0.00 94.62 63.31 97.41 94.84 4522 83.661 32 0.931 84.592
16.35 0.00 95.52 63.31 97.41 94.84 4522 83.661 32 0.931 84.592
16.35 0.00 96.92 63.31 97.41 94.84 4522 83.661 32 0.931 84.592
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 14.90 1.43 63.31 97.41 94.84 4523 83.678 32 0.931 84.609
0.00 14.90 2.65 63.31 97.41 94.84 4523 83.678 32 0.931 84.609
0.00 14.90 3.68 63.31 97.41 94.84 4523 83.678 32 0.931 84.609
上面发生了一次Young GC, S0从16.35%降到0%, S1从0%增长到14.90%, Eden从96.92%降到1.43, 耗时0.017s
以上参考Oracle Java 8 jstat手册:
jstat
jstatd
jstatd是一个RMI的server,它可以监控Hotspot的JVM的启动和结束,同时提供接口可以让远程机器连接到JVM。 比如 jstat / JVisualVM 都可以通过jstatd来远程观察JVM的运行情况。
在远程服务器上启动jstatd: nohup jstatd -J-Djava.security.policy=/home/xxx/jstatd.all.policy -J-Djava.rmi.server.hostname=192.168.0.2 -p 1099 & , 1099是jstatd的默认端口
jstatd.all.policy内容如下:grant codebase "file:${java.home}/../lib/tools.jar" {
permission java.security.AllPermission;
};
jstack
查看jvm进程的线程状态, 也可以做线程的dump,jstack pid : 查看当前所有线程的运行栈, 包括线程当前状态(blocked, waitting), 线程占用了哪个对象锁, 线程在等待哪个对象锁;
jmap
查看堆内存的情况, 也可以生成堆内存的dump信息,
jmap dump会触发Full GC, 所以在生产环境要小心使用.
jmap -heap pid: 打印Heap(新生代/老年代/永久代等等..)的size参数和实际占用jmap -histo pid: 打印出每个类的对象数量, 以及占用内存。如果出现jvm堆占用率过高,可以用histo查看哪个类的对象最多,猜测出哪里的代码有问题jmap -histo:live pid: 只打印存活的jmap -dump:format=b,file=FileName 6900: 把内存详细使用情况dump到文件(小心, 这个命令可能会暂停当前应用)-dump:[live,]format=b,file=FileName: live指只有活动的对象被转储到dump文件
如果程序内存不足或者频繁GC,很有可能存在内存泄露情况:
- 可以先使用
jmap -heap命令查看堆的使用情况,看一下各个堆空间的占用情况。- 使用
jmap -histo:[live]查看堆内存中的对象的情况。如果有大量对象在持续被引用,并没有被释放掉,那就产生了内存泄露,就要结合代码,为什么没有被释放- 也可以使用
jmap -dump:format=b,file=<fileName>命令将堆信息保存到一个文件中,再借助jhat命令查看详细内容- 在内存出现泄露、溢出或者其它前提条件下,建议多dump几次内存,把内存文件进行编号归档,便于后续内存整理分析。
图-使用jmap -histo pid 按类型统计存活类的个数: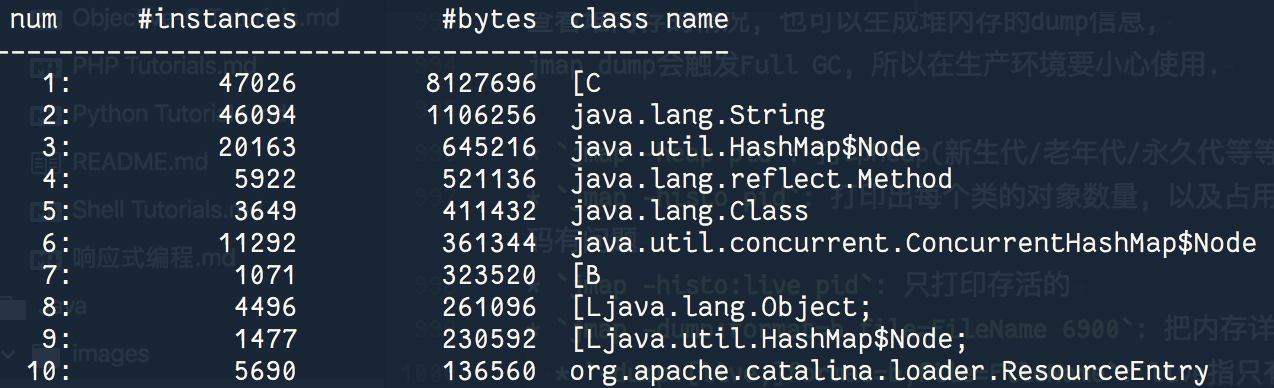
jhat
查看jmap转储的二进制文件
jhat -port 5000 FileName: 在本地启动http服务显示jmap生成的dump文件信息, 在http://localhost:5000 查看
总结:对Jvm进程进行堆栈Dump的方法
jstack可以生成Jvm线程的堆栈dump文件, jmap可以生成堆栈的dump文件,
让虚拟机在内存不足时自动生成dump文件:-XX:+HeapDumpOnOutOfMemoryError
图形化的dump生成工具: Java VisualVM
jcmd
1.7之后新增, 有多种功能的命令集合, 命令格式: jcmd $PID $Command, 查看可用的Command: jcmd $PID help, “Oracle官方建议使用jcmd代替jmap”
jcmd -l: 类似jps -mjcmd pid Thread.print: 打印当前堆栈jcmd pid GC.heap_dump /tmp/dumpFile: 导出dump文件jcmd pid VM.system_properties: 打印出该进程所有-D参数
jinfo
jinfo pid, 获取jvm进程的所有参数, 后续版本可能会移除这个工具
jdb
- 被调试的java进程启动参数
-Xdebug -Xrunjdwp:transport=dt_socket,address=8787 - 连接到上面的进程进行debug:
jdb -attach 192.168.1.79:8787 -sourcepath .
JConsole
Java 5提供的JConsole
JProfiler
JProfiler是由ej-technologies GmbH开发的商业授权的性能分析工具.
参考: 深入浅出JProfiler-博客-云栖社区-阿里云 @Ref
VisualVM
VisualVM 是一个性能分析工具,自从 JDK 6 Update 7 以后已经作为 Oracle JDK 的一部分,位于 JDK 根目录的 bin 文件夹下。
以下参考自: 使用 VisualVM 进行性能分析及调优 @Ref
使用VisualVM需要远程服务器上运行一个jstatd守护进程, 或者远程服务器上运行的Java Application启用了JMX, 应用程序添加如下参数来启动JMX:
-Dcom.sun.management.jmxremote=true |
JVisualVM连接到JVM线程使用了Attach API, 在本文档搜索Attach API.
启动命令: jvisualvm
Btrace
BTrace是SUN Kenai云计算开发平台下的一个开源项目,旨在为java提供安全可靠的动态跟踪分析工具。
Btrace能用来做什么?
举例, 如果要对线上运行的Java程序进行调试, 可以通过在代码里加入debug打印信息来实现, 但缺点也很明显, 需要不断地修改代码,加入System.out.println(), 还需要不断重启应用程序. 对于线上服务这是不可接受的.
Btrace可以改变上面低效的调试方式, Btrace可以使用类似AOP式的代码植入, 在我们关心的代码位置插入自定义代码, 比如:
在每个方法结束都打印耗时, 统计最耗时的方法;
在ArrayList.add里加入代码, 如果size过大则打印log, 找出超大的ArrayList;
当System.gc()被调用时, 打印出调用堆栈, 找出是哪里在调用gc;
并且最重要的是, 使用Btrace不需要重新编译项目代码, 也不需要重启进程, 所以Btrace非常适合在线上发生异常的环境上进行调试埋点.
