常用命令
使用 man
man 可以查看”系统命令/系统调用函数/glibc库函数” 等等共9类内容, 例如 man lsof 第一行是 “LSOF(8)”, 表示是第8类, man man 第一行是”man(8)” 表示man 是第8类, 也可以看到所有9类 “manual”, 如下:
- 系统命令
- 系统调用,一般是对应的C封装函数;所有系统调用的函数在调用发生时都会进入内核空间执行
- 各种库函数手册,例如glibc,pthread库API等,如果是非C库,则会标注出对于的链接选项
- 特殊设备文件,例如zero, mem等
- 文件格式手册,描述Linux支持的各种文件系统以及对于的C接口结构,如vfat/iso
- 游戏程序文档
- 其它的各种各样不在前边分类的文档(8/9除外)
- 系统管理员命令,一般仅供root用户使用,如cron/useradd等
- Linux内核相关部分的手册,一般情况很少用到,这一节就没有intro介绍页
man ascii: 该命令用来查看 ASC II表man malloc: 查看malloc用法, 如果显示 “No manual entry for malloc”, 则需要安装 “man-pages”:yum -y install man-pages
ps, top, free, vmstat
vmstat, sar, iostat, iotop
@Ref 参考 → Linux-Performance.md
sort, uniq, wc, cut
sort参数:- -t 指定分隔符
- -n 按数字大小排序, 如果不加-n默认是ASCII码排序
- -r 倒序
- -k 1,5 指定按哪一列排序, 默认是从第N列到行尾,
-k4指定按第四列排序
例:
按进程VSS内存排序:ps aux | tr -s " " | sort -nrk 5 | cut -d " " -f 1,2,5,6,11- | more
分隔符为”:”的文件按照第5列数值排序:cat file | sort -t : -nrk 1,5uniq只能去除相邻行的重复, 所以一般跟sort联用.cat /proc/cpuinfo | grep 'physical id' | sort | uniq | wc -lwc: -l行数, -w单词数cut用来显示行中的指定部分, 分隔符用-d 参数(如果不加-d参数则分隔符是制表符), 取出第几列用-f 参数(从1开始),
例:who | cut -d ' ' -f 2注: cut通常和其他命令一起使用, 用来处理其他命令的输出, 但实际情况下很多命令的分隔符并不统一, 所以用 awk比 cut更方便:
ls -l | awk '{print $9}'
ln
- 创建软链接:
ln -s src target// 记住ln ... as ... - 创建硬链接:
ln src target - 软链接vs硬链接:
- 允许对目录创建软链接,硬链接不可以
- 可以跨文件系统创建软链接, 硬链接不可以
- 删除源文件, 软链接将失效, 硬链接仍保留删除前源文件内容
gzip, bzip2, tar

压缩与读压缩命令:gzip -v file1 # 压缩为gz格式
bzip2 -z file1 # 压缩为bz2格式
zcat file1.gz # 不解压读取gz
bzcat file1.bz2 # 不解压读取bz2
gzip -d file1.gz # 解压gz
bzip2 -d file1.bz2 # 解压bz2
注意: gzip压缩后不保留源文件, bzip2必须加
-k参数才保留源文件
打包与解包:tar cvzf file1 file1.tar.gz # 打包为 tar.gz
tar cvjf file1 file1.tar.bz2 # 打包为 tar.bz2
tar xvzf file1.tar.gz
tar xvjf file1.tar.bz2
where, which, locate
功能和which类似, 也是一种查找, 区别在于locate搜索的是数据库/var/lib/locatedb所以速度更快, 例如locate _vimrc
sed, awk
@Ref 参考 → sed & awk & grep
find, grep, ack
- find:
- 按时间查找, 可用参数有:
-mmin以分钟为单位,-mtime以天为单位, 后面的数字+表示比该时间更早,-表示该时间之后-当前,- 查找N天之前更早的文件:
find . -mtime +3 -name '*.log' - 查找N天前-当前时刻的文件:
find . -mtime -3 -name '*.log'
- 查找N天之前更早的文件:
- 在当前目录及其子目录下查找符号链接文件:
find -type l - 在当前目录及其子目录下查文件夹:
find -type d - 在当前目录查找普通文件:
find -type f - 在root目录下及其最大3层深度的子目录中查找:
find / -max-depth 3 -name log - 查找特定文件并ls列出:
find -name *.java -exec ls -l {} \;注意exec的参数必须以”分号”结束,分号还要加转义符.解释:{}是前面find找到的文件,-exec后面的参数后面跟的是command命令, 它的终止是以;为结束标志的, 所以这句命令后面的”分号”是不可缺少的, 考虑到各个系统中分号会有不同的意义, 所以前面加反斜杠. 参考 Using semicolon (;) vs plus (+) with exec in find - Stack Overflow- shell的内建命令
-exec将并不启动新的shell, 而是用要被执行命令替换当前的shell进程, 并且将老进程的环境清理掉, 而且exec命令后的其它命令将不再执行. 以新的进程去代替原来的进程, 但进程的PID保持不变.
- 按时间查找, 可用参数有:
- grep:
- 查找某个文件:
grep "Invalid user" /var/log/auth.log - 在某个目录下递归查找:
grep -irn "xxx" /dir
- 查找某个文件:
- ack:
ack xxxx dir/log1: 在指定文件里搜索xxxack --java xxxx: 在java文件里搜索xxxack -i xxx: 不区分大小写ack -w xxx: 全词匹配
who, w, whoami, last
w- Show who is logged on and what they are doing.who- show who is logged onwhoami- print effective useridwho am i- When a user logs in as a root across the network, both the commandwhoamiandwho am iwill show you root. However, when a user abc logs in remotely
and runssu – root,whoamiwill show root whereaswho am iwill show abclast: 获取每个用户登录的持续时间. 该记录保存在:/var/log/wtmp
lsof, fuser
fuser:
列出哪个进程在使用文件: fuser /etc/filenames
lsof:
- 常用参数:
-p 进程id-i :端口号-P: 默认情况lsof会显示 “端口名字” 而不是 “数字类型的端口号” (如果此端口号有名字的话),-P可以指定显示数字端口号, 而不是名字
- 用法示例:
- 查找已被删除但硬盘空间不释放的文件:
lsof |grep delete, 这个文件的innode链接被移除了, 但还没有被删掉 - 某个端口:
lsof -i TCP:8080orlsof -i :80 - 某个进程:
lsof -p PID - 查看所有活动状态的网络服务: lsof -i
- 查看某个用户打开的文件:
lsof -u ^root, 或者lsof | grep ^root
- 查找已被删除但硬盘空间不释放的文件:
Example: lsof返回数据如下:
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME |
lsof | awk '{process[$1]++;} END{for(key in process) printf("%s:%d\n", key, process[key])}'#每个进程打开的文件数lsof | awk '{if($8 == "TCP") opened_tcp++} END{print opened_tcp }'#打开TCP连接数量lsof | awk '{opened_type[$5]++} END{ for(key in opened_type) printf("%s : %d\n", key, opened_type[key])}'#打开文件按TYPE统计
du, df, fdisk
- du:
- 查看当前子目录大小:
du -h --max-depth=1 - 当前目录文件按大小排序:
du -s * | sort -n | tail
- 查看当前子目录大小:
-exec, xargs
xargs的作用一般等同于大多数Unix shell中的反引号, 但更加灵活易用, 并可以正确处理输入中有空格等特殊字符的情况. 对于经常产生大量输出的命令如find、locate和grep来说非常有用: file * |grep ASCII | cut -d":" -f1 |xargs ls -l
- -exec查找并grep:
find . -name "*.php" -exec grep -in "string" {} \;最后的\;是-exec的结束标识 - xargs:
find . -name "*.php" | xargs grep -in "string"
ulimit
- 查看所有的限制:
ulimit -a- set 最大打开文件句柄数:
ulimit -n 65535, 查看当前值ulimit -n - set 最大进程数:
ulimit -u 32768, 查看当前值ulimit -u - set 线程栈的大小:
ulimit -s 10240 - set core文件大小:
ulimit -c xxx, 不限制core的大小:ulimit -c unlimited
- set 最大打开文件句柄数:
ulimit起作用的范围是当前Shell, 并不是作用于”当前用户”, 如要对”用户”做限制, 则需要修改系统文件
/etc/security/limits.conf
umask
umask命令用来设置限制新建文件权限的掩码。当新文件被创建时,其最初的权限由文件创建掩码决定。用户每次注册进入系统时,umask命令都被执行, 并自动设置掩码mode来限制新文件的权限。用户可以通过再次执行umask命令来改变默认值,新的权限将会把旧的覆盖掉。
umask 022: 用户权限为755umask 077: 用户权限为700
su, sudo
su:
su: 切换到root用户, 切换之前的环境变量一并被带到了新shell里;su - user_name: 切换用户, 切换之后的环境变量会改变为新用户的,su -同su - root- 例:
su - root -c commands, 执行完commands之后自动切换会原来的用户.
