
@TLDR
- cpu:
- uptime 查看load值, 不高于core数,
sar -q也可以查看load值 - vmstat: 关注r(同load), 和b(等待资源的进程数), 以及cpu占用(用户进程和内核进程)时间百分比: us%不超过50%, us% + sy%不超过80%
- sar也可以查看us% sy%占用CPU时间百分比
- uptime 查看load值, 不高于core数,
- 内存:
- free: 可用内存小于20%需要关注,
sar -r类似 - vmstat的si和so: 一般不应该大于0,
sar -W也可以查看交换区
- free: 可用内存小于20%需要关注,
- I/O:
- vmstat: 需关注wa(IO等待占用CPU百分比): 大于30%时需关注, bi/bo也需要关注(阈值?)
- iowait: sar也可以查看iowait%
- 网络:
- netstat -antp : 查看所有tcp连接
- iperf: 吞吐量(Throughput) , 大约为网卡最大速率的一半
基础性能参数
load
一个类比说明load值: 如果CPU每分钟最多处理100个进程,那么系统负荷0.2,意味着CPU在这1分钟里只处理20个进程
cat /proc/cpuinfo
一个物理封装的CPU(通过physical id区分判断), 可以有多个”核心”(通过core id区分判断), 每个核可以有多个”逻辑cpu”(通过processor区分判断)
- 物理Cpu数:
cat /proc/cpuinfo | grep "physical id" | sort -u |wc -l输出2 - 核心数:
cat /proc/cpuinfo | grep "core id" | sort -u |wc -l输出8 - 逻辑Cpu数:
cat /proc/cpuinfo | grep "processor" | sort -u | wc -l输出32
uptime
- uptime返回1/5/15分钟内的load值(进程队列的长度), 对于单核cpu, load值在1.0以下可以接受, 对于多核CPU, load值要除以”核心数”
- 多核CPU的话, 满负荷状态的数字为 “1.00 * CPU核数”, 这里的CPU核数是
processor的数量, - 某台服务器举例: 2个物理CPU, 每个物理CPU包括8个Core, 每个Core包括4个Processor(HT超线程),
- 以上参考Understanding Linux CPU Load - when should you be worried? @Ref
- 1/5/15分钟的load值, 应该参考哪一个? 如下:

load值走高也不一定就是cpu资源紧张导致的, 还需要结合
vmstat,iostat工具进行确认和判断是cpu不足还是磁盘IO问题又或者是内存不足导致.
ps
ps -ef: e参数列出所有(用户)的进程, f列出PPID;ps aux: 能显示出更多的线程信息, 比如”VSZ”,”RSS”,”TTY”,”STAT”.ps -l: 列出进程优先级(PRI), Nice值(NI),内存占用(SZ)ps -T -p <pid>: 查看进程的所有线程
ps aux
USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND |
VSZ
KB, virtual memory size, Device mappings are currently excluded;
RSS
KB, resident set size, 一般作为实际占用内存大小,
包括程序二进制映像(binary image), Heap/Stack实际使用(系统为进程分配的堆和栈, 不一定完全用掉), 共享区(shared Library, 也即Memory Mapping)实际使用的空间;
区分VSZ,RSS,SZ
http://stackoverflow.com/questions/7880784/what-is-rss-and-vsz-in-linux-memory-management
STAT
R/S/D/T/Z/X : http://askubuntu.com/questions/360252/what-do-the-stat-column-values-in-ps-mean
ps -el
UID PID PPID F CPU PRI NI SZ RSS WCHAN S ADDR TTY TIME CMD |
SZ
size in physical pages of the core image of the process. This includes text, data, and stack space. Device mappings are currently excluded
PRI 优先级
PRI表示线程优先级(数值越小越先执行), 优先级的范围是[0, MAX_PRIO-1], MAX_PRIO 的值一般为140.
NI 修正优先级
- NI=Nice, 值表示对优先级PRI的修正, 范围从-20~19, Nice越小表示优先级越高.