Btrace的使用
Btrece的使用:
- 启动Java程序
- 编写Btrace代码, 用注解指定要切入的类和方法
- 用btracec编译上面的代码
- 用btrace命令把agent 动态attach到运行中的Java进程, 并由agent修改运行中Java程序的类
更多BTrace使用例子:
Btrace用到的技术介绍
Btrace使用 Java Complier API 编译切入代码,
再使用 Attach API 把agent.jar附加到目标JVM上。
并使用asm来重写被切入类的字节码(CGLIB代理也用到了asm), 再使用 Instrumentation API 在不重启程序的情况下实现对原有类的替换。
Attach API 和 Instrumentation API 都是JVM Tool Interface (JVMTI)里提供的工具类;
有关JVMTI相关的链接:http://docs.oracle.com/javase/7/docs/platform/jvmti/jvmti.html
https://github.com/jon-bell/bytecode-examples
参考:
- BTrace原理浅析
- 深入 Java 调试体系
- 第 1 部分,JPDA 体系概览
- 第 2 部分: JVMTI 和 Agent 实现
- 第 3 部分: JDWP 协议及实现
- 第 4 部分: Java 调试接口(JDI)
HouseMD
比BTrace更轻量级的Java进程运行时的诊断调式命令行工具,可以用来跟踪跟踪方法的耗时。
Memory Analyzer (MAT)
Java Heap Dump 文件(通过
jmap -dump转储的文件)分析工具,可以分析堆内存中每种对象的数量,还可以跟踪对象的引用链,排查内存泄漏问题。
- Eclipse Memory Analyzer Open Source Project | The Eclipse Foundation
- 使用 Eclipse Memory Analyzer 进行堆转储文件分析
class文件结构
class文件是一种8位字节的二进制流文件, 各个数据项按顺序紧密的从前向后排列, 相邻的项之间没有间隙, 这样可以使得class文件非常紧凑, 体积轻巧, 可以被JVM快速的加载至内存, 并且占据较少的内存空间。 我们的Java源文件, 在被编译之后, 每个类(或者接口)都单独占据一个class文件, 并且类中的所有信息都会在class文件中有相应的描述。
class文件中的每个数据项都有它的固定长度, 数据项的不同长度分别用u1,u2,u4,u8表示,长度分别是byte、short、int、long。
class文件中存在以下数据项(该图表参考自《深入Java虚拟机》):
| 类型 | 名称 | 数量 |
|---|---|---|
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
下图参考自: 《Java虚拟机原理图解》 Class文件中的常量池详解 @Ref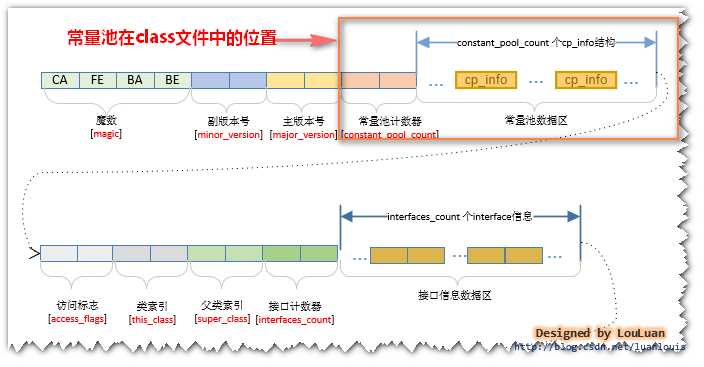
class文件每个区域的说明:
magic和version: magic也即魔数(固定值0xCAFEBABE)占用4字节, class文件版本号占用4字节, 不同版本的javac编译器编译的class文件, 版本号可能不同;- 常量池数量
constant_pool_count, class文件中的项constant_pool_count的值为1, 说明每个类都只有一个常量池。 常量池中的数据也是一项一项的, 没有间隙的依次排放。常量池中各个数据项通过索引来访问, 有点类似与数组, 只不过常量池中的第一项的索引为1, 而不为0, 如果class文件中的其他地方引用了索引为0的常量池项, 就说明它不引用任何常量池项。 - 常量池(
constant_pool)存储的内容主要包括符号引用和字面量, 常量池中除了存放了常量字符串,final常量值,还包括 符号引用(包括当前类的类名, 字段名, 方法名, 各个字段和方法的描述符, 对当前类的字段和方法的引用信息, 当前类中对其他类的引用信息等等)。
class文件中的很多其他部分都是对常量池中的数据项的引用,比如后面要讲到的this_class,super_class,field_info,attribute_info等,
另外字节码指令中也存在对常量池的引用, 这个对常量池的引用当做字节码指令的一个操作数。此外, 常量池中各个项也会相互引用。- a. 字面量: 主要包括字符串常量和final常量值;
- b. 符号引用: 包括 类继承的超类, 接口的全限定名, 及描述符(包括fields的名称和描述符, methods的名称及描述符)
- 类和接口的全限定名: 例如一个类的权限定名是
org/kshan/corej/TestClass; - 字段的名称和描述符:
- 字段名称: 当类被加载后的链接阶段, 这些符号引用被替换为直接引用;
- 字段描述符: 用来描述字段的类型比如二维数组
int [][]被记录为[[I,String[]被记录为[Ljava/lang/String;
- 方法的名称和描述符:
- 方法名称: 当类被加载后的链接阶段, 这些符号引用被替换为直接引用;
- 方法描述符: 用来描述方法的形参/返回值, 例如方法
int getIndex(String name,char[] tgc,int start,int end,char target)的描述符为(Ljava/lang/String[CIIC) I;
- 类和接口的全限定名: 例如一个类的权限定名是
access_flag, 在常量池之后的两个字节, 这个标志用于识别一些类或接口层次的访问信息this_class/super_class/interfaces: 类索引(this_class)和父类索引(super_class)都是一个 u2 类型的数据,而接口索引集合(interfaces)则是一组 u2 类型的数据集合, Class 文件中由这三项数据来确定这个类的继承关系;field_info字段表method_info方法表attribute_info属性表- 方法字节码
class文件常量池
注意不要与JVM内存模型中的”运行时常量池”混淆, Class文件中常量池主要存储了字面量以及符号引用,其中
字面量主要包括字符串,final常量的值或者某个属性的初始值等等,
符号引用主要存储类和接口的全限定名称,字段的名称以及描述符,方法的名称以及描述符,
JVM内存模型中有堆,方法区,栈,而方法区中又存在一块区域叫运行时常量池,运行时常量池中存放的其实也是各种字面量以及符号引用, 只不过运行时常量池具有动态性,它可以在运行的时候向其中增加其它的常量进去,最具代表性的就是String.intern方法。
实例分析class文件常量池
Java测试类:
public class CJEntry extends CJBaseClass implements Serializable { |
编译后使用javap分析class文件: javac org/kshan/corej/CJEntry.java && javap -v org.kshan.corej.CJEntry, 只截取输出的”Constant pool” :
#1 = Methodref #5.#23 // org/kshan/corej/CJBaseClass."<init>":()V ## 构造方法的符号引用 |
虚拟机类加载机制
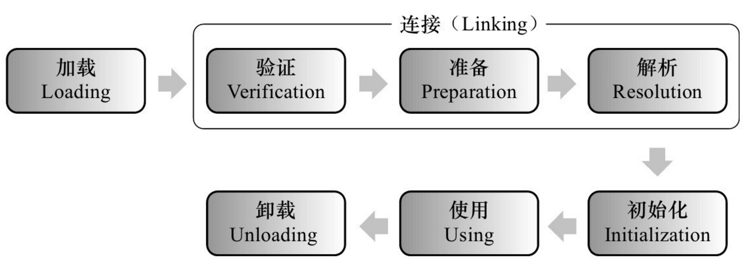
类的加载过程
加载 – 链接 – 初始化, 以上三个阶段涉及到的JVM内存区域:
- 在加载阶段, 创建的class对象存储在堆(Heap);
- 在链接阶段, final常量和字符串在方法区分配空间(jdk8变成了元空间);
- 在初始化阶段, 初始化static成员, 也在堆;
①加载(Loading)
- 由对应的ClassLoader从磁盘读取.class文件字节 // 这里的类加载器可以自定义
- 由
ClassLoader.defineClass()方法创建一个java.lang.Class的对象, 对象存储在堆(Heap),
②链接
- 验证(Verification): 验证加载类的字节码, 验证成功则载入到方法区(Method Area), 验证项包括如下:
- 变量使用前要初始化
- 方法调用与对象引用之间类型要匹配
- 访问私有数据和方法的规则没有违反
- 运行时堆栈没有溢出
- 准备(Preparation): 这一阶段在方法区(Method Area)分配
- 为类的static变量分配空间, 并赋 默认值, 比如
public static int value = 3, 这一阶段value被赋值为0, static字段的初始化要到下个”初始化”阶段才开始执行; - 为类的final常量分配空间, 赋 指定的值, 比如
public static final int value = 3, 在准备阶段虚拟机就会根据ConstantValue的设置将value赋值为3; - 除了分配内存外,部分 Java 虚拟机还会在此阶段构造其他跟类层次相关的数据结构,比如说用来实现虚方法的动态绑定的 方法表。
- 为类的static变量分配空间, 并赋 默认值, 比如
- 解析(Resolution): 把类中的符号引用转换为直接引用, 对于一个方法调用,编译器会生成一个包含目标方法所在类的名字、目标方法的名字、接收参数类型以及返回值类型的符号引用,来指代所要调用的方法。
解析阶段的目的,正是将这些符号引用解析成为实际引用。如果符号引用指向一个未被加载的类,或者未被加载类的字段或方法,那么解析将触发这个类的加载(但未必触发这个类的链接以及初始化。)
③初始化(Initialization)
主要对类变量(非final非static)进行初始化, 对于static的 Object类型(非基本类型)的成员也是在这个时候进行初始化,
这一阶段会执行< clinit > 方法,< clinit > 是编译期生成的, static代码块 ,类变量直接赋值的代码 都会被放入< clinit >, 顺序与在java代码里出现顺序一致.
Java 虚拟机会通过加锁来确保类的 < clinit > 方法仅被执行一次。
JVM 规范枚举了下述多种触发初始化的情况(但不限于这几种):
- Java虚拟机启动时, 被标明为启动类(有main方法)会被初始化
- 初始化一个类的时候如果发现其父类还没用初始化, 则先初始化其父类, 这种属于 被动初始化;
- 用 new 明确创建一个类实例, 这里用的是
new字节码指令, 当且类还没有完成初始化; - 首次对类的 static (同时必须满足非final)的成员属性进行读写, 一般是调getter/setter方法的时候, 对应字节码指令:
getstatic,putstatic - 首次调用类的 static 方法, 对应字节码指令:
invokestatic - 调用
Class.forName("xxx");
比较四种指令new, getstatic, putstatic, invokestatic:
除了
new是主动初始化, 后面三种都是被动初始化.