- 例:
sudo:
sudo是受限制的su, 两个命令的最大区别是:sudo命令需要输入当前用户的密码,su命令需要输入 root 用户的密码。sudo -s cmd: 执行cmd命令, 如果是sudo -s则会启动一个可交互shell, 有点类似su,- 通过修改
/etc/sudoer配置哪些用户具有执行sudo的权限, sudo命令能继承哪些环境变量也是在/etc/sudoer中配置的.
export & 环境变量
VAR=hello$VAR scope is restricted to the shell;export VAR=hellomakes the $VAR available to child processes;
每个进程的环境变量可以在/proc/$PID/evnrion查看.
sh, exec, source的区别
source和 点命令.是一样的, 不会启动子shell, 不需要script有可执行权限, script里定义的变量也会被导入当前的shell环境../script启动子shell, script里的变量不会被带进当前环境, 相当于fork, 需要脚本有x权限sh ./script先启动了一个子shell, 子shell继承父shell的环境变量, 但子shell里新建变量、改变变量 不会被带回父shell, 除非用export VAR="xxx"exec cmd产生了新的进程, 新进程会关闭当前shell的进程, 新的进程继承了原shell的PID号, 原shell剩下的内容不会执行,
顺序执行
多命令顺序执行:
- 分号(
;): 顺序执行,命令之间不存在关系,互不影响- 例
ls; date; cd /user; pwd
- 例
- 逻辑与(
&&): 只有第一条命令成功执行,才会执行第二条命令- 例
cd ~/dir && git commit -am "u" && git pull && git push
- 例
- 逻辑或(
||): 第一条成功执行,第二条不执行; 第一条非正确执行,第二条才会执行
nohup
并不是所有的程序都像 Nginx, Redis, httpd一样提供守护进程, 保证在关闭终端会话后正常运行.
如果终端会话关闭,那么程序也会被关闭。为了能够后台运行,那么我们就可以使用nohup:
nohup cmd &: 后台运行cmd, 程序运行的输出信息放到当前目录的 nohup.out 文件中去nohup command > myout.log 2>&1 &: 后台运行cmd, 并指定输出的文件
nohup的原理也很简单,终端关闭后会给此终端下的每一个进程发送
SIGHUP信号,而使用nohup运行的进程则会忽略这个信号,因此终端关闭后进程也不会退出。
命令重定向
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件: 文件描述符 0 通常是标准输入(STDIN),1 是标准输出(STDOUT),2 是标准错误输出(STDERR)。
输出重定向
将输出重定向到 file |
有关
command >out.file 2>&1 &的解释(注意文件描述符和重定向符号之间不能有空格):
最后的&表示后台运行;
为什么是2>&1而不是2>1? 这样做会直接输出文件名为1的文件;>outfile和2>&1的顺序可以交换吗? 不可以,command 2>&1 >out.file, 先2>&1的意思是 stderr输出到 stdout, 此时的 stdout是输出到终端的, stderr也就被输出到终端, 然后>out.file是把 stdout输出到文件, 但是此时 stderr还是输出到终端的;
输入重定向
将 file的内容作为标准输入 |
默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。
其他用法
- 创建一个空文件, 除了touch还可 :
> file - 用ssh远程执行本地脚本, 不用scp拷贝 :
ssh root@host bash < /local/xxx.sh <(COMMAND)可以作为一个文件 :diff /etc/host <(ssh remote cat /etc/hosts)
trap
- 脚本内执行
java -jar ...命令, 通过$!获得子进程ID - 脚本执行
wait 子进程ID - 如下
_term() { |
网络相关命令
ping
ping是通过发送ICMP报文(回显请求), 并等待回显请求的应答, 目标主机的防火墙可能对ICMP报文做了限制, 所以ping不通不代表无法ssh.
ifconfig
启动关闭指定网卡
ifconfig eth0 up
ifconfig eth0 down配置IP地址
ifconfig eth0 192.168.2.10 netmask 255.255.255.0 broadcast 192.168.2.255
netstat
显示建立的网络连接, 分为三种: tcp/udp/unix(进程通讯)
netstat -au: 显示所有udp连接netstat -at: 显示所有tcp连接netstat -nlt:- -n 显示ip而非域名
- -l 显示所有listen状态的连接
- -p 显示出连接对应的进程, 需要root权限才能看到
netstat -r: 显示路由表/网关, 同 route返回的
nslookup, dig
nslookup, dig 都是DNS查询命令:
- nslookup: 用于对DNS正向解析 & 返向解析;
nslookup a.xxx.com使用默认dns查询网址的dns记录nslookup a.xxx.com 8.8.8.8使用指定dns服务器查询dns记录
- dig: 是一个用于询问DNS 域名服务器的灵活的工具。它执行DNS 查询,显示从已查询名称服务器返回的应答。
dig: 显示13个根域服务器dig www.baidu.com: 使用默认dns查询网址的dns记录dig @8.8.8.8 www.yahoo.com: 使用指定dns服务器查询dns记录
route
- 命令格式
route add 目标网段 gw 网关地址 dev 设备 - 增加默认网关
route add default gw 192.168.0.254 - 增加网关:
route add -net 192.168.1.0 netmask 255.255.255.128 gw 192.168.1.129 dev eth0 - 删除网关:
route del -net 192.168.1.0 netmask 255.255.255.128 dev eth0 查看内核路由表:
route, 返回如下:Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.6.0 * 255.255.255.0 U 0 0 0 eth0
link-local * 255.255.0.0 U 1002 0 0 eth0
default 192.168.6.253 0.0.0.0 UG 0 0 0 eth0- Destination : 目标网段或者主机
- Gateway : 网关地址。如果是
*表示目标是本主机所属的网络不需要路由 - Genmask : 网络掩码
- Flags : 标记。一些可能的标记如下:
- U — 路由是活动的
- H — 目标是一个主机
- G — 路由指向网关
例如,在下面的示例中,本地主机将发送到网络192.19.12的数据包转发到IP地址为192.168.1.1的路由器。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ----- --- --- -----
192.19.12 192.168.1.1 255.255.255.0 UN 0 0 0 eth0