- 以指定Nice启动任务:
nice -n -5 /usr/bin/mysqld &, 注意这里-5并不是表示负数, 而是正数5, 如果要以高优先级启动某进程(负的Nice值), 则应该为nice -n --5 top. - 使用nohup:
nohup -n 10 COMMANDS - 改变已存在进程的优先级:
renice -5 -p 1203注意这里的”-5”表示负数.
pstree
- pstree -apu 显示进程树
- -a 显示进程的命令行
- -p 显示PID
- -u 显示UID, 如果子进程和父进程的UID不同, 比如Nginx启动worker线程用nobody
top
- 查看指定进程:
top -d 1 -p 1021, 解释: -d 刷新间隔, -p 进程号, 每列”VIRT”, “RES”, “SHR”的表示含义- VIRT: 进程“需要的”虚拟内存大小, 包括库/代码/数据,
VIRT = SWP + RES - RES: 常驻内存(Resident memory), 包括共享内存,
进程实际占用内存 = RES - SHR - SHR: 共享内存(Shared memory), 比如动态库
- VIRT: 进程“需要的”虚拟内存大小, 包括库/代码/数据,
- 某个进程占用的CPU和内存也可以用
ps -aux查看, 其中RSS(Resident Set Size)表示实际RAM使用,VSZ(Virtual Memory Size)包括程序占用的SWAP空间, 和使用的shared libraries所占用的空间. - 或者, 直接查看
/proc/PID/status文件也可以得知进程占用RAM的情况. - 查看线程:
top -H, 查看指定进程的线程:top -H -p <pid>
free
- What is the difference between Buffers and Cached columns in /proc/meminfo output?
- Buffer 是准备写入块设备的数据, 存储了文件的目录/权限等metadata;
- Cache 频繁访问的文件都会被cache, 里面只有文件内容数据;
vmstat
[@tc_157_46 ~]# vmstat 1 |
vmstat每列解释
procs列
- r 等待cpu时间片的进程数, 如果长期大于1, 说明cpu不足, 需要增加cpu.
- b (在等待资源的进程数, 比如正在等待I/O, 或者内存交换等).
memory列
- swpd 虚拟内存大小(交换区). 如果swpd的值不为0, 比如超过了100m, 只要si, so的值长期为0, 系统性能还是正常
- free 空闲内存大小
- buff 做为buffer的内存大小, 一般对块设备的读写才需要缓冲.
- cache: 做为page cache的内存大小, 一般做为文件系统的cache, 如果cache较大, 说明用到cache的文件较多, 如果此时IO中bi比较小, 说明文件系统效率比较好.
swap列
- si 每秒由内存进入内存交换区数量.
- so 每秒由内存交换区进入内存数量.
io列
- bi 每秒从块设备读取数据的Blocks, 一个Block =1024byte
- bo 每秒块设备写入数据的总量
这里我们设置的bi+bo参考值为1000, 如果超过1000(1MB), 而且wa值较大应该考虑均衡磁盘负载, 可以结合iostat输出来分析.
system列
- in 每秒设备中断数.
- cs 每秒产生的上下文切换次数, 如当cs比磁盘I/O和网络信息包速率高得多, 都应进行进一步调查.
cpu列
- us 用户进程所占时间的百分比. 如果长期大于50%, 需要考虑优化用户的程序, 比如加密解密等运算.
- sy 系统进程所占时间的百分比. 这里
us+sy的参考值为80%, 如果us+sy大于80%说明可能存在CPU不足. - wa IO等待所占用的CPU时间百分比. 这里wa的参考值为30%, 如果wa超过30%, 说明IO等待严重, 这可能是磁盘大量随机访问造成的, 也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作).
- id 空闲状态的CPU时间百分比
iostat
命令格式: iostat [option] [间隔秒数] [统计次数] , 比如iostat -x 1 10表示1秒打印一次, 共10次
[@tc_157_46 ~]# iostat -x 1 1 |
- %util: IO操作占用CPU时间的百分比: 如果%util长期接近100%, 说明产生的I/O请求太多, I/O系统已经满负荷, 该磁盘可能存在瓶颈.
- Idle如果长期大于70% IO压力就比较大了,这时一般读取速度有较多的wait.