比较Class.forName("xxx") 和ClassLoader.loadClass():
作用都是返回Class对象;
Class.forName()只能通过应用加载器(AppClassLoader)创建Class对象, 还会调用类的static代码块;
ClassLoader.loadClass()可以通过自定义ClassLoader创建Class对象,
内部类的初始化
- 对于非静态内部类, 不允许有static成员, 也不允许有static代码块;
- 静态内部类是可以有
static{}代码块的, 我们在new Outter()的时候, 其内部类的static代码块并没有被调用到, 直到对内部类进行getstatic,invokestatic等操作的时候, 内部类的static代码块才会被调用, 才会初始化. 单例模式就用到了这个”延迟初始化”的特性.
通过内部类实现单例:
public class Singleton { |
ClassLoader @editing
JVM在加载(Loading)阶段依靠ClassLoader完成, ClassLoader的加载类过程主要使用ClassLoader.loadClass(String name)方法,
该方法中封装了中加载机制 双亲委派模式 :每当一个类加载器接收到加载请求时,它会先将请求转发给父类加载器。在父类加载器没有找到所请求的类的情况下,该类加载器才会尝试去加载。
加载完成后, 虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在方法区之中, 在JVM堆中也创建一个 java.lang.Class 类的对象.
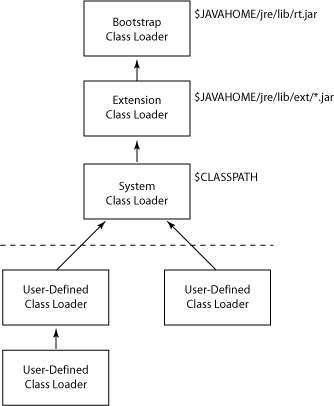
ClassLoader分类
Java 中的类加载器大致可以分成两类,一类是系统提供的”系统提供的ClassLoader”,另外一类则是由应用开发者编写的”应用程序类ClassLoader”。
- 系统类类加载器(System ClassLoader): 系统提供的类加载器主要有下面三个:
- 启动类加载器(Bootstrap ClassLoader): 它负责加载存放在JDK\jre\lib\rt.jar里
java.*开头的类; - 扩展类加载器(Extension ClassLoader): 该加载器由
sun.misc.Launcher$ExtClassLoader实现,它负责加载JDK\jre\lib\ext目录中所有类库(如javax.*开头的类),开发者可以直接使用扩展类加载器 - 系统类加载器(System ClassLoader):它根据 Java 应用的类路径(CLASSPATH)来加载 Java 类。一般来说,它加载classpath路径下的jar包和class文件。可以通过
ClassLoader.getSystemClassLoader()来获取它。
- 启动类加载器(Bootstrap ClassLoader): 它负责加载存放在JDK\jre\lib\rt.jar里
- 应用程序类加载器(Application ClassLoader): 该类加载器由
sun.misc.Launcher$AppClassLoader来实现,它负责加载用户类路径CLASSPATH所指定的类,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
每个 Java 类都维护着一个指向定义它的类加载器的引用,通过object.getClass().getClassLoader()方法就可以获取到此引用。
Class.forName() 默认了应用程序加载器(Laucher$AppClassLoader);
除了启动类加载器之外,其他的类加载器都是 java.lang.ClassLoader 的子类;
ClassLoader树状组织结构
除了 Bootstrap ClassLoader, 所有的类加载器都有一个父加载器(注意这里的”父子”关系并不是指继承关系)。通过 classLoader.getParent()方法可以得到。
- System ClassLoader的父加载器是 Extension ClassLoader,而 Extension ClassLoader的父加载器是 Bootstrap ClassLoader
- 开发者编写的 Application ClassLoader和普通Java类一样, 也需要另一个ClassLoader加载, 这个ClassLoader就是其父加载器, 一般来说,开发人员编写的类加载器的父类加载器是 System ClassLoader。
类加载器通过这种方式组织起来,形成树状结构。树的根节点就是 Bootstrap ClassLoader。
看下图, 虚线上方的三种 ClassLoader都是JDK核心类库提供的, 虚线下方是 Application ClassLoader 和 用户自定义ClassLoader;
双亲委派模式
在介绍代理模式之前,首先需要说明一下 Java 虚拟机是如何判定两个 Java 类是相同的。
Java 虚拟机不仅要看类的全名是否相同,还要看加载此类的类加载器是否一样。只有两者都相同的情况,才认为两个类是相同的。即便是同样的字节代码,被不同的类加载器加载之后所得到的类,也是不同的。
ClassLoader的加载类过程主要使用loadClass(String, boolean)方法,该方法中使用了了 双亲委派模式:
类加载器在尝试自己去查找某个类的字节代码并定义它时,会先委托父类加载器试图加载该类,只有在父类加载器无法加载该类时才尝试从自己的类路径中加载该类。
所以一个类加载的顺序是: Bootstrap, Extendsions, System, 自定义ClassLoader。
以java.lang.Object类的加载为例, 如果这个加载过程由Java应用自己的类加载器来完成的话, 很可能就存在多个版本的java.lang.Object类, 通过代理模式, 对于Java核心库的类的加载工作由引导类加载器来统一完成, 保证了 Java应用所使用的都是同一个版本的Java核心库的类
loadClass(String, boolean)方法的双亲委派模式实现如下:
- 首先,检查一下指定名称的类是否已经加载过,如果加载过了,就不需要再加载,直接返回。
- 如果此类没有加载过,那么,再判断一下是否有父加载器;如果有父加载器,则由父加载器加载(即调用
parent.loadClass(name, false);).或者是调用bootstrap类加载器来加载。 - 如果父加载器及bootstrap类加载器都没有找到指定的类,那么调用当前类加载器的
findClass()方法来完成类加载
ClassLoader API介绍
| method | desc |
|---|---|
| getParent() | 返回该类加载器的父类加载器。 |
| loadClass(String name) | 加载名称为 name的类,返回的结果是 java.lang.Class类的实例。 |
| findClass(String name) | 查找名称为 name的类,返回的结果是 java.lang.Class类的实例。 |
| findLoadedClass(String name) | 查找名称为 name的已经被加载过的类,返回的结果是 java.lang.Class类的实例。 |
| resolveClass(Class<?> c) | 链接指定的 Java 类。 |
| defineClass(String name, byte[] b, int off, int len) | 把字节数组 b中的内容转换成 Java 类,返回的结果是 java.lang.Class类的实例。这个方法被声明为 final的。 |
| getResources(String path) | 获取classpath下面的文件, path是包名路径(例如com/sina/ml), 返回的是classpath绝对路径的URL封装 |
比较loadClass 和 defineClass方法:
- 启动类的加载过程是通过调用
loadClass()来实现的,loadClass()被称为类的“初始加载器”(initiating loader),loadClass()里封装了前面提到的代理模式的实现; - 真正完成类的加载工作是通过调用
defineClass()来实现的,defineClass()被称为类的“定义加载器”(defining loader), 如果要自定义一个ClassLoader, 需要重写findClass, 最后调用defineClass; - loadClass抛出ClassNotFoundException异常;
- defineClass抛出NoClassDefFoundError异常;
实现一个ClassLoader
// 1继承CLassLoader |
显示加载和隐式加载
- 显式加载:调用
ClassLoader.loadClass(className)与Class.forName(className) - 隐式加载:
- 创建类对象
- 使用类的静态域
- 创建子类对象
- 使用子类的静态域
注意还有其他特殊的隐式加载:
- 在JVM启动时,BootStrapLoader会加载一些JVM自身运行所需的class
- 在JVM启动时,ExtClassLoader会加载指定目录下一些特殊的class
- 在JVM启动时,AppClassLoader会加载classpath路径下的class,以及main函数所在的类的class文件。
参考原文:https://blog.csdn.net/jiyiqinlovexx/article/details/51090751
类加载器与 Web 容器
对于运行在 Java EE™容器中的 Web 应用来说,类加载器的实现方式与一般的 Java 应用有所不同。不同的 Web 容器的实现方式也会有所不同。
以 Apache Tomcat 来说,每个 Web 应用都有一个对应的类加载器实例。该类加载器也使用代理模式,所不同的是它是首先尝试去加载某个类,如果找不到再代理给父类加载器。
这与一般类加载器的顺序是相反的。这是 Java Servlet 规范中的推荐做法,其目的是使得 Web 应用自己的类的优先级高于 Web 容器提供的类。
这种代理模式的一个例外是:Java 核心库的类是不在查找范围之内的。这也是为了保证 Java 核心库的类型安全。
JVM如何判断两个类是否相同
JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。
只有两者同时满足的情况下,JVM才认为这两个class是相同的。就算两个class是同一份class字节码,如果被两个不同的ClassLoader实例所加载,JVM也会认为它们是两个不同class。
比如网络上的一个Java类org.classloader.simple.NetClassLoaderSimple,javac编译之后生成字节码文件 NetClassLoaderSimple.class,
ClassLoaderA 和 ClassLoaderB 这两个类加载器并读取了 NetClassLoaderSimple.class文件,并分别定义出了java.lang.Class实例来表示这个类,对于JVM来说,它们是两个不同的实例对象,但它们确实是同一份字节码文件,如果试图将这个Class实例生成具体的对象进行转换时,就会抛运行时异常java.lang.ClassCaseException
public class NewworkClassLoaderTest { |
@uncerten 实际代码测试结果:
相同的CL类, 不同的CL实例, 创建的class实例是==的
Java对象内存模型
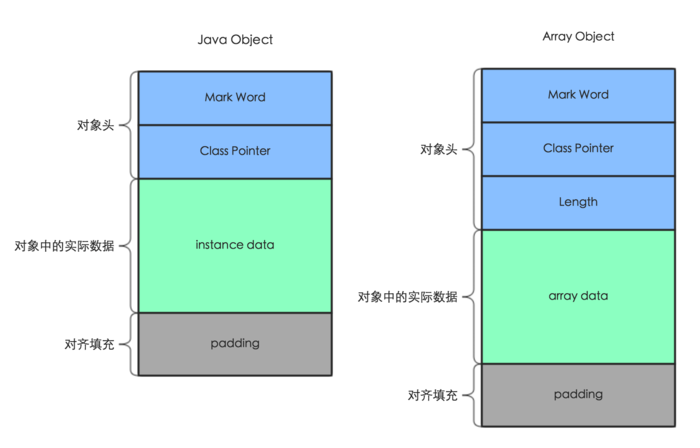
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头
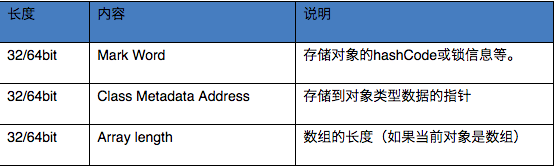
HotSpot虚拟机的对象头包括两部分信息对象头分三部分内容(如果不是数组则是两部分):
- Mark Word: 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位VM中分别为32bit和64bit;
- Class Metadata Address: klass类型指针, 用来指向对象对应的Class对象(其对应的元数据对象)的内存地址。这部分数据的长度在32位和64位VM中分别为32bit和64bit。64位开启指针压缩的情况下, 这部分占32bit;
- Array Length: 如果是数组对象,还需要有一个
Array Length保存数组长度的空间,32bit
Mark Word结构
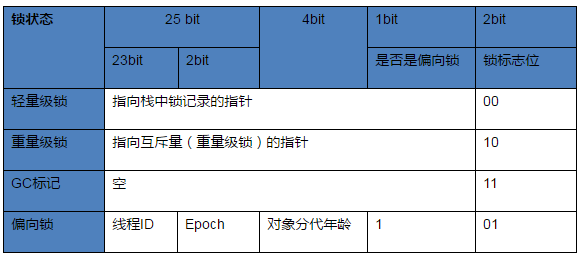
Mark Word每个区域表示的内容, 不同对象锁状态下的含义也不同:
实例数据
去掉对象头, 剩下的是实例数据(Instance Data)和对齐填充(Padding):
实例数据部分包括了对象的所有成员变量,其大小由各个成员变量的大小决定,比如:byte和boolean是1个字节,short和char是2个字节,int和float是4个字节,long和double是8个字节,reference是4个字节(64位系统中是8个字节)。
非final非static成员属性才在这里, final的常量属性在方法区; static的属性在class对象里, class对象也在堆区.