例如,在下面的示例中,默认路由是IP地址为192.168.1.1的路由器。
Destination Gateway Genmask Flags Metric Ref Use Iface
----------- ------- ------- ----- ------ --- --- -----
default 192.168.1.1 0.0.0.0 UG 0 0 0 eth0
traceroute
当ping不到或者丢包严重时, 使用traceroute可以看到从当前计算机到目标主机每一跳的耗时情况, 在哪一个节点丢包等细节
例子:
traceroute -I a.com: 使用ICMP ECHOtraceroute -T a.com: 使用TCP SYNtraceroute -p 8080 a.com: 查询到主机指定端口的路由
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径。当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不一样,但基本上来说大部分时候所走的路由是相同的。
linux系统中,我们称之为 traceroute,在MS Windows中为 tracert。
traceroute的工作机制主要是利用使用ICMP报文和和IP首部中的TTL字段来实现的。在网络数据包的传输过程中,每个处理处理数据包的路由器都要讲数据包的TTL值减1或者减去数据报在路由器中停留的秒数,由于大多数的路由器转发数据报的延时都小于1秒钟,因此TTL最终成为一个跳站的计数器,所经过的每个路由器都将其值减1。TTL字段的目的是防止数据报在网络中无休止的流动。当路由器收到一份IP数据报,如果TTL字段是0或者1,则路由器不转发该数据报(接收到这种数据报的目的主机可以将它交给应用程序,这是因为不需要转发该数据报。但是,在通常情况下系统不应该接收TTL字段为0的数据报)。通常情况下是,路由器将该数据报丢弃,并给信源主机发送一份ICMP超时信息。tracerouter程序的关键在于,这份ICMP超时信息包含了该路由器的地址。
tracerouter利用网络协议的这种机制,TTL值从1开始每次发送一个TTL等于上次值加一的数据包,直到收到目的主机的响应才停止。这样就能拿到数据包经过路径上的每个路由器的地址信息,从而打印路由信息。
有些情况下traceroute无法到达最终节点(traceroute一台主机时,会看到有一些行是以星号表示的) 有可能因为主机屏蔽了ICMP回显, 对于有HTTP服务的服务器, 可以使用-p 指定端口使用TCP协议进行探测traceroute -T -p 80 a.xxx.com (在 macOS上好像不支持-T)
nmap
探测远端机器端口 nmap 192.168.1.1 -p 80
nc
- 接受文件:
nc -4 -l -p local_port > file说明:-4是指IPv4, 如果默认-6有问题就试试这个,-l=listen,-p=port - 发送文件:
nc dest_ip dest_port < file
网卡吞吐量(Throughput)
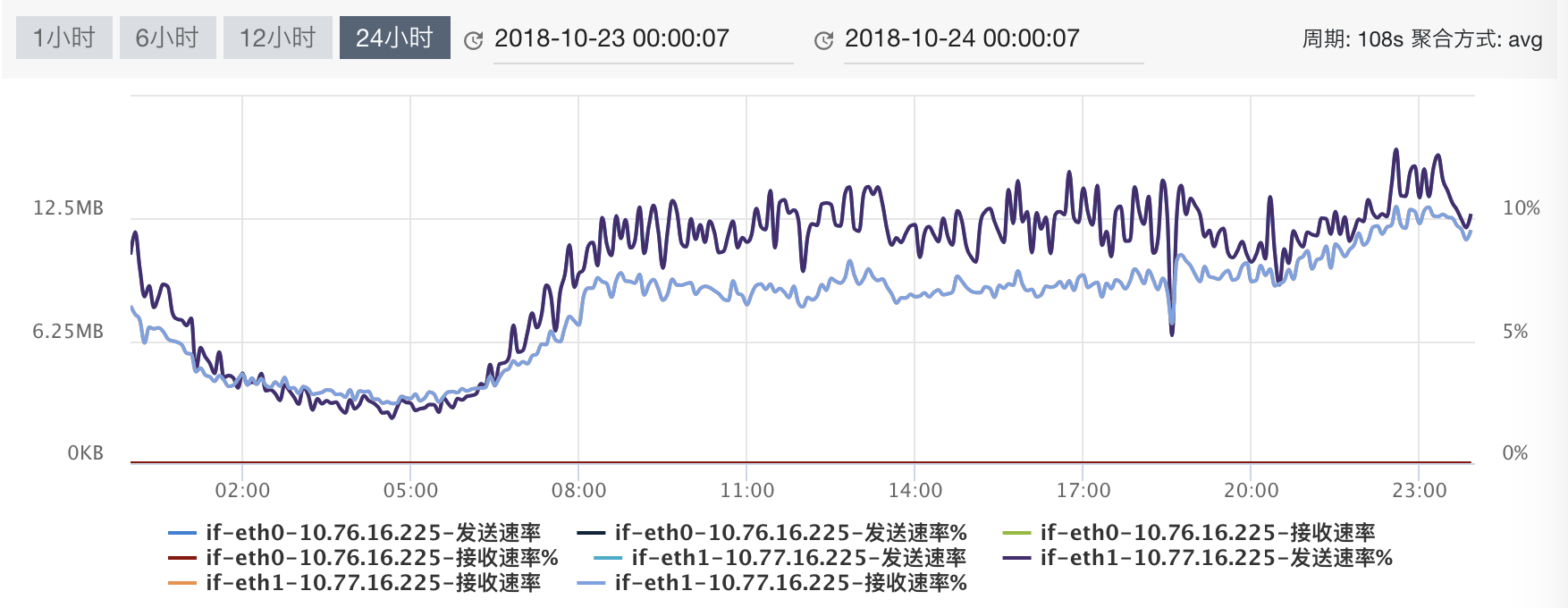
iftop
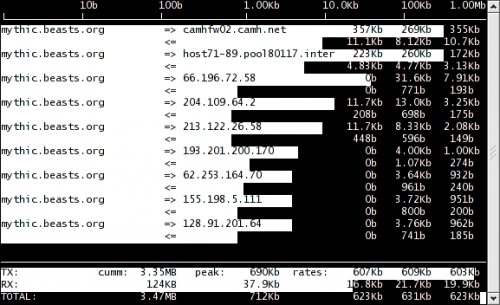
iftop底部会显示一些全局的统计数据,peek 是指峰值情况,cumm 是从运行至今的累计情况,而 rates 表示最近 2 秒、10 秒、40 秒内总共接收或者发送的平均网络流量。
TX: cumm: 143MB peak: 10.5Mb rates: 1.03Mb 1.54Mb 2.10Mb |
iperf
- server:
iperf -s - client:
iperf -c 192.168.0.138 -t 60 -l 8k -i 10#进行60秒测试, 缓冲区大小8k, 每10秒打印一次结果
测试阿里云服务器大约67.5 Mbits/sec, 似乎是Mac无线网卡的限制…内网的两台服务器测试(非同一机房) 450 Mbits/sec
netperf
- server端:
netserver - client端测试tcp:
./netperf -t TCP_STREAM -H 192.168.0.138 -l 60 -- -m 2048# 测试时长60秒, 发送分组大小2048 Bytes - client端测试udp:
./netperf -t UDP_STREAM -H 192.168.0.138 -l 60 -- -m 2048
常用配置文件
性能 & 并发相关
@Ref 参考 → 并发(C10K, C100K)
profile相关
- bashrc是在系统启动后就会自动运行。
- profile是在用户登录后才会运行。
- 进行设置后,可运用source bashrc命令更新bashrc,也可运用source profile命令更新profile。
- /etc/profile: 中设定的变量(全局)的可以作用于任何用户
- ~/.bashrc: 等中设定的变量(局部)只能继承/etc/profile中的变量
- ~/.bash_profile: 每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件。
权限相关
- /etc/sudoers
- /etc/hosts.allow: 限制SSH的客户端IP, /etc/hosts.allow 的设定优先于 /etc/hosts.deny
- /etc/hosts.deny: 限制SSH的客户端IP
网络相关
/etc/resolv.conf: 这个文件是用于配置DNS服务器的, 扩展阅读: Ubuntu使用dnsmasq作本地DNS缓存
nameserver 8.8.8.8
/etc/hosts: 设置主机名和IP地址绑定
- /etc/hostname: 主机名配置
- /etc/sysconfig/network: 主机名和网关
NETWORK=yes #网络是否被配置
RORWARD_IPV4=yes #是否开启IP转发功能
HOSTNAME= localhost.localdomain #表示服务器的主机名
GAREWAY=192.168.0.1 #表示网络网关的IP地址
GATEWAYDEV=eth0 #网关的设备名,即选择使用哪个网卡
内核态和用户态
- CPU的指令分为特权级指令和非特权级指令, 特权级指令通常是一些比较危险的指令, Intel X86架构的CPU将特权等级分为4个级别:
RING0,RING1,RING2,RING3. 操作系统通过区分用户态和内核态来保证特权级指令不被错误的使用. - Linux仅仅使用了RING0和RING3来分别运行内核态和用户态.
用户态到内核态的切换
- 普通程序进行系统API调用时主动要求切换到内核态, 此时用户态进程要向内核态传递参数, 同时保存用户进程的寄存器、变量等, 以便切换回来时能正确继续执行, 这个过程就是进程 上下文切换, 过程如下:
- 保存 CPU 寄存器里原来用户态的指令位
- 为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置
- 跳转到内核态运行内核任务
- 当系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程
- 一次系统调用的过程,其实是发生了两次 CPU 上下文切换。(用户态-内核态-用户态)
- 异常事件:当CPU在执行运行在用户态下的程序时, 发生了某些事先不可知的异常, 这时会触发由当前运行进程切换到处理此异常的内核相关程序中, 也就转到了内核态, 比如缺页异常.