sar
查看系统的不同时间段的状况, CPU, load, 页面交换
- CPU
- sar 或sar -u: 查看CPU占用状况
- sar -q 查看任务队列, 同load
- 内存
- sar -r 查看内存使用, 同free
- sar -W 查看Swap区的数据交换状况, 怀疑Swap频繁导致系统变慢可以使用
- IO
- sar -b
- sar -d 1 5: 一秒每次, 共5次, 显示实时的信息
- 网卡
- sar -n DEV 1 5: 一秒每次, 共5次, 显示实时的信息
netstat
查看TCP的并发数/TCP连接的状态, 以一个Nginx服务器为例:
[@zw_85_63 ~]# netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' |
sysctl优化内核参数
- sysctl -a | grep vm
- sysctl -a | grep net.ipv4
调整
- sysctl -w net.ipv4.tcp_syncookies=0
并发相关的内核参数调整参考 : 后端架构-并发(C10K/C100K) | 扔掉笔记 @Ref
附:Linux Performance Tools(图)
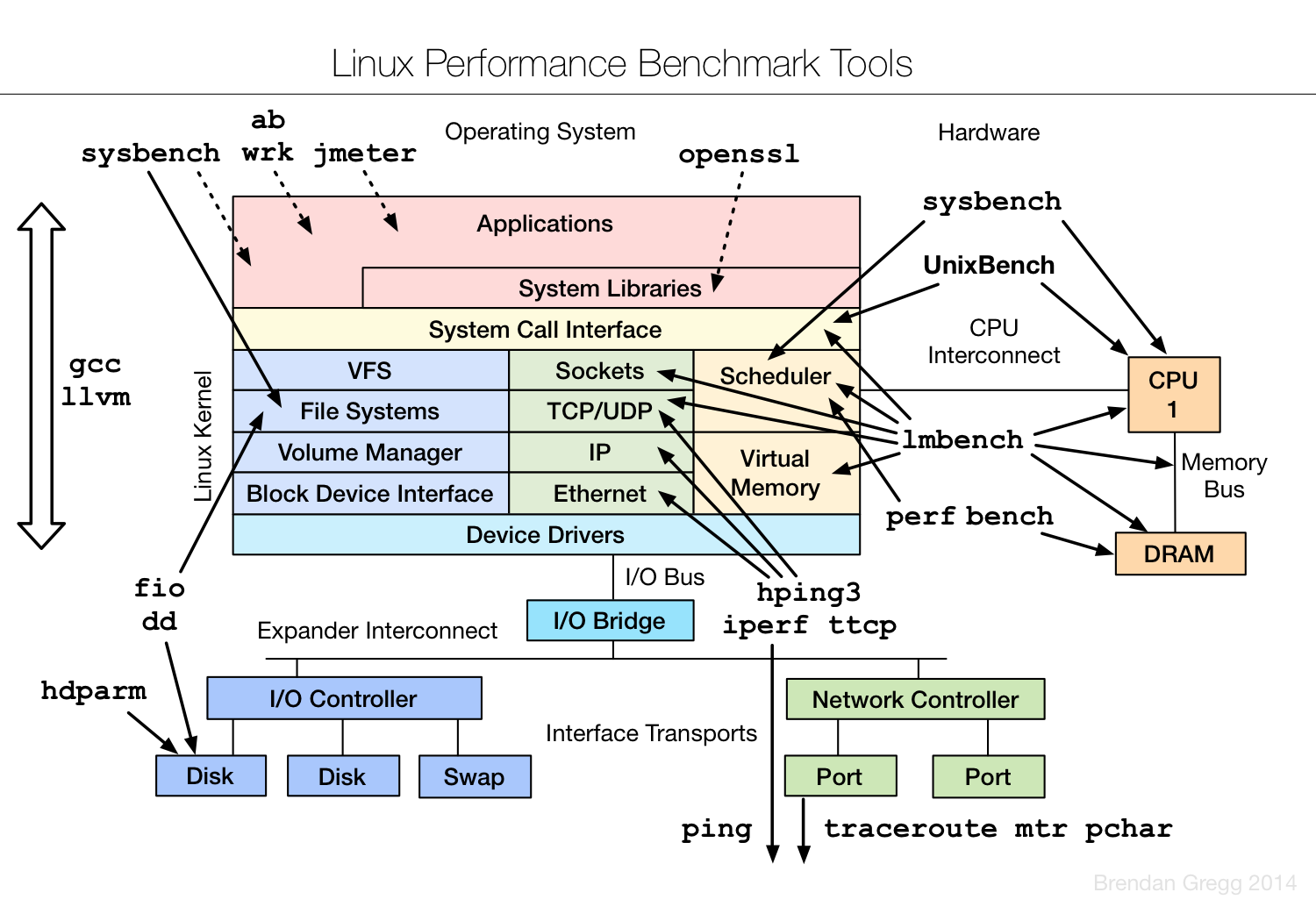
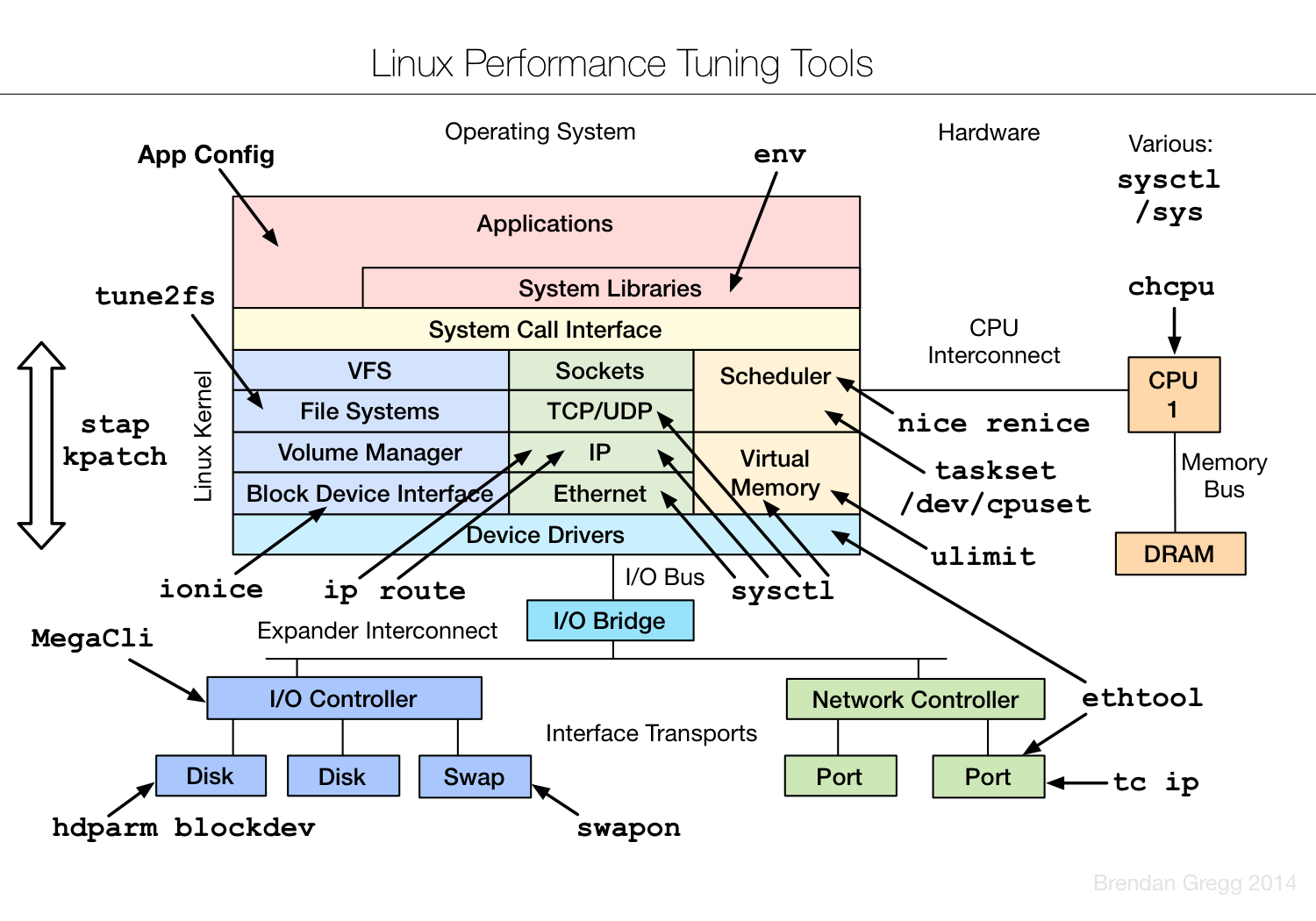
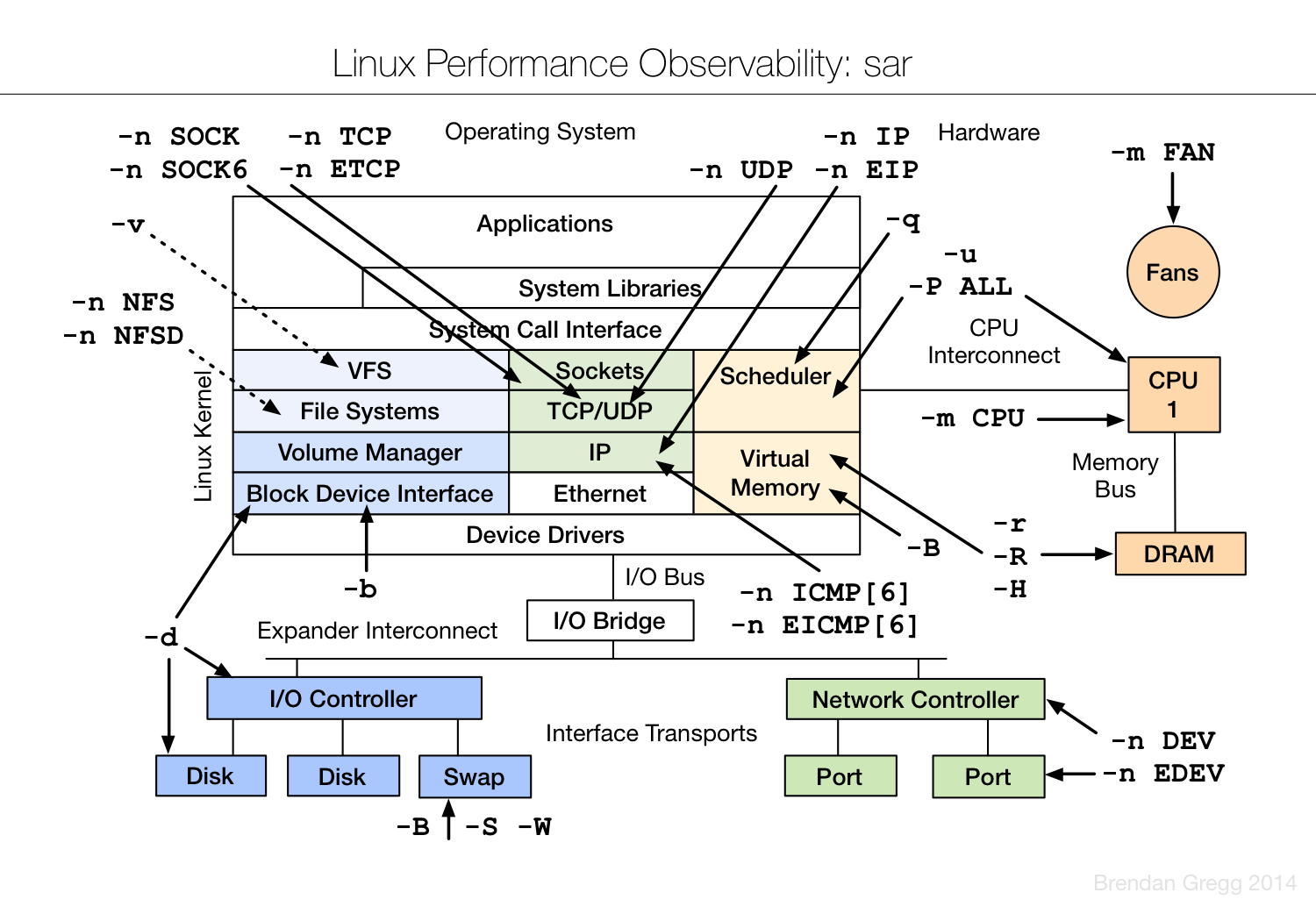
来源: https://colobu.com/2014/09/18/Linux-Performance-Analysis-and-Tools/
附:线上服务器的数据
平均值~峰值:
- Nginx & Memcache:
- load少于0.1, iowait少于0.1%,
- User:System时间大约10%:5%(峰值), 每秒上下文切换(用vmstat查看cs)20-50K,
- 打开TCP连接4000, 带宽200Mbps (千兆网卡)
- Redis:
- load少于0.1, iowait少于0.1%,
- User:System时间不到0.1%(峰值), 每秒上下文切换2-4K+,
- 打开TCP连接数600, 带宽2.0Mbps
- Resin:
- load少于0.2, iowait少于0.2%,
- User:System时间大约15%:2%(峰值), 每秒上下文切换30~60K,
- 打开TCP连接数1500, 带宽40~80Mbps,
- Hadoop:
- load大约0.5~1.5, iowait时间2%-20%, 峰值iowait能到35% ( 一般大于30%需要排查 )
- User:System时间大约15%:1%, 每秒上下文切换2-7K,
- 打开TCP连接数, 带宽20-70Mbps
- Flume:
- load少于0.1, iowait少于0.1%,
- User:System时间大约5%:1%, 每秒上下文切换30-60K,
- 打开TCP连接数, 带宽5-25Mbps
注: 上面Hadoop机器的iowait有问题, 数据选自一台硬盘有问题的机器