对齐填充
填充字节, 使得对象的大小是8的倍数
深入拆解Java虚拟机
注:文章来自极客时间课程,需要付费购买才可以查看完整内容。
深入理解Java内存模型
本章是《深入理解Java内存模型》的笔记, 参考链接:
参考列表:
- @Ref 深入理解Java内存模型(一)——基础
- @Ref 深入理解Java内存模型(二)——重排序
- @Ref 深入理解Java内存模型(三)——顺序一致性
- @Ref 深入理解Java内存模型(四)——volatile
- @Ref 深入理解Java内存模型(五)——锁
- @Ref 双重检查锁定与延迟初始化
@TLDR
- 并发编程模型
- 并发编程模型要解决的两个问题: 通信和同步
- 两种并发编程模型的: 基于共享内存, 基于消息
- Java内存模型的抽象
- Java内存模型(JMM)的抽象: 主内存和线程的”本地内存”
- happens-before规则
- 该规则是JSR-133内存模型(JDK层面定义的)中提出的概念, happens-before并不是指两个指令执行的先后顺序, 而是两个指令的 内存可见性. 如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
- 该规则还保证了, 哪些java代码能达到happens-before的效果:
- 单线程下顺序执行;
- 正确使用volatile, Synchronize 的情况下, 多线程也能提供happens-before效果;
- 重排序
- 为什么会产生重排序,有哪几种重排序?
- 在JMM上, 重排序必须遵守as-if-serial语义: as if serial, 「就像是顺序执行」
- 在单线程环境下, 保证a-i-s, 处理器和编译器的重排序优化,不能改变存在数据依赖关系的两个操作的执行顺序
- 在存在竞争的多线程下, 处理器和编译器不保证a-i-s, 必须正确使用lock,volatile和final 才可以.
- 内存屏障
- 内存屏障指令是cpu架构层面定义的, Java编译器会在生成字节码中插入内存屏障指令来禁止某些重排序, 保证多核环境下代码执行的”一致性”
- JMM提供了四种内存屏障, 其中最重要的是
StoreLoad屏障指令, 它能保证…
- Java如何实现多线程环境下的正确同步:
- Volatile实现了怎样的内存语义, 是如何实现的?
- Synchronize实现了怎样的内存语义, 是如何实现的?
- ReentrantLock是如何实现的? CAS具有跟Volatile读写一样的内存语义, 是如何实现的?
- concurrent包的实现 : 四种方式(CAS和volatile)
并发编程模型
在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体)。
通信 是指: 通信是指线程之间以何种机制来交换信息。在共享内存的并发模型里,对于线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
同步 是指: 程序用于控制不同线程之间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写 - 读内存中的公共状态来隐式进行通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
Java并发模型中, 线程的同步采用的是 共享内存 的方式,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的Java程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
Java内存模型的抽象
Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的 本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
本地内存 是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意图如下:
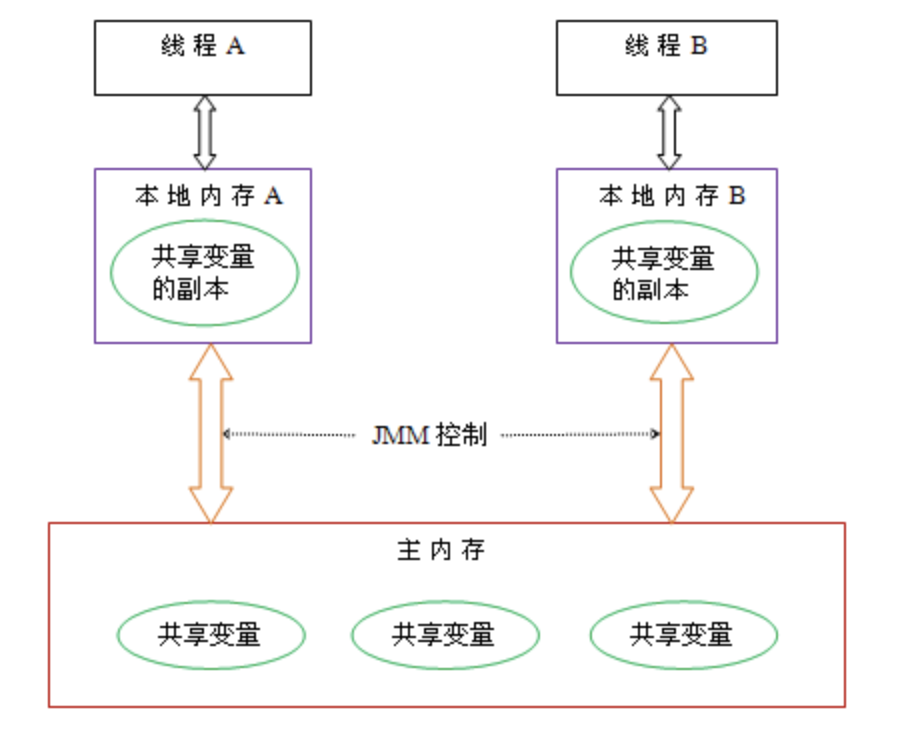
在java中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态域和数组元素)。局部变量(Local variables),方法定义参数(java语言规范称之为formal method parameters)和异常处理器参数(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
JMM的happens-before规则
从JDK5开始,java使用新的JSR-133内存模型,JSR-133提出了happens-before的概念,通过这个概念来阐述操作之间的内存可见性。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。 与程序员密切相关的happens-before规则如下:
- 顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁(Monitor)规则:对一个监视器锁的解锁,happens-before于随后对这个监视器锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- 线程启动法则:在一个线程里,对Thread.start的调用会happens-before于每个启动线程的动作。
- 线程终结法则:线程中的任何动作都happens-before于其他线程检测到这个线程已经终结、或者从Thread.join调用中成功返回,或Thread.isAlive返回false。
- 中断法则:一个线程调用另一个线程的interrupt happens-before于被中断的线程发现中断。
- 终结法则:一个对象的构造函数的结束happens-before于这个对象finalizer的开始。
如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
两个操作之间存在happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果重排序之后的执行结果与按照happens-before关系来执行的结果一致,那么这种重排序并不非法。
JMM顺序一致性
什么是“顺序一致性”内存模型:
顺序一致性模型(sequential consistency)是一个被计算机科学家理想化了的理论参考模型,顺序一致性内存模型有两大特性:
- 在单线程环境下,所有操作必须按照代码的顺序来执行。
- 多线程环境下,所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
然而,即使是顺序一致性在实际系统中也是很少使用的,主要是它严格限制了程序的优化执行,强行的使程序在本地处理器上按程序序(program order)执行在大多数情况下是没有必要的。
JMM的顺序一致性保证:
JMM提供的顺序一致性内存模型是一种”面向程序员的内存模型”(Programmer-centric model),JMM对正确同步的多线程程序的内存一致性做了如下保证:
如果程序是正确同步的(正确使用了lock,volatile和final),程序的执行将具有顺序一致性(sequentially consistent)– 即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同(这对于程序员来说是一个极强的保证)。这里的同步是指广义上的同步,包括对常用同步原语(lock,volatile 和 final)的正确使用。
重排序
什么是重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能的开发并行度。
重排序分三种类型:
- 编译器优化 的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行 的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统 的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

- 上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。
- 写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读/写操作的执行顺序,不一定与内存实际发生的读/写操作顺序一致!