- 硬件中断:当外围设备完成用户请求的操作后, 会向CPU发出相应的中断信号, 这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序, 如果先前执行的指令是用户态下的程序, 那么这个转换的过程自然也就发生了由用户态到内核态的切换
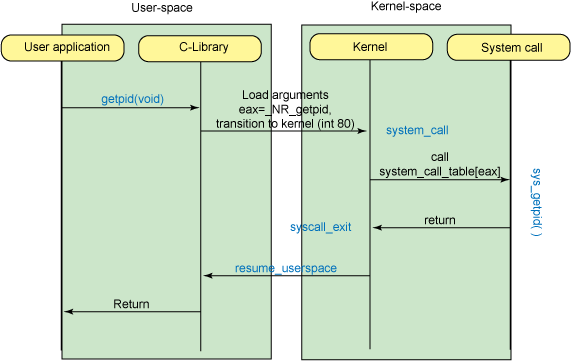
参考: 使用 Linux 系统调用的内核命令 @Ref
Linux网络编程
I/O相关概念
缓存IO(Buffer IO)
- 缓存I/O 又被称作 标准I/O ,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
- 读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。
- 写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
- 缓存I/O的优点:1)在一定程度上分离了内核空间和用户空间,保护系统本身的运行安全;2)可以减少读盘的次数,从而提高性能。
- 缓存I/O的缺点:在缓存 I/O 机制中,DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序地址空间(用户空间)和缓存(内核空间)之间进行多次数据拷贝操作,这些数据拷贝操作所带来的CPU以及内存开销是非常大的。
直接IO(Direct IO)
- 直接I/O 就是应用程序直接访问磁盘数据,而不经过内核缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓存的数据复制。比如说数据库管理系统这类应用,它们更倾向于选择它们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
- 直接IO的缺点:如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓存。通常直接IO与异步IO结合使用,会得到比较好的性能。(异步IO:当访问数据的线程发出请求之后,线程会接着去处理其他事,而不是阻塞等待)
缓存IO vs 直接IO
写场景下的DirectIO和BufferIO: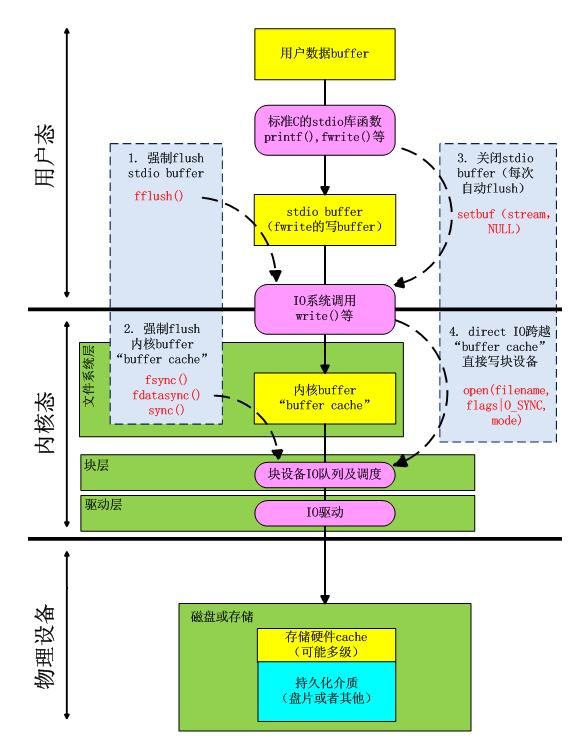
五种I/O模型
- 阻塞IO: 调用read, 如果内核数据未就绪, 调用read的进程进入阻塞状态。应用程序调用一个IO函数,导致应用程序阻塞并等待数据准备就绪。如果数据没有准备好,一直等待。如果数据准备好了,则从内核拷贝到用户空间拷贝数据,IO函数返回成功指示。

- 非阻塞IO: nonblocking IO的特点是用户进程需要不断的主动询问kernel数据是否准备好. 当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误。这样我们的I/O操作函数将不断的测试 数据是否已经准备好,如果没有准备好,继续测试,直到数据准备好为止。在这个不断测试的过程中,会大量的占用CPU的时间。

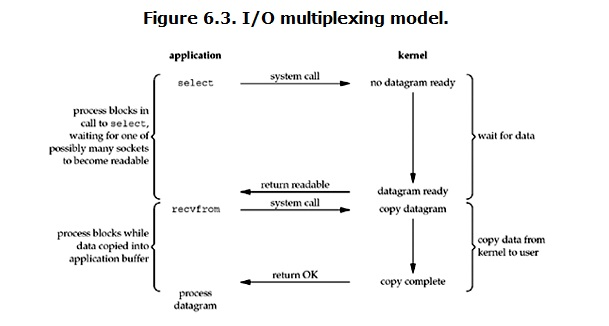
- 多路复用IO: 复用模型会用到select或者poll函数,这两个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。从而使得系统在单线程的情况下可以同时处理多个客户端请求. 与传统的多线程/多进程模型比, I/O多路复用的最大优势是系统开销小。
和阻塞IO模型相比,selectI/O复用模型相当于提前阻塞了。等到有数据到来时,再调用recv就不会因为要等数据就绪而发生阻塞。- select: 一般采用select + no-block, select返回后要遍历所有阻塞在select上的IO句柄,找到数据就绪的那一个IO句柄后, 应用程序调用recvfrom将数据从内核区拷贝至用户区;
- epoll : 比select更高效,无需轮询全部句柄,epoll只返回数据ready的IO句柄
- 信号驱动IO:让内核在数据就绪时用信号SIGIO通知我们,将此方法称为信号驱动I/O。首先,我们允许套接字进行信号驱动I/O,并通过系统调用 sigaction 安装一个信号处理程序。此系统调用立即返回,进程继续工作,它是非阻塞的。当数据报准备好被读时,就为该进程生成一个SIGIO信号。我们随即可以在信号处理程序中调用 recvfrom 来取读数据报。
- 异步IO: 我们让内核启动操作,并在整个操作完成后(包括将数据从内核拷贝到我们自己的缓冲区)通知我们。
调用aio_read函数,告诉内核描述字,缓冲区指针,缓冲区大小,文件偏移以及通知的方式,然后立即返回。当内核将数据拷贝到缓冲区后,再通知应用程序。
上面其它四种模型,至少都会在由kernel copy data to appliction时阻塞。而该模型是当copy完成后才通知application,可见是纯异步的。
很少有*nix系统支持,windows的IOCP(完成端口)则是此模型
高性能I/O设计模式
I/O多路复用模式:Reactor & Proactor
一般地,I/O多路复用机制(I/O multiplexing mechanisms)都依赖于一个事件多路分离器(Event Demultiplexer)。
我们常见的事件多路分用器包括:Linux 的 epoll 和 Windows 的 IOCP。
事件多路分离器(Event Demultiplexer)可将来自事件源的I/O事件分离出来,并分发到对应的 事件处理器 (Event Handler)进行read/write。
开发人员预先注册需要处理的事件及其事件处理器(或回调函数),事件多路分离器 负责将请求事件传递给 事件处理器 。
两个与事件分离器有关的模式是Reactor和Proactor,Reactor模式采用同步IO,而Proactor采用异步IO。
Reactor模式
在Reactor中,事件多路分离器 等待文件描述符状态变为 读写操作准备就绪状态,然后将就绪事件传递给对应的 处理器,最后由 处理器 负责完成实际的读写工作。
Linux epoll使用Reactor模式,Reactor模式使用同步 I/O(一般来说)。Reactor的标准(典型)的工作方式是:
- Reactor线程中, epoll 注册读/写等等事件
- epoll 等待事件到来
- 事件到来,Reactor把事件分发给处理器(往往使用线程池跑处理器)
- 处理器线程: 读写数据(调用read/write, 从内核buff将数据拷贝到用户态buff)
- 处理器线程进行处理(decode数据, 执行业务代码, encode数据)
与 Proactor 模式相比,Reactor 模式下,用户代码的责任是, 在收到可读写事件后进行实际的 I/O 操作。
Proactor模式
而在Proactor模式中,处理器,只负责发起异步读写操作。 处理器 传递给操作系统的参数需要包括 用户定义的数据缓冲区地址 和 数据大小,IO操作本身由操作系统来完成。
当可读写时, 操作系统完成从 内核缓冲区 和 用户定义的数据缓冲区地址 之间的数据拷贝。系统发出IO操作完成事件,由 事件分离器捕获,然后将事件传递给对应 处理器。
比如,在windows上,处理器发起一个异步IO操作,再由事件分离器等待IOCompletion事件。IOCompletion通知的时候, 数据已经被拷贝到处理器的buff了.
