
前言
NoSQL 数据库的出现主要是解决了关系型数据库中的各种问题。第一个大问题就是数据的 Schema 非常多,用关系型数据库来表示不同的 Data Schema 是非常笨拙的,所以要有不同的数据库(如时序型、键值对型、搜索型、文档型、图结构型等)。另一个大问题是,关系型数据库的 ACID 是一件很讨厌的事,这极大地影响了数据库的性能和扩展性,所以 NoSQL 在这上面做了相应的妥协以解决大规模伸缩的问题。
NoSQL数据库的几大类别:
- 列数据库 (Column Database): HBase
- 文档数据库(Document Datebase): Mongo
- 数据结构数据库(Datastructure Database): Redis
- 图数据库: Graph platform
命令行
- 连接本地:
redis-cli -p 6379 - 连接远程:
redis-cli -h host -p port -a pwd
以下参考: http://redisdoc.com/index.html
sys/info类命令
SELECT: 选择数据库, 比如SELECT 0选择0号数据库(默认的)INFO: 返回信息, 参考: http://redisdoc.com/server/info.html @RefMONITOR: 可以看到实时的查询信息(查询来源IP.), 注意这个命令对性能有影响DBSIZE: 返回当前库Key的数量FLUSHDB/FLUSHALL: 清空当前库, 清空整个Redis的数据CLIENT LIST: 获取连接到服务器的客户端连接列表CLIENTKILL [ip:port] [ID client-id]: 关闭客户端连接CONFIG GET *获取所有参数CONFIG SET 参数 值BGSAVE: 异步持久化, 不要用SAVE!
慢查询
SLOWLOG GET 1000: 获取1000条慢查询SLOWLOG RESET可以清空 slow logCONFIG GET slowlog-log-slower-than获取慢查询设置, 单位是微秒, 默认10,000(10毫秒), 超过10毫秒需关注CONFIG SET slowlog-log-slower-than 10000
key类命令
TYPE key返回 key 所储存的值的类型。DEL key [key ...]: 删除给定的一个或多个 key 。时间复杂度:O(N), N 为被删除的 key 的数量EXISTS key: 检查给定 key 是否存在RANDOMKEY: 从当前数据库中随机返回(不删除)一个 key 。KEYS pattern: 查找所有符合给定模式 pattern 的 key(慎用!) 。时间复杂度: O(N), N 为数据库中 key 的数量。KEYS *匹配数据库中所有 key 。KEYS h?llo匹配 hello , hallo 和 hxllo 等。
SCAN 0增量迭代式获取,返回的游标被用作下一次SCAN X,每次执行都只会返回少量元素, 所以可以用于生产环境SORT key DESC: 返回键值从大到小排序的结果。EXPIRE key seconds: 为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除。- 生存时间可以通过使用 DEL 命令来删除整个 key 来移除,或者被 SET 和 GETSET 命令覆写(overwrite)
- 对一个 key 执行 INCR 命令,对一个列表进行 LPUSH 命令,或者对一个哈希表执行 HSET 命令,这类操作都不会修改 key 本身的生存时间。
TTL key: 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
数据结构
Redis是一个K-V的数据库,“V” 的数据类型分为:String、Hash、List、Set、Sorted Set。
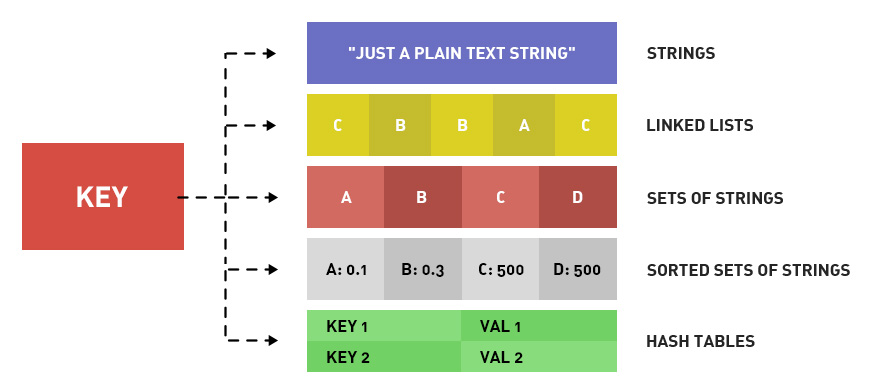
String
String 数据结构是简单的 key-value 类型,value 不仅可以是 String,也可以是数字(当数字类型用 Long 可以表示的时候encoding 就是整型,其他都存储在 sdshdr 当做字符串)。
sds是在Redis中被广泛使用的字符串结构,它的全称是Simple Dynamic String。参考 Redis内部数据结构详解(2)——sds @Ref
String命令
String相关命令包括 SET/GET类命令,对字符串的值APPEND/SETRANGE操作,还包括 同时设置值和过期时间的原子操作SETEX,但是其他数据类型没有类似SETEX的原子操作。