遵守as-if-serial语义
as-if-serial: 翻译就是「就像是顺序执行」.
编译器和处理器对重排序准守as-if-serial语义,as-if-serial的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器/runtime/处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不能改变存在数据依赖关系的两个操作的执行顺序。比如a=b; b=1; 以及a=1; b=a;,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
编译器和处理器仅指在单线程环境下遵守as-if-serial,在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。必须通过正确的同步实现.
注意:if等控制语句没有 数据依赖性,比如代码:if(flag)
int i = r * r;
其中if和int i= r * r是控制依赖关系,但没有数据依赖性。
当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响,提高执行效率。
下面的情形是有可能发生的:处理器可以提前读取并计算r * r,然后把计算结果临时保存到一个名为 重排序缓冲(reorder buffer ROB) 的硬件缓存中。当接下来if(flag)的条件判断为真时,就把该计算结果写入变量i中。
内存屏障
编译器和处理器必须同时遵守重排规则。由于单核处理器能确保与“顺序执行”相同的一致性,所以在单核处理器上并不需要专门做什么处理,就可以保证正确的执行顺序。但在多核处理器上通常需要使用内存屏障指令来确保这种一致性。在不同的CPU架构上内存屏障的实现非常不一样。相对来说Intel CPU的强内存模型比DEC Alpha的弱复杂内存模型(缓存不仅分层了,还分区了)更简单。
内存屏障提供了两个功能。首先,它们通过确保从另一个CPU来看屏障的两边的所有指令都是正确的程序顺序,而保持程序顺序的外部可见性;其次它们可以实现内存数据可见性,确保内存数据会同步到CPU缓存子系统。
Java编译器在生成指令序列的适当位置会插入 内存屏障(Barriers) 指令来禁止特定类型的处理器重排序。以实现屏障前后指令的可见性。
JMM把内存屏障指令分为下列四类:
| 屏障类型 | example | 实现效果 |
|---|---|---|
| LoadLoad | Load1; LoadLoad; Load2; | 确保Load1数据的装载,之前于Load2及所有后续装载指令的装载。(禁止Load1,Load2重排序) |
| StoreStore | Store1; StoreStore; Store2; | 确保Store1数据对其他处理器可见(刷新到内存),之前于Store2及所有后续存储指令的存储。(禁止Store1,Store2重排序) |
| LoadStore | Load1; LoadStore; Store2; | 确保Load1数据装载,之前于Store2及所有后续的存储指令刷新到内存。(禁止Load1,Store2重排序) |
| StoreLoad | Store1; StoreLoad; Load2; | 确保Store1数据对其他处理器变得可见(刷新到内存),之前于Load2及所有后续装载指令的装载。StoreLoad Barriers会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。(禁止Store1,Load2重排序) |
StoreLoad 是一个“全能型”的屏障,它可以保证“先刷新到主内存再访问”。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
Volatile
volatile变量的特性
- 可见性:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。可以认为对volatile的写是原子的;
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于
volatile++这种”依赖当前值”的复合操作不具有原子性,所以仅仅使用volatile变量当做同步手段(比如当做锁的计数器) 是不可以的。 线程安全的计数器请使用AtomicInteger
扩展阅读: long和double读写的原子性:
JMM不保证对64位的long型和double型变量的读/写操作具有原子性,
在一些32位的处理器上,如果要求对64位数据的读/写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java语言规范鼓励但不强求JVM对64位的long型变量和double型变量的读/写具有原子性。
当JVM在这种处理器上运行时,会把一个64位long/ double型变量的读/写操作拆分为两个32位的读/写操作来执行。这两个32位的读/写操作可能会被分配到不同的总线事务中执行,此时对这个64位变量的读/写将不具有原子性。
volatile读写建立的happens before关系
从JSR-133开始,volatile变量的写-读可以实现线程之间的通信。看代码:
class VolatileExample { |
- 根据happens-before①,1 happens-before 2,3 happens-before 4;
- 根据volatile语义,2 happens-before 3;
- 根据happens-before④,1 happens-before 4;
上面写1 happens-before 2,指的是1对于2可见,但不一定是执行顺序;
volatile读写的内存语义
volatile读写的内存语义如下:
- 当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
“内存语义”的概念:
内存语义(没找到对应的英文原语): 可以理解为 多核环境下, “同步”(在Java里指Volatile,Synchronize等)实现的原则, 或者是”能达到的效果”.
volatile内存语义的实现
下面是 JMM 针对编译器制定的 volatile 重排序规则表: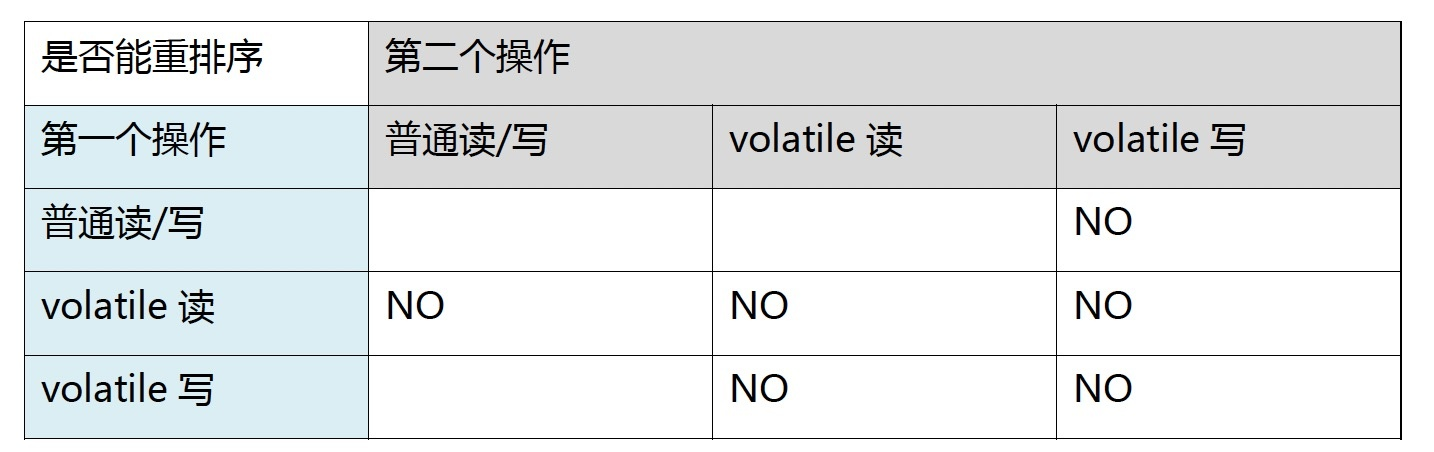
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能,为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略:
- 在每个 volatile写 操作的 前面 插入一个
StoreStore屏障。 - 在每个 volatile写 操作的 后面 插入一个
StoreLoad屏障。 - 在每个 volatile读 操作的 后面 插入一个
LoadLoad屏障。 - 在每个 volatile读 操作的 后面 插入一个
LoadStore屏障。
① volatile写 插入的内存屏障:普通读/写操作
StoreStore屏障 //禁止上面的普通写和下面的 Volatile写 重排序
volatile写
StoreLoad屏障 //禁止上面的Volatile写和下面有可能的 Volatile读写 重排序
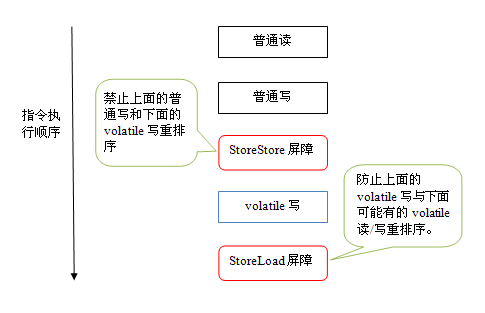
② volatile读 插入的内存屏障:volatile读
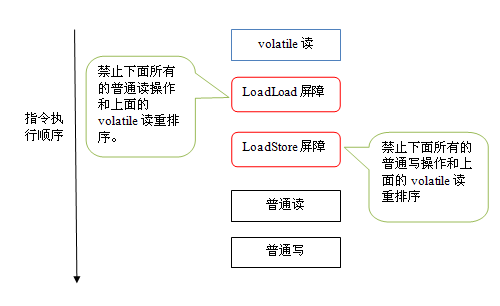
LoadLoad屏障 // 禁止下面的普通读和上面的 Volatile读 重排序
LoadStore屏障 // 禁止下面的普通写和上面的 Volatile读 重排序
普通读/写
Synchronized
有关Synchronized的实现, 请参考👉《Java Tutorials》
Synchronized的释放-获取建立的happens before关系
线程A在释放锁之前所有可见的共享变量,在线程B获取同一个锁之后,将立刻变得对B线程可见。
Synchronized释放-获取的内存语义
- 当线程释放锁时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存中。
- 当线程获取锁时,JMM会把该线程对应的本地内存置为无效。从而使得被monitor保护的临界区代码必须要从主内存中去读取共享变量。
- 对比锁释放-获取的内存语义与volatile写-读的内存语义,可以看出:锁释放与volatile写有相同的内存语义;锁获取与volatile读有相同的内存语义。
Synchronized内存语义的实现
Synchronized提供的Monitor机制可以保证:临界区内的代码可以重排序,但不允许临界区内的代码“逸出”到临界区之外。
JMM会在退出Monitor和进入Monitor这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图。虽然线程在临界区内可以做重排序,但其他线程根本无法“观察”到该线程在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
ReentrantLock
ReentrantLock实现的happens-before关系和内存语义与Synchronized的一样。
ReentrantLock实现的基础是Volatile变量和CAS, 上面提到了Volatile变量的读/写可以实现”禁止重排序”的效果, CAS操作同时具有Volatile读和写的禁止重排序效果.