典型的异步模式实现,都建立在操作系统支持异步API的基础之上,我们将这种实现称为“系统级”异步或“真”异步,因为应用程序完全依赖操作系统执行真正的IO工作。
Windows IOCP使用Proactor模式,Proactor模式使用异步 I/O。Proactor的标准(典型)的工作方式是:
- 处理器发起异步读操作(注意:操作系统必须支持异步IO)。在这种情况下,处理器无视IO就绪事件,它关注的是完成事件。
- 事件分离器等待操作完成事件
- 在分离器等待过程中,操作系统利用并行的内核线程执行实际的读操作,并将结果数据存入用户自定义缓冲区,最后通知事件分离器读操作完成。
- 事件分离器呼唤处理器。
- 事件处理器处理用户自定义缓冲区中的数据,然后启动一个新的异步操作,并将控制权返回事件分离器。
Proactor 模式下,用户在调用异步 I/O 时会传递一个 Buffer 给系统,系统进行实际的 I/O 操作并从传递给系统的 Buffer 中获取或者放入数据。
以上参考: Reactor VS Proactor 模式 @Ref
两种模式的比较
比较实现
- Reactor实现了一个被动的事件分离和分发模型,服务等待请求事件的到来,再通过不受间断的同步处理事件,从而做出反应;
- Proactor实现了一个主动的事件分离和分发模型;这种设计允许多个任务并发的执行,从而提高吞吐量;并可执行耗时长的任务(各个任务间互不影响)
以主动写为例:
- Reactor将handle放到select(),等待可写就绪,然后调用write()写入数据;写完处理后续逻辑;
- Proactor调用aoi_write后立刻返回,由内核负责写操作,写完后调用相应的回调函数处理后续逻辑;
优势和劣势
√ Reactor优势
- Reactor实现相对简单,对于耗时短的处理场景处理高效;
- 操作系统可以在多个事件源上等待,并且避免了多线程编程相关的性能开销和编程复杂性;
- 事件的串行化对应用是透明的,可以顺序的同步执行而不需要加锁;
- 事务分离:将与应用无关的多路分解和分配机制和与应用相关的回调函数分离开来,
× Reactor劣势
- Reactor处理耗时长的操作会造成事件分发的阻塞,影响到后续事件的处理;
√ Proactor优势
- Proactor性能更高,能够处理耗时长的并发场景;
× Proactor劣势
- Proactor依赖操作系统对异步的支持,目前实现了纯异步操作的操作系统少,比较优秀的如windows IOCP(完成端口),但由于其windows系统用于服务器的局限性,目前应用范围较小;
而Unix/Linux系统对纯异步的支持尚不成熟,应用事件驱动的主流还是通过select/epoll来实现;
适用场景
- Reactor:同时接收多个服务请求,并且依次同步的处理它们的事件驱动程序;
- Proactor:异步接收和同时处理多个服务请求的事件驱动程序;
在实际工程中的使用
- Reactor: libevent / libev /libuv / ZeroMQ / Event Library in Redis
- Proactor: Windows IOCP / Boost.Asio
select vs poll vs epoll
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
epoll
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 |
int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
- epfd:是epoll_create()的返回值。
- op:表示op操作,用三个宏来表示:添加EPOLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOLL_CTL_MOD。分别添加、删除和修改对fd的监听事件。
- fd:是需要监听的fd(文件描述符)
- epoll_event:是告诉内核需要监听什么事件
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
epoll工作模式
epoll对文件描述符的操作有两种模式:LT(level trigger)和ET(edge trigger)。LT模式是默认模式,LT模式与ET模式的区别如下:
- LT模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件。
- ET模式:当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
本章参考
所谓同步,数据从存储介质拷贝到内核缓冲区(数据准备的过程)完成之后,需要用户自己将数据拷贝到用户缓冲区。所以,前4种IO模型都是同步的
Linux I/O 模型的发展技术是: select -> poll -> epoll -> aio -> libevent -> libuv。另外还有 Windows的 Completion Port。
提供一致的接口,IO Design Patterns
实际上,不管是哪种模型,都可以抽象一层出来,提供一致的接口,广为人知的有ACE,Libevent这些,他们都是跨平台的,而且他们自动选择最优的I/O复用机制,用户只需调用接口即可。说到这里又得说说2个设计模式,Reactor and Proactor。有一篇经典文章http://www.artima.com/articles/io_design_patterns.html值得阅读,Libevent是Reactor模型,ACE提供Proactor模型。实际都是对各种I/O复用机制的封装。
常用软件的并发处理
- Nginx:
- 基于epoll监听多个连接(50000个并发连接数的响应), 当某个连接有数据准备好的时候再通知, 这样一个进程能处理多个连接
- 大于5k并发的时候, Nginx才明显比apache有更好的表现
- Redis
- Redis使用单线程的I/O复用模型, 自己封装了一个简单的AeEvent事件处理框架, 主要实现了epoll、kqueue和select.
- 优势: 对于单纯只有I/O操作来说, 单线程可以将速度优势发挥到最大.
- 缺陷:Redis排序、聚合等, 对于这些操作, 单线程模型实际会严重影响整体吞吐量, CPU计算过程中, 整个I/O调度都是被阻塞住的
- Apache: 默认是每个请求启动一个线程处理, 并不适合高并发
- 缺陷:
- 有多少并发就需要多少进程, 最大进程数
- 在进程创建很多的情况下, 系统切换进程的代价很高, 进程运行的时间很少
- 实际上本机处理数据的时间很短, 大多数时间都是在”等待数据准备好”的阶段, 效率低
- 新版的Apache的改进, 支持多种MPM(Multi-Processing Model)
- prefork: 古老
- worker: 多进程(注意并不是每个请求一个线程), 每个进程多个线程
- event: epoll
- 缺陷:
- Tomcat: 每个请求启动一个线程处理
- Tomcat 从 JDK 1.6支持开始支持NIO
多线程 vs 多进程
- 多进程方式:为每个请求启动一个进程来处理.
- 优点: 进程之间是独立的, 单个进程问题不会影响其他进程
- 缺点: 切换进程代价较大, 而且进程间资源是独立的, 造成内存重复利用
- 多线程
- 优点: 线程间部分数据是共享的, 线程间的切换所需资源开销比进程间切换小得多
Linux内存布局
32位:
0xFFFFFFFF 高地址 |
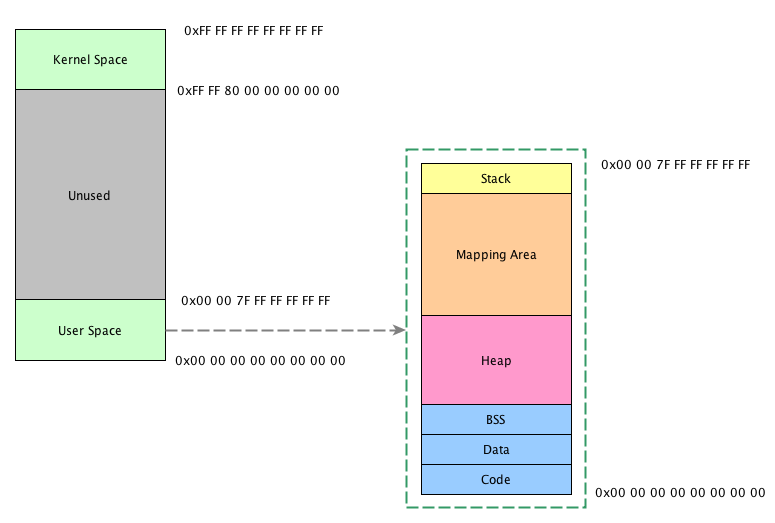
内存布局从高地址到低地址:
Kernel: 内核空间在页表中拥有较高的特权级(ring 2或以下), 因此只要用户态的程序试图访问这些页, 就会导致一个页错误(page fault), 用户程序不可访问内核页Stack: 自高地址向低地址增长, 每个进程都有一个自己的栈, 当不断压栈直到超过了最大的栈空间, 将会引起Stack Overflow, 进程中的每一个线程都有属于自己的栈Memory Mapping Segment: mmap()实现”文件-内存映射”, 它被用于加载动态库, 大多数实际的malloc实现会考虑通过mmap分配较大块的内存区域, 这个区域自高地址向低地址增长Heap: malloc()分配的内存空间, 如果堆中有足够的空间来满足内存请求, 它就可以被语言运行时库处理而不需要内核参与. 否则堆会被扩大, 通过brk()系统调用来分配请求所需的内存块, 堆自低地址向高地址增长BSS Segment: 未赋初始值的static变量, 包括全局的static变量和函数内定义的static变量(全局变量默认就是static)Data Segment: 有初始值的static变量, 程序bin映像的一部分- 还包括一个叫
rodata的区域, 存储”字面量字符串”(包括全局/局部定义的字面量字符串), 以及”const常量”
- 还包括一个叫
Text Segment: 这里存放的是二进制代码
更详细的解释参考@Ref: GNU的obj分析工具的使用(nm, objdump) | 扔掉笔记/)
64位:
64位架构下内存布局与32位类似, 可寻址64TB(Intel架构下是46个地址线, 2^46)
How to 查看某个进程的内存分布
cat /proc/xxx/maps
内存寻址
内存寻址(Memory Addressing):
分段机制把逻辑地址转换为线性地址, 分页机制进一步把该线性地址再转换为物理地址.
段式内存管理
内存可寻址范围总是跟”地址总线宽度”和”寄存器宽度”相关
实模式的诞生(16位处理器及寻址)
- 在8086处理器诞生之前, 内存寻址方式就是直接访问物理地址. 8086处理器为了寻址1M的内存空间, 把地址总线扩展到了20位. 但是, 一个尴尬的问题出现了, ALU的宽度只有16位, 也就是说, ALU不能计算20位的地址. 为了解决这个问题, 分段机制被引入
- 为了支持分段, 8086处理器设置了四个段寄存器:CS, DS, SS, ES每个段寄存器都是16位的, 同时访问内存的指令中的地址也是16位的.
- 在送入地址总线之前(20位), 要将端寄存器(16位)的值与内存地址(16位, 即段内偏移值)相加
- 端寄存器的值左移4位, 低位补0, 然后加上内存地址
+-----------------+ |
保护模式的诞生(32位处理器及寻址)
- 80286处理器的地址总线为24位, 寻址空间达16M, 同时引入了保护模式(内存段的访问受到限制)
- 80386处理器是一个32位处理器, ALU和地址总线都是32位的, 寻址空间达 4G. 也就是说它可以不通过分段机制, 直接访问4G的内存空间. 但它必须支持实模式和保护模式. 所以, 80386在段寄存器的基础上构筑保护模式, 并且保留16位的段寄存器.
- 从80386之后的处理器, 架构基本相似, 统称为IA32(32 Bit Intel Architecture).
IA32的内存寻址机制
IA32的三种地址
- 逻辑地址: 每个逻辑地址都由一个”段的选择符”和”偏移量组成”. IA32中有六个16位段寄存器
- 线性地址:线性地址是一个32位的无符号整数, 可以表达高达2^32(4GB)的地址. 通常用16进制表示线性地址, 其取值范围为0x00000000~0xffffffff.
- 物理地址:也就是内存单元的实际地址, 用于芯片级内存单元寻址. 物理地址也由32位无符号整数表示.
MMU
MMU是一种硬件电路, 它包含两个部件, 一个是分段部件, 一个是分页部件, 在此, 我们把它们分别叫做分段机制和分页机制, 内存寻址分两个步骤:
分段机制把一个逻辑地址转换为线性地, 接着, 分页机制把一个线性地址转换为物理地址.
IA32的段寄存器
IA32中有六个段寄存器(16 bit):CS, DS, SS, ES, FS, GS.
跟8086的段寄存器不同的是, 这些寄存器存放的不再是某个段的基地址, 而是某个段的选择符(Selector).
IA32(硬件)分段机制的实现
段描述符
段是虚拟地址空间的基本单位, 段描述符 是一个8字节的数据结构, 包括以下几个属性:
- 段的界限(Limit):在虚拟地址空间中, 段内可以使用的最大偏移量.
- 段的基地址(Base Address):在线性地址空间中段的起始地址.
- 段的保护属性(Attribute):表示段的特性. 例如, 该段是否可被读出或写入, 或者该段是否作为一个程序来执行, 以及段的特权级等等.

段描述符表
描述符表(即段表)定义了IA32系统的所有段的情况. 所有的描述符表本身都占据一个字节为8的倍数的存储器空间, 空间大小在8个字节(至少含一个描述符)到64K字节(至多含8K)个描述符之间.
总结
IA32的内存寻址机制完成从逻辑地址–线性地址–物理地址的转换. 其中, 逻辑地址的段寄存器中的值提供段描述符, 然后从段描述符中得到段基址和段界限, 然后加上逻辑地址的偏移量, 就得到了线性地址, 线性地址通过分页机制得到物理地址.
首先, 我们要明确, 分段机制是IA32提供的寻址方式, 这是硬件层面的. 就是说, 不管你是windows还是linux, 只要使用IA32的CPU访问内存, 都要经过MMU的转换流程才能得到物理地址, 也就是说必须经过逻辑地址–线性地址–物理地址的转换.
Linux系统(软件)分段机制的实现
Linux基本不使用分段的机制, 或者说, Linux中的分段机制只是为了兼容IA32的硬件而设计的.
在 IA32 上任意给出的地址都是一个虚拟地址, 即任意一个地址都是通过选择符:偏移量的方式给出的, 这是段机制存访问模式的基本特点.
所以在IA32上设计操作系统时无法回避使用段机制. 一个虚拟地址最终会通过段基地址+偏移量的方式转化为一个线性地址.
但是, 由于绝大多数硬件平台都不支持段机制, 只支持分页机制, 所以为了让 Linux 具有更好的可移植性, 我们需要去掉段机制而只使用分页机制. 但不幸的是, IA32规定段机制是不可禁止的, 因此不可能绕过它直接给出线性地址空间的地址.
万般无奈之下, Linux的设计人员干脆让段的基地址为0, 而段的界限为4GB, 这时任意给出一个偏移量, 则等式为0+偏移量=线性地址, 也就是说“偏移量=线性地址”. 另外由于段机制规定“偏移量<4GB”, 所以偏移量的范围为0H~FFFFFFFFH, 这恰好是线性地址空间范围, 也就是说虚拟地址直接映射到了线性地址, 我们以后所提到的虚拟地址和线性地址指的也就是同一地址. 看来, Linux在没有回避段机制的情况下巧妙地把段机制给绕过去了.
特权等级(CPU Rings)和分段机制
由于IA32段机制还规定, 必须为代码段和数据段创建不同的段, 所以Linux必须为代码段和数据段分别创建一个基地址为0, 段界限为4GB的段描述符.
不仅如此, 由于Linux内核运行在特权级0, 而用户程序运行在特权级别3, 根据IA32段保护机制规定, 特权级3的程序是无法访问特权级为0的段的,
所以Linux必须为内核用户程序分别创建其代码段和数据段. 这就意味着Linux 必须创建4个段描述符: 特权级0的代码段和数据段, 特权级3的代码段和数据段
存疑: 在Ring0和Ring3的, 相同的的逻辑地址, 是对应不同的线性地址 [?]
@Ref 参考: Linux内存寻址之分段机制 | ShareHub
页式内存管理
硬件分页
- 分页机制在段机制之后进行, 以完成线性—物理地址的转换过程. 段机制把逻辑地址转换为线性地址, 分页机制进一步把该线性地址再转换为物理地址.