(#CAS的原理和实现的内存语义)一节介绍了CAS是如何同时具有Volatile变量的读和写的内存语义的.
ReentrantLock内存语义的实现解析
回顾ReentrantLock的实现,lock()调用栈如下:
- ReentrantLock : lock()
- FairSync : lock()
- AbstractQueuedSynchronizer : acquire(int arg)
- ReentrantLock : tryAcquire(int acquires)
在第4步真正开始加锁,tryAcquire方法首先读volatile变量state,
如果state==0, 说明还未加锁, 再尝试CAS(state, 0, 1), 如果CAS成功则成功获取到锁;
如果state!=0, 说明已经加锁, 再判断ExclusiveOwnerThread是否等于当前线程, 如果等于, 重入该锁(立刻获取到锁)
解锁方法unlock()的方法调用栈如下(公平锁为例):
- ReentrantLock : unlock()
- AbstractQueuedSynchronizer : release(int arg)
- Sync : tryRelease(int releases)
在第3步真正开始释放锁,tryRelease方法首先读volatile变量state,
读取到的值-1, 然后把这个减1后的值写入state(这里并没用CAS更新), 如果这个减1后的值==0, 则把锁状态置为free
由上可知, 公平锁在释放锁的时候写Volatile变量, 在获取锁的时候读取Volatile变量, 根据volatile的happens-before规则:
释放锁的线程在写volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变的对获取锁的线程可见。
CAS的原理和实现的内存语义
CAS同时具有volatile读和volatile写的内存语义。下面我们来分析在常见的 intel x86 处理器中,CAS 是如何同时具有 volatile 读和 volatile 写的内存语义的。
sun.misc.Unsafe类的compareAndSwapInt()方法是个Native方法, 最终调用到了JVM的C++代码Atomic::cmpxchg()(compare and change),
C++的Atomic::cmpxchg()最终调用的是”compare and change”的汇编代码cmpxchg ,
Atomic::cmpxchg()函数会根据当前处理器的类型来决定是否为cmpxchg指令添加lock前缀。
如果程序是在多处理器上运行,就为cmpxchg指令加上lock前缀(汇编代码是这个样子lock cmpxchg dword ptr[edx], ecx)。
intel的手册对lock前缀的说明如下:
- 确保对内存的读-改-写操作原子执行。
- 禁止该指令与之前和之后的读和写指令重排序。
- 把写缓冲区中的所有数据刷新到内存中。
上面的第2点和第3点所具有的内存屏障效果,足以同时实现volatile读和volatile写的内存语义。所以,现在我们终于能明白为什么JDK文档说 CAS同时具有volatile读和volatile写的内存语义 了。
Concurrent包的实现总结: Volatile 和 CAS
由于java的CAS同时具有 volatile 读和volatile写的内存语义,因此Java线程之间的通信现在有了下面四种方式:
- A线程写volatile变量,随后B线程读这个volatile变量。
- A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
- A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
Java的CAS会使用现代处理器上提供的高效机器级别原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键。
同时,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。
如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式:
- 首先,声明共享变量为volatile;
- 然后,使用CAS的原子条件更新来实现线程之间的同步;
- 同时,配合以
volatile读/写的内存语义和CAS的内存语义,来实现线程之间的通信。
下图是Java concurrent包的实现层次结构, 以Volatile和CAS为基础, JDK实现了AQS / Atomic类 / 非阻塞队列等等基本类, 然后
通过这些基本类实现了重入锁, 阻塞队列, 线程池等..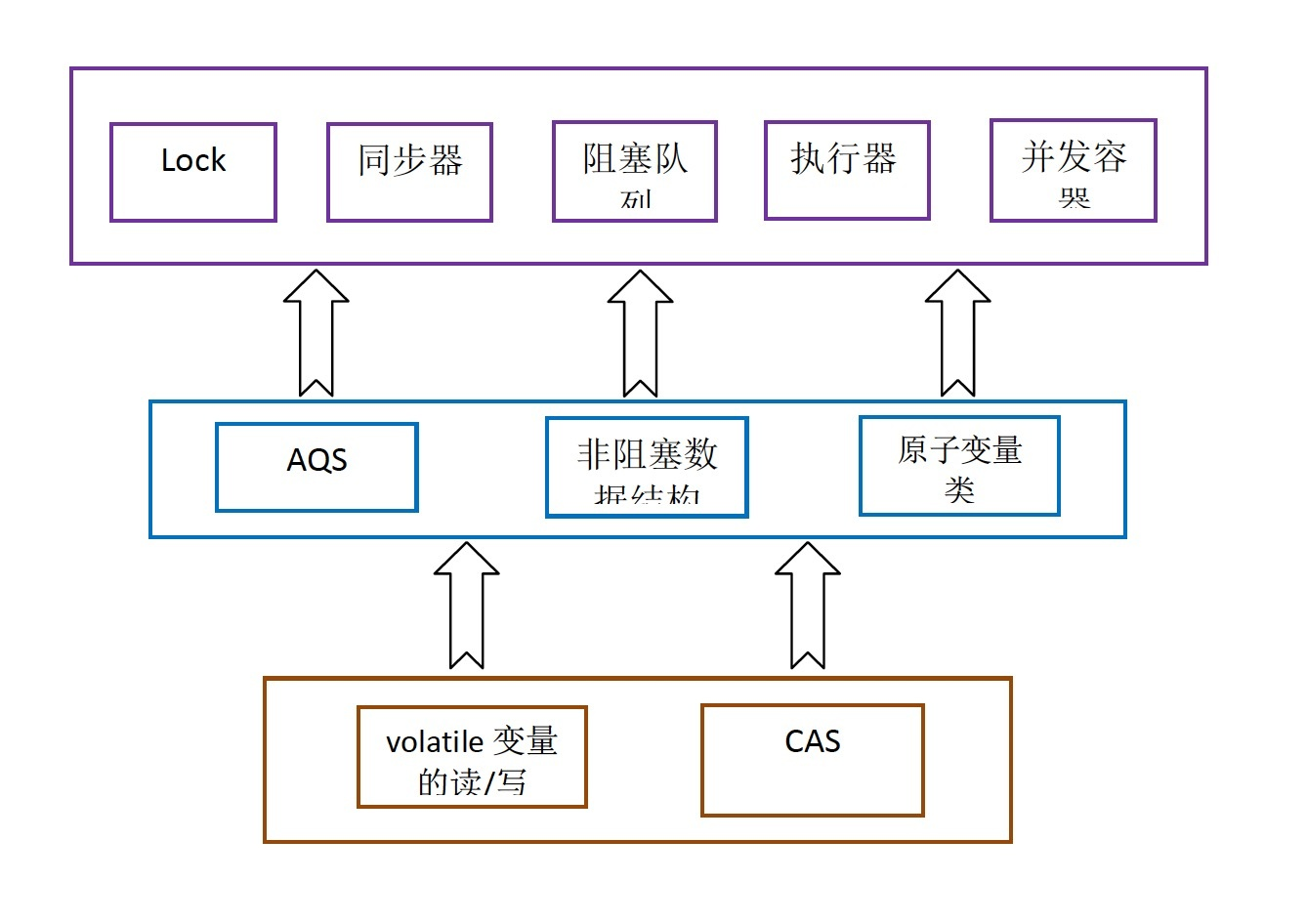
final
对于 final 域,编译器和处理器要遵守两个重排序规则:
- 在构造函数内对一个 final 域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含 final 域的对象的引用,与随后初次读这个 final 域,这两个操作之间不能重排序。
读写 FINAL 域的重排序规则
① 写: 写 final 域的重排序规则禁止把 final 域的写重排序到构造函数之外。这个规则的实现包含下面2个方面:
- JMM 禁止编译器把 final 域的写重排序到构造函数之外。
- 编译器会在 final 域的写之后,构造函数 return 之前,插入一个 StoreStore 屏障。这个屏障禁止处理器把 final 域的写重排序到构造函数之外。
② 读: 在一个线程中,初次读对象引用与初次读该对象包含的 final 域,JMM 禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读 final 域操作的前面插入一个 LoadLoad 屏障。
FINAL 域是引用类型
对于引用类型,写 final 域的重排序规则对编译器和处理器增加了如下约束:
在构造函数内对一个 final 引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
回到错误的DLC单例代码
常见的双重锁检查(Double Checked Locking)的单例代码如下:
public class DoubleCheckedLocking { //1 |
但是这样写是有问题的,在多线程并发的情况下,当有某个线程在步骤4进行检查的时候发现instance非null,但instance却指向一块已经分配但是未初始化的内存。
示例代码的第7行instance = new Instance()创建一个对象。这一行代码可以分解为如下的三行伪代码:
synchronized (DoubleCheckedLocking.class) { |
由JSR-133的happens-before和as-if-serial语义,在单线程里1 happens-before 3,但2不能保证happens-before 3,
2和3有可能发生重排序,执行顺序变为 1-3-2,调用构造方法初始化对象被重排序到了最后一步,
如果发生了1-3-2的重排序,
当线程A执行完3,但还没执行2的时候(instance指向分配好的内存, 但这块内存还未由构造函数初始化),A线程却被CPU让出了,
线程B开始运行, 到第一次判断instance==null,线程B判断instance是非null,不用走下面的sync, 直接返回了这个instance, 线程B获取到了(还未初始化的)instance引用。然后就出问题了
所以, 解决方法有两种思路:
- 不允许 2 和 3 重排序;
- 允许 2 和 3 重排序,但不允许其他线程“看到”这个重排序,也即1-3-2都执行完之后其他线程才可以”看到”改变(可见性)。
第一种解决方案是, 将 instance 变量声明成 volatile。
当声明对象的引用为 volatile 后,“问题的根源”的三行伪代码中的 2 和 3 之间的重排序,在多线程环境中将会被禁止。
第二种方案, 基于类初始化锁, 代码示例:
public class InstanceFactory { |
回顾一下Java对初始化的规范:
T 是一个类, 首次对 T 的 static成员属性 进行读写的时候, 会触发 T的初始化
T 是一个外部类, T被初始化的时候, 其静态内部类Inner不会被初始化,
作为内部类, InstanceHolder 不会在 外部类初始化时被初始化(可以实现延后初始化),
首次调用 InstanceFactory.getInstance()的时候, 相当于调用了 getstatic指令读取 InstanceHolder的静态属性, 会导致 InstanceHolder 被初始化,
初始化包括 执行static代码块, 初始化static成员属性, 这些操作代码都被放在一个叫 < clinit >的方法中, 被JVM加锁执行.
这个方案的实质是:允许“问题的根源”的三行伪代码中的 2 和 3 重排序,但不允许其他线程(这里指线程 B)“看到”这个重排序。
Java 语言规范规定,对于每一个类或接口 C,都有一个唯一的初始化锁 LC 与之对应。从 C 到 LC 的映射,由 JVM 的具体实现去自由实现。JVM 在类初始化期间会获取这个初始化锁,并且每个线程至少获取一次锁来确保这个类已经被初始化过了
Java字节码
一些有关Java字节码的文章:
- Java Zone: Introduction to Java Bytecode 这篇文章图文并茂地向你讲述了 Java 字节码的一些细节,是一篇很不错的入门文章。
- IBM DeveloperWorks: Java bytecode 讲 Java 字节码。
字节码相关库
可以操作字节码的库:
- JVM Tool Interface (JVMTI): Java Bytecode and JVMTI Example,这是一些使用 JVM Tool Interface 操作字节码的比较实用的例子。包括方法调用统计、静态字节码修改、Heap Taggin 和 Heap Walking。计、静态字节码修改、Heap Taggin 和 Heap Walking
- asm tools - 用于生产环境的 Java .class 文件开发工具。
- Byte Buddy - 代码生成库:运行时创建 Class 文件而不需要编译器帮助。
多态性实现机制
方法绑定
Class 文件的编译过程中不包含传统编译中的连接步骤,一切方法调用在 Class 文件里面存储的都只是符号引用,而不是方法在实际运行时内存布局中的入口地址。
一部分方法的符号引用在类加载阶段或第一次使用时转化为直接引用,这种称为 静态绑定;
另一部分方法在类运行期间才能确定某些目标方法的直接引用,称为 动态绑定;
Java 字节码中与调用相关的指令共有五种(还有一种invokedynamic,比较复杂):
- 静态绑定: 调用哪个方法在编译期就确定了, 在类的加载阶段, static/final/private方法的符号引用被替换为直接引用, 用
invokestatic,invokespecial指令调用的方法都是在加载阶段被替换为直接引用:- invokestatic指令: 用来调用static方法;
- invokespecial指令: 用于调用私有实例方法、构造器,以及使用 super 关键字调用父类的实例方法或构造器,和所实现接口的默认方法。
- 动态绑定: 在运行阶段(每次类被初始化的时候?)才能确定直接引用的方法.
- invokevirtual指令: 调用所有的虚方法(即非私有实例方法, 除了static/private/Constructor方法之外的都算作虚方法, 虽然final方法也是由invokevirtual调用但是final方法不属于虚方法)
- invokeinterface指令: 调用接口方法
单分派 & 多分派
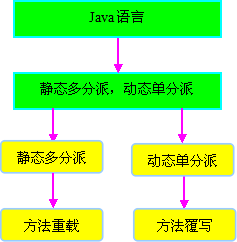
方法的调用者与方法的参数统称为方法的”宗量”, 单分派是根据一个宗量对目标方法进行选择, 多分派是根据多个宗量对目标方法进行选择
单分派是根据一个宗量对目标方法进行选择,多分派是根据多于一个宗量对目标方法进行选择。此外分派还可以根据”动态/静态解析”分为动态分派(运行期)和静态分派(编译期间).
两类分派方式两两组合便构成了静态单分派、静态多分派、动态单分派、动态多分派四种分派情况。
- 在编译阶段编译器的选择过程,即静态分派过程。这时候选择目标方法的依据有两点:一是方法的接受者(即调用者)的静态类型(基类类型),二是方法参数类型。因为是根据两个宗量进行选择,所以 Java 语言的静态分派属于多分派类型。
- 运行阶段虚拟机的选择过程,即动态分派过程。由于编译期已经了确定了目标方法的参数类型(编译期根据参数的静态类型进行静态分派),因此唯一可以影响到虚拟机选择的因素只有此方法的参数类型。因为只有一个宗量作为选择依据,所以 Java 语言的动态分派属于单分派类型。
编译期优化
语法糖
Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等。虚拟机并不支持这些语法,它们在编译阶段就被还原回了简单的基础语法结构,这个过程成为解语法糖。
编译器介绍
前端编译器
源码->字节码, javac
- 语法分析, 代码->Token, Token->语法树
- 填充符号表
- 语义分析, 保证逻辑性
- 字节码生成
后端编译器
字节码->机器码, 比如HotSpot自带的JIT, 当虚拟机发现某个方法或代码块运行特别频繁时, 就会把这些代码认定为Hot Spot Code, 虚拟机将会把这些代码编译成与本地平台相关的机器码
NIO
本节包括:NIO高性能的实现(异步非阻塞I/O + 堆外内存)、 网络编程中两种高性能I/O设计模式(多路复用):Reactor 和 Proactor
NIO高性能是如何实现的
- 使用异步非阻塞实现高效的单线程轮询,避免阻塞式IO开多线程的方式。// NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(Selector),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。
- NIO的读写函数可以立刻返回(用
Channel.configureBlocking(false)设置该通道为非阻塞),如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。 - Java的
Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。
- NIO的读写函数可以立刻返回(用
- 使用DirectBuffer减少IO时数据拷贝次数:
- 使用堆内内存的时候,比如我们要完成一个从文件中读数据到堆内内存的操作,调用
FileChannelImpl.read(HeapByteBuffer)实际上File IO会将数据读到堆外内存中,然后堆外内存再将这部分堆外数据拷贝到堆内内存。// 为什么Java IO会多一次内存拷贝? - 如果直接使用堆外内存,如
DirectByteBuffer,这种方式是直接在堆外分配一个内存(即,native memory)来存储数据,程序通过JNI, 直接将这部分的内存数据通过read()/write()到堆外内存中。
- 使用堆内内存的时候,比如我们要完成一个从文件中读数据到堆内内存的操作,调用
NIO & Reactor
Proactor vs Proactor 参考 → [[Linux/Linux-Primer.md]]
Reactor三种常见线程模型
▶ 单线程 Reactor 模型: 所有操作都在一个 Reactor Thread 上执行
- 几种角色: Acceptor, Dispatcher(分发器), IOHandler(IO处理函数)
- 在一个 Reactor Thread 里, select 监听 accept/read/write事件, 事件由 Dispatcher 进行分发:
- 有accept事件, Dispatcher 分发给 Acceptor 处理 // 还包括握手/鉴权等;
- 有r/w事件, Dispatcher 分发给 IOHandler处理 // Handler完成read->(decode->compute->encode)->send的业务流程;
- 缺点: 当某个Handler阻塞时,会导致其他客户端的handler和accpetor都得不到执行,无法做到高性能,只适用于业务处理非常快速的场景
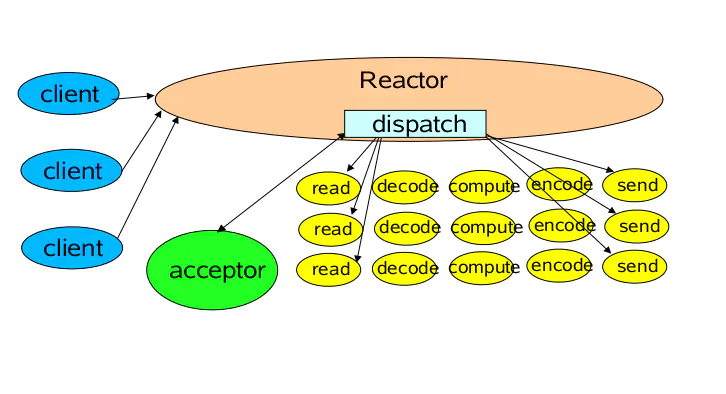
▶ 多线程 Reactor 模型:
- Reactor Thread 里, select 监听 accept/read/write事件, 事件由 Dispatcher 进行分发:
- 有r/w事件, Dispatcher 分发给 IOHandler处理 (函数调用, 仍在 Reactor线程里), 也就是只进行read读取数据和write写出数据;
- 把读到的数据交给业务线程池处理 decode->compute->encode, 响应的结果还是交回 Reactor Thread 进行发送
- 比较单线程模型, 多线程Reactor模型仍在主线程里处理读/写操作, 不再处理业务代码, 业务代码交给线程池执行;
- 缺点: Reactor Thread 仍然负责全部的accept/read/write的处理, 如果在 Reactor Thread 进行有大量读写事件, 同时大量连接事件(在accept时进行鉴权等), 这时候仍会有单线程的瓶颈