- 分页机制管理的对象是固定大小的存储块, 称之为页(page). 分页机制把整个线性地址空间及整个物理地址空间都看成由页组成, 在线性地址空间中的任何一页, 可以映射为物理地址空间中的任何一页, 我们把物理空间中的一页叫做页框(page frame)
- 80386使用4K(0xFFF)字节大小的页. 每一页都有4K字节长, 并在4K字节的边界上对齐(即每一页的起始地址都能被4K整除). 因此, 80386把最大可寻址4G字节的线性地址空间划分为1M个Page
线性地址的page, 与物理地址的page是多对一的关系, 也就是两个不同线性地址页, 可能指向同一个物理地址页
两级分页
- 页目录(Page Directory): 两级表结构的第一级称为
页目录, 页目录占用4K字节, 正好一个页面. 页目录表共有1K个表项, 每个表项为4个字节, 这4字节是指向二级页表的地址.- 线性地址的最高10位用来作为第一级的索引(所以共2^10=1K个索引)
- 页表(Page Table): 两级表结构的第二级称为
页表, 也刚好存储在一个4K字节的页面中, 包含1K个字节的表项, 每个表项包含一个页的物理基地址.- 线性地址的中间10位用来作为第二级的索引进行索引,
- 以获得包含页的物理地址的页表项, 这个物理地址的高20位与线性地址的低12位形成了最后的物理地址, 也就是页转化过程输出的物理地址.
[未整理完]
@Ref 参考: Linux内存寻址之分页机制 | ShareHub
进程控制
创建进程
fork
- 返回0: 子进程
- 返回>0: 父进程, 返回值是子进程pid
- 子进程会得到父进程的堆(IO缓存, malloc的内存)、栈(局部变量)、数据空间(Data Segment)的拷贝, 在子进程里修改这些变量并不会影响父进程中的值, 注意这种拷贝是“写时复制”(Copy On Write,COW);
- fork前打开的文件句柄, 其偏移量会在父子进程间共享, 原因是进程内存中仅保存了文件句柄的fd指针, 指针指向的结构体(也就是文件表,保存了文件标准和位移)是共享的. @Uncertain 那么”文件表”是存储在哪里的?
- 另外需要注意的是, 因为堆内存也将被拷贝(IO缓存在堆里), 所以如果在创建子进程之前这个IO缓存中就有数据, 那么也会带入子进程, 导致子进程的IO缓存里”多”出一些数据.
int main() |
vfork
- 返回值同 fork
- 不同点1: vfork创建的子进程与父进程共享数据段, 在子进程中修改变量也会影响到父进程中的变量
- 不同点2: vfork的子进程优先于父进程执行, 当子进程明确
_exit()或者exit()之后, 父进程才会继续执行.
终止进程
- 正常三种: return 语句, exit() 或 _exit(),
- 非正常: abort(), 调用该函数之后, 调用者会收到 SIGABRT
wait/waitpid
pit_t wait(int *status): 父进程调用后立刻阻塞, 直到第一个子进程结束, 子进程结束后系统会发送SGICHLD信号, 收到这个信号后, 父进程从wait返回pid_t waitpid(pid_t pid, siginfo_t *infop, int options), 等待指定的进程
exec
fork 或者 vfork之后往往需要再调用 exec启动另一个新程序, 因为 exec不创建新进程, 所以pid不会变, 原程序的 Text Seg, Data Seg, Heap/Stack会被替换
僵尸进程和孤儿进程
- 僵尸进程(zombie process): ps显示stat为”z”的进程
- 产生原因: 子进程退出后(exit, 或发生错误), 子进程仍存在于进程表, 当父进程调用wait之后才会从进程表删除. 如果子进程死掉但是父进程没有调用wait, 子进程就变成了僵尸进程;
- 正确做法: 子进程死后, 系统会向父进程发生SIGCHLD信号, 父进程收到此信号后应该用wait处理子进程;
- 如果父进程没有处理SIGCHLD信号, 那么只能kill父进程, 让init成为子进程的父进程, init进程会周期性调用wait清理Zombie进程.
- 处理SIGCHLD信号示例代码: https://docs.oracle.com/cd/E19455-01/806-4750/signals-7/index.html
- 孤儿进程(orphan process): 父进程死掉, 子进程被init进程接管
- 守护(Daemon)进程: 守护进程就是后台服务进程, 因为它会有一个很长的生命周期提供服务, 关闭终端不会影响服务, 也就是说可以忽略某些信号
- 如何实现Deamon进程:
- 父进程exit
- command &
- nohup command
- 如何实现Deamon进程:
守护进程(daemon)
Linux 守护进程原理及实例(Redis、Nginx) - CSDN博客
- 守护进程不属于任何一个控制终端, 不属于任何一个会话(Session)
- 守护进程没的父进程是0 @Uncertain
- 守护进程会忽略一些signal(包括处理信号SIGHUP(进程和控制终端分离时收到SIGHUP)、 SIGTERM(系统关机之前收到SIGTERM)
进程间通信(IPC)
本章参考:
- 深刻理解Linux进程间通信(IPC) @Ref
进程间通信(IPC)= InterProcess Communication,
POSIX标准的IPC包括:
- 管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
- 信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。 - 共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
- 信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
- 套接字(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
管道
Linux上的管道分两种类型: 匿名管道、命名管道
- 匿名管道(PIPE):
- 最常见的形态就是我们在shell操作中最常用的”|”
- 只能在父子进程中使用
- 系统调用:
int pipe(int pipefd[2])
- 命名管道(FIFO):
- 命名管道在底层的实现跟匿名管道完全一致,区别只是命名管道会有一个全局可见的文件名以供别人open打开使用
- 系统调用:
int mkfifo(const char *pathname, mode_t mode)
共享内存
信号
kill -l 可以查看所有支持的信号和其对应值, 产生信号有下面几种方式:
- 用户按键产生信号
- Ctrl-C : SIGINT, 中断(Interrupt), 只能向前台进程发送, 可忽略
- Ctrl-\ : SIGQUIT, 退出(Quit), 可忽略
- Ctrl-Z : SIGSTP, 停止(Stop), 挂起的进程可以fg恢复
- 硬件产生信号
- 除0: SIGFPE, CPU运算单元产生异常并发送给进程,
- 内存非法访问: SIGSEGV, 内存控制单元MMU产生
kill()函数产生信号kill: SIGTERM, 可被忽略kill -2: SIGINT, 同Ctrl-Ckill -9: SIGKILL, 不可忽略, 但导致进程无法完成清理?kill -17: SIGCHLD, 子进程死掉, 系统会向父进程发生SIGCHLD信号, 父进程可以选择是否处理SIGCHLD: 子进程死掉, 系统会向父进程发生SIGCHLD信号, 父进程可以选择是否处理SIGHUP: 在终端启动一个回话(session), 在这个终端里再启动的命令, 都是这个回话的子进程, 如果回话进程关闭, SIGHUP会被发送到所有子进程
进程状态 R S D T X Z:
R: Running
S: Interruptible Sleep, 可中断的睡眠
D: Uninterruptible Sleep. 不可中断的睡眠, 比如等待磁盘IO, 这种进程不接受kill,kill -9的信号
T: Stoped, 按下Ctrl+Z的状态
Ctrl+z 和Ctrl+c
- 前者是SIGTSTP(挂起进程), 后者是SIGINT(中断进程), 进程接受SIGTSTP后, 用
bg 1可以让被挂起的程序在后台继续执行, 命令中的”1”是job(作业号); 命令fg 1重新让进程切换到前台运行. 命令jobs查看在后台运行的任务. - SIGHUP信号和screen: http://www.ibm.com/developerworks/cn/linux/l-cn-screen/
进程间通信
- Linux环境进程间通信(二): 信号(上) @Archived
- Linux环境进程间通信(二): 信号(下) @Archived
init系统
init进程是 Linux系统内核初始化最后一步启动的进程,也是系统的第一个进程,pid=1。
运行级别(Runlevel)指的是Unix或者Linux等类Unix操作系统下不同的运行模式。运行级别通常分为7等,分别是从0到6,但如果必要的话也可以更多。
例如在大多数Linux操作系统下一共有如下7个典型的运行级别:
0 停机,关机
1 单用户,无网络连接,不运行守护进程,不允许非超级用户登录
2 多用户,无网络连接,不运行守护进程
3 多用户,正常启动系统
4 用户自定义
5 多用户,带图形界面
6 重启
除了模式 0,1,6外, 每种 Unix 和 Unix-like 系统对运行模式的定义不太一样。通常在 /etc/inittab 文件中定义了各种运行模式的工作范围。
当前绝大多数Linux发行版已经基于新的systemd,systemd一般不再使用/etc/inittab文件。
init,sysvinit 和 systemd
大多数 Linux 发行版的 init 系统是和 System V 相兼容的,被称为 sysvinit。这是人们最熟悉的 init 系统。
Ubuntu 采用 upstart 替代了传统的 sysvinit,
RHEL 采用 systemd替代 sysvinit。
sysvinit
本节参考:
sysvinit 运行顺序
- 读取 /etc/inittab, 获取配置(系统的 runlevel 等)
- /etc/rc.d/rc.sysinit
- /etc/rc.d/rc 和 /etc/rc.d/rcX.d/ (X 代表运行级别 0-6)
- /etc/rc.d/rc.local
sysvinit 管理功能
sysvinit 软件包包含了一系列的控制启动、运行和关闭所有其他程序的工具:
- init: 这个就是 sysvinit 本身的 init 进程实体,以 pid1 身份运行,是所有用户进程的父进程。最主要的作用是在启动过程中使用/etc/inittab 文件创建进程。
- halt: 停止系统
- poweroff: 等于 shutdown -h –p
- reboot: 等于 shutdown –r
- killall: 向除自己的会话(session)进程之外的其它进程发出信号,所以不能杀死当前使用的 shell。
- last: 回溯/var/log/wtmp 文件(或者-f 选项指定的文件),显示自从这个文件建立以来,所有用户的登录情况。
- chkconfig: RHEL 在 sysvinit 的基础上开发的命令行工具
- service: 同上
使用 sysvinit 启动一个服务:
/etc/init.d/apache2 start |
这种方法有两个缺点。
- 一是启动时间长。init进程是串行启动,只有前一个进程启动完,才会启动下一个进程。
- 二是启动脚本复杂。init进程只是执行启动脚本,不管其他事情。脚本需要自己处理各种情况,这往往使得脚本变得很长。
Systemd 就是为了解决这些问题而诞生的。它的设计目标是为系统的启动和管理提供一套完整的解决方案。
systemd
本节参考:
Systemd 入门教程:命令篇 - 阮一峰的网络日志 @Ref
浅析Linux初始化init系统, 第3部分: Systemd @Ref
systemctl 命令
systemctl是 Systemd 的主命令,用于管理系统。//区别 sysctl 命令,用于修改 Kernel参数
重启系统 |
Systemd 可以管理所有系统资源。不同的资源统称为 Unit(单位)。相关命令:
列出正在运行的 Unit |
启动、重启、停止Unit:
立即启动一个服务 |
Example: How to 新加一个 Service(Systemd Unit):
vim /etc/systemd/system/ngx-example.service |
Systemd 默认从目录/etc/systemd/system/读取配置文件。但是,里面存放的大部分文件都是符号链接,指向目录/usr/lib/systemd/system/,真正的配置文件存放在那个目录。
systemctl enable命令用于在上面两个目录之间,建立符号链接关系。
Description=proxy-nginx |
journalctl 日志系统
本节参考:
Systemd 使用 journald 做日志中心库,使用 rsyslog 来持久化日志,使用 logrotate 来轮转日志文件。
Systemd日志收集流程: systemd --> systemd-journald --> ram DB(/run/log/journal) --> rsyslog -> /var/log/messages;
对比 init日志收集: service daemon ---> rsyslog ---> /var/log
journald
journald是 Systemd自带日志服务,journald用二进制格式保存所有日志信息,用户使用 journalctl 命令来查看日志信息。
配置文件位置: cat /etc/systemd/journald.conf
使用journalctl命令查看日志:
- journalctl: 显示所有的日志信息,notice或warning以粗体显示,红色显示error级别以上的信息
- journalctl –dmesg: 查看 dmesg 信息。
- journalctl -k: 查看 kernel 日志。
- journalctl -f: 很像tailf命令
- journalctl –since=yesterday: 指定时间段
- journalctl -u docker.service: 指定服务,查看docker服务的 journal 日志。查看所有service列表使用命令
systemctl list-units - journalctl _PID=8088: 查看指定pid的
- journalctl _UID=33: 查看指定用户的
- journalctl /usr/bin/bash: 查看某个路径的脚本的日志
- journalctl –verify: 检查日志文件的一致性
例如,docker daemon会配置为将所有容器的日志为存储到 journald。/usr/bin/docker-current daemon --exec-opt native.cgroupdriver=systemd --selinux-enabled --log-driver=journald
所以,运行中 docker的日志,例如 k8s的 apiserver都会打到 journald日志里去(最终输出到 /var/log/messages)
rsyslog
rsyslog用来固化journald日志。rsyslog读取 ram DB(/run/log/journal)的数据,并根据优先级排列日志信息,将它们写入到 /var/log目录中永久保存。
默认 journald配置
#ForwardToSyslog=no,所以并未将日志转发给syslog。syslog自己去读取的 journald的日志文件(类似journalctl)。
logrotate
rsyslog的日志存储于/var/log下,显然日志文件不能无限变大,否则磁盘空间会被耗尽。RHEL7使用logrotate来做日志文件轮转。
配置文件位置: cat /etc/cron.daily/logrotate
用户和用户组
用户组
几个常见的用户组: adm/daemon/bin :
- root:超级用户, 就是管理员, 拥有所有权限
- bin:历史遗留用户
- daemon:守护进程, 非特权的, 需要对一些以磁盘文件有写权限的daemon以daemon.daemon(portmap,atd,etc)运行;不需要占有任何文件的daemon 以nobody.nogroup运行;比较复杂的, 涉及安全问题的daemon以特定的用户运行. daemon用户也方便本地安装的daemon运行.
- adm:adm组执行系统监控任务, 组成员可以读取/var/log下的多数文件, 可以使用xconsole. 历史上/var/log来自于/usr/adm, 后来叫/var/adm, 这也是组名称的由来.
- apache/_www: 用root启动httpd服务, apache的子进程还是用apache(或者_www用户)运行的, 可以通过修改
/etc/httpd/conf/httpd.conf指定apache运行的用户组.
更改用户&用户组常用命令:
usermod -a -G daemon XYZ将用户XYZ加入一个组id,whoami:who:useradd,userdel
权限最小原则
待补充:p
设置安全的PHP+Apache
原则: apache/nginx 和网站文件根目录的所有者(一般是FTP用户)不能是同一个, Apache用户只能有网站目录的rx权限.
对于某些特殊目录, 要求apache能有写入权限, 比如:
- 缓存目录(比如discuz的forumdata), 该目录下有php,js,css等文件, php文件不允许用户(通过apache用户)访问, js和css可以允许用户访问. 可以通过apache的配置拒绝访问.
- 上传目录, 可以为777, 设置不允许解析目录下的php文件.
- 日志目录, 可以为777, 设置不允许解析目录下的php文件.
参考:
文件权限
chmod 400 ~/.ssh/authorized_keyschmod u=rw,g=r,o= /var/filename同chmod 640chmod -R o-r /home/*把其他用户的读权限都去掉. chmod支持+,-,=符号.
给某个文件755权限, 能正常访问的前提是其父目录要有x权限, 至少能进入父目录
crontab
* * * * * * cmd, 分别表示每分/时/每月第几日/月/周几(0~6)
- 每5分钟:
*/5 * * * * - 每小时:
0 * * * * - 每天早上6点10分
10 6 * * * - 晚上11点到早上8点之间每两个小时, 和早上8点:
0 23-7/2, 8 * * *
每个用户的crontab文件在 /var/spool/cron/
终端Terminal
- Ctrl+r搜索, 输入, 按Ctrl+r继续搜索
- Ctrl+a / Ctrl+e : 移动光标开头/末尾m