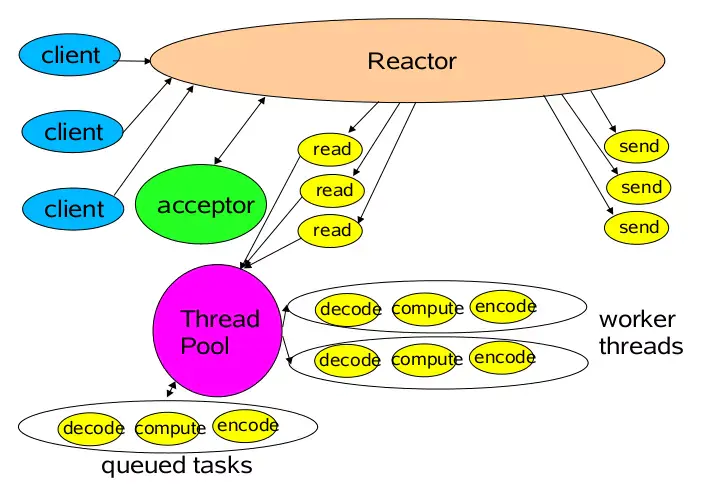
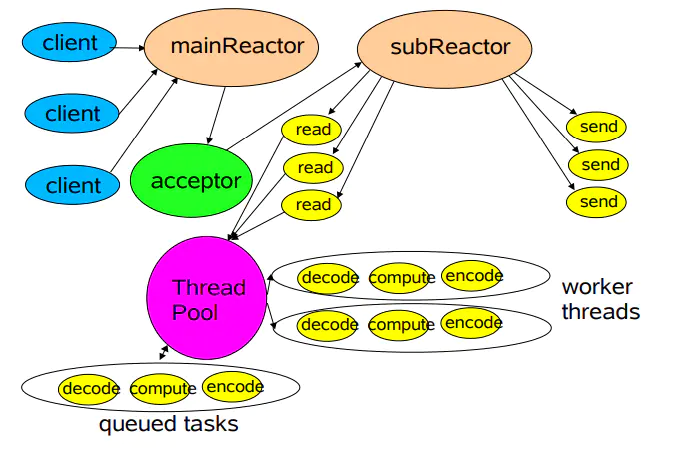
▶ 主从多线程 Reactor 模型:
- 存在多个 Reactor (Main Reactor and Sub Reactor), 每个 Reactor有自己的 Selector;
- Main Reactor 的 Selector负责监听 accept 事件, 交给Acceptor 处理;
- Acceptor 接受请求之后创建新的 SocketChannel, 处理鉴权/握手等 (这一步同一个线程, 还是交给main线程池?);
- 完成上一步处理的 SocketChannel, 从 Main Reactor 的Selector摘除, 并注册到 Sub Reactor 的Selector上;
- Sub Reactor 的Selector监听 read/write事件, 交给 Handler处理(read->业务代码->send)
@Uncertain: Reactor多线程模型中, 线程池是用来处理 IOHandler 还是业务?
第一种: Reactor线程 Select accept/read/write事件, 有r/w事件调用 IOHandler处理(还是在 Reactor线程), 业务代码(decode->compute->encode)交给线程池;
第二种: Reactor线程 Select accept/read/write事件, 有r/w事件, 交给线程池处理 read->(decode->compute->encode)->send
Netty 实现多线程 Reactor
▶ Netty中重要的 API类:
- NioEventLoop:
- 继承自 SingleThreadEventExecutor, 只有一个线程的线程池
- 每个 NioEventLoop 都有一个 Selector, 可以用来监听 accept/r/w事件
- NioEventLoopGroup: 一个NioEventLoopGroup 管理多个 NioEventLoop, 构造函数可以指定管理 NioEventLoop的个数, 如果没有设置,默认取 -Dio.netty.eventLoopThreads,如果该系统参数也没有指定,则为可用的 CPU 内核数 × 2。
▶ 用 Netty 实现多线程 Reactor:
NioEventLoopGroup bossGroup = new NioEventLoopGroup(); |
- 一个Server 有两个 NioEventLoopGroup: bossGroup 和 workerGroup
- 作为boss的 NioEventLoopGroup, 取第一个EventLoop, 用select 监听 accept事件, 然后交给Acceptor处理;
- Acceptor处理完accept并创建一个SocketChannel, 从第二个 作为worker的 NioEventLoopGroup里, 轮询取出一个EventLoop, 并把socket的读写事件注册到该 EventLoop 的 Selector; 这样Acceptor创建的SocketChannel被均匀分配给 worker 的每一个 Selector 用于处理读写事件 (默认参数下, 一个core上运行2个 worker的 Selector) ;
- Selector 发现读写事件, 创建Handler, 交给线程池处理
- 总结: Netty的多线程Reactor模型, boss线程的 Selector处理 accept事件, worker线程的 Selector处理 read/write事件, 交给线程池处理 read->业务代码->send
堆外内存
堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
堆外内存默认是和-Xmx默认一样大,也可以使用-XX:MaxDirectMemorySize指定堆外内存大小
堆内 vs 堆外
- 堆外内存减少了堆内内存的垃圾回收, 减少STW停顿;
- 使用Java的 堆内内存 进行IO操作, 会比C Native的程序多一次内存拷贝。为什么呢?
Java的IO底层也是调用了C Native的
read()/write()函数, 这些函数需要传入void *类型的内存地址, 并且这个内存地址指向的内容不能被改变, 否则read()/write()操作的内存就错了;
有些GC回收器会整理内存, Java对象在内存的地址会被改变,
所以使用堆内内存进行IO操作, 需要先把堆内内容copy到JVM堆外的连续内存, 然后传递给C的read()/write(), 这就多了一次内存拷贝;
JVM规范没有要求byte[]一定是物理连续的, 但是C里用malloc()分配的内存是连续的;
How to创建堆外内存
三种方式创建堆外内存:Auto
使用NIO提供的分配方法
ByteBuffer buf = ByteBuffer.allocate(1024); // 返回的是HeapByteBuffer
ByteBuffer buf = ByteBuffer.allocateDirect(1024); // 返回的是DirectByteBuffer使用NIO提供的堆外内存相关的类:
DirectByteBuffer,MappedByteBuffer// DirectByteBuffer
DirectByteBuffer dbf = new DirectByteBuffer(1024);
// MappedByteBuffer可以通过FileChannel实例获取, 用于文件内存映射直接使用unsafe:
Unsafe unsafe = GetUsafeInstance.getUnsafeInstance();
long pointer = unsafe.allocateMemory(1024);
DirectByteBuffer该类本身还是位于Java内存模型的堆中。
而DirectByteBuffer构造器中调用unsafe.allocateMemory(size)是个一个native方法,这个方法分配的是堆外内存,通过C的malloc来进行分配的。并不属于JVM内存。
堆外内存释放
- 通过堆内对象触发GC, 堆内对象和指向的堆外内存一并被回收;
- 通过Unsafe回收;
public class FreeDirectMemoryExample |
堆外内存GC
如果堆外内存容量超过了-XX:MaxDirectMemorySize 会发生OutOfMemoryError: Direct buffer memory,
如果GC 回收了 DirectBuffer 对象,那么 DirectBuffer 对象指向的堆外内存,会在GC的后期被回收,
如果Java程序使用的堆内内存(Heap)占用率不高但是却大量使用DirectBuffer分配堆外内存,
这种情况下不会因为堆内内存触发 Full GC也就无法自动释放堆外内存,
所以通常需要调用 System.gc() 来强制回收 堆外内存(但是线上环境不建议这样触发Full GC),这种情况下一定确保不能启用了 -XX:+DisableExplicitGC 导致 System.gc()被禁用。
System.gc()会建议JVM进行Full GC, 对新生代的老生代都会进行内存回收,这样会比较彻底地回收DirectByteBuffer对象以及他们关联的堆外内存.
DirectByteBuffer对象本身其实是很小的,但是它后面可能关联了一个非常大的堆外内存,因此我们通常称之为冰山对象.
JVM 发生 YGC(Young gc很频繁, 会STW, 但是Copy GC算法的STW极短)的时候会将新生代里的不可达的 DirectByteBuffer 对象及其堆外内存回收了,但是无法对Old Gen里的 DirectByteBuffer 对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题。( 并且堆外内存多用于生命期中等或较长的对象 )
如果有大量的 DirectByteBuffer 对象移到了Old Gen,但是又一直没有做Old Gen 的CMS GC或者Gull GC,那么物理内存可能被慢慢耗光,但是我们还不知道发生了什么,因为heap明明剩余的内存还很多。
AIO
AIO(asynchronous I/O)异步IO:
java.nio.channels包做了支持, 包括: AsynchronousSocketChannel, AsynchronousServerSocketChannel, AsynchronousFileChannel