SET key value:设置key关联的字符串GET key:返回key关联的字符串APPEND key value:在字符串后追加valueSTRLEN key: 返回字符串长度SETRANGE key 0 "xxx": 把key对应的字符串从0开始,用“xxx”覆盖。时间复杂度O(M), M 为 value 参数的长度。INCR key:将 key 中储存的数字值+1,数字范围是有符号longINCRBY key increment:将 key 所储存的值加上增量 incrementDECR key:将 key 中储存的数字值减一。DECRBY by decrement:将 key 所储存的值减去减量 decrement 。
过期时间:
SETEX key seconds value:将值 value 关联到 key ,并将 key 的生存时间设为 seconds (以秒为单位)。 SETEX 是一个原子性(atomic)操作
批量操作:
MGET key1 key2:返回所有(一个或多个)给定 key 的值。时间复杂度O(N) ,N 为给定 key1..key2 的数量。MSET key1 value2 key1 value2: 设置key1…key2对应的字符串。时间复杂度:O(N), N 为要设置的 key 数量。
BIT操作:
SETBIT key offset value:对key所储存的字符串值,设置或清除指定偏移量上的位(bit),value只能是0或1,offset小于2^32(512MB)GETBIT key offset:返回offset位上的值(0/1)BITCOUNT key: 计算给定字符串中,被设置为 1 的比特位的数量。
String的实现
@TODO
HashMap
字典实现,key对应的内容是由field-value组成的键值对。
HashMap命令
HashMap相关命令常规的字典操作,
HSET key field value:将哈希表 key 中的域 field 的值设为 value,O(1)HGET key field:返回哈希表 key 中给定域 field 的值。HKEYS key:返回哈希表 key 中的所有域。时间复杂度:O(N), N 为哈希表的大小。HGETALL key:返回哈希表 key 中所有的域和值。时间复杂度:O(N), N 为哈希表的大小。HVALS key:返回哈希表 key 中所有域的值。时间复杂度:O(N), N 为哈希表的大小。HEXISTS key field:查看哈希表 key 中,给定域 field 是否存在。HSCAN key cursor:命令用于迭代哈希键中的键值对。具体信息请参考 SCAN 命令。HDEL key field [field ...]:删除哈希表 key 中的一个或多个指定域,不存在的域将被忽略。时间复杂度:O(N), N 为要删除的域的数量。HLEN key: 返回键值对数量HINCRBY key field increment:为哈希表 key 中的域 field 的值加上增量 increment 。
批量操作:
HMSET key field1 value1 field2 value2: 同时将多个 field-value (域-值)对设置到哈希表 key 中。O(N), N 为 field-value 对的数量。HMGET field1 field2: 返回哈希表 key 中,一个或多个给定域的值。O(N), N 为 field-value 对的数量。
HashMap的实现
@TODO
List
双端队列
List命令
队列的L/R端的POP和PUSH操作:
LPOP key:移除并返回列表 key 的头元素。LPUSH key value [value ...]:将一个或多个值 value 插入到列表 key 的表头RPUSH key value [value ...]:将一个或多个值 value 插入到列表 key 的表尾(最右边)。RPOP key:移除并返回列表 key 的尾元素。LLEN key:返回列表 key 的长度。
随机查询 & 插入:
LINDEX key index:返回列表 key 中,下标为 index 的元素。时间复杂度:O(N), N 为到达下标 index 过程中经过的元素数量。LINSERT key BEFORE|AFTER pivot value:将值 value 插入到列表 key 当中,位于值 pivot 之前或之后。时间复杂度:O(N), N 为寻找 pivot 过程中经过的元素数量。LINSERT mylist BEFORE "World" "There":会先在List寻找”World”,找到后在”World”之前插入”There”
阻塞L/R端弹出:
BLPOP key [key ...] timeout:BLPOP 是列表的阻塞式(blocking)弹出原语。它是 LPOP 命令的阻塞版本,当给定列表内没有任何元素可供弹出的时候,连接将被 BLPOP 命令阻塞,直到等待超时或发现可弹出元素为止。BRPOP key [key ...] timeout:参考如上
List的实现
@TODO
Set
Set(集合):不重复
Set命令
SADD key v1 v2:添加多个值到集合key之中,时间复杂度:O(N), N 是被添加的元素的数量。SPOP key:移除并返回集合中的一个随机元素。SMEMBERS key:返回集合 key 中的所有成员。时间复杂度:O(N), N 为集合的元素数量。SSREM key member [member ...]:移除集合 key 中的一个或多个 member 元素,时间复杂度:O(N), N 为给定 member 元素的数量。SISMEMBER key member:判断 member 元素是否集合 key 的成员。时间复杂度:O(1)SCARD key:返回集合中元素的数量。时间复杂度:O(1)SSCAN key cursor:详细信息请参考 SCAN 命令。
交并集:
SINTER key1 [key ...]:返回交集成员的列表,时间复杂度为O(N * M), N 为给定集合当中基数最小的集合, M 为给定集合的个数。SUNION key [key ...]返回一个集合的全部成员,该集合是所有给定集合的并集。时间复杂度为O(N), N 是所有给定集合的成员数量之和。
Set的实现
@TODO
Sorted Set
Sorted Sets是将 Set 中的元素增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列
Sorted Set命令
ZADD key score member [[score member] [score member] ...]:将一个或多个 member 元素及其 score 值加入到有序集 key 当中。时间复杂度:O(M*log(N)), N 是有序集的基数, M 为成功添加的新成员的数量。ZSCORE key member:返回有序集 key中,成员 member的 score值。时间复杂度:O(1)ZRANGE key start stop:返回有序集 key中指定区间内的成员。其中成员的位置按 score值递增(从小到大)来排序。复杂度:O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数。ZINCRBY key increment member:为有序集 key的成员 member的 score值加上增量 increment。时间复杂度:O(log(N))ZREVRANK key member:返回有序集 key中成员 member的排名,score 值最大的成员排名为 0 。复杂度O(log(N))ZCOUNT key min max: 返回有序集 key 中, score值在 min和 max之间(默认包括)的成员的数量。时间复杂度:O(log(N)), N 为有序集的基数。ZCARD key:返回key对应的集合的长度。
Sorted Set的实现
简化的 SkipList结构模型(横向每层都是一条链表, 层数从上到下 n-1):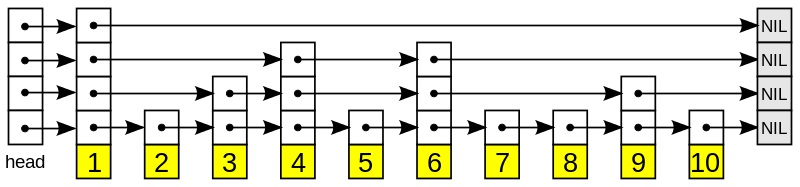
@Q Redis zset的实现?
▶ 插入一个Key, 首先计算在哪一层插入, 层数的计算代码:
|
跳表最上层(最稀疏)是第1层, 层数初始值=1,random()&0xFFFF 表示在 0 ~ 0xFFFF范围内随机数,
如果随机数出现在 0 ~ ZSKIPLIST_P * 0xFFFF, 则层数++, 所以每次循环中层数++的概率是 ZSKIPLIST_P, 这里是 0.25,
所以, 层数i = 1,2,3,… 的概率分别是 3/4, 1/4 * 3/4, 1/4 * 1/4 * 3/4, 每加一层, 出现在该层的概率就乘以 0.25,
简化一下:
- 节点层数恰好等于1的概率为 $ 1-p $
- 节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为 $ p(1-p) $
- 节点层数大于等于3的概率为p2,而节点层数恰好等于3的概率为 $ p^2(1-p) $
- 节点层数大于等于4的概率为p3,而节点层数恰好等于4的概率为 $ p^3(1-p) $
▶ 复杂度分析: @TODO
▶ 占用空间分析: @TODO
Redis SkipList实际内存模型: (下面的例子 用Zset 保存”姓名-分数”, 插入样例数据 ZADD Charles 65.5 David 78.0 Alice 87.5, 实际存储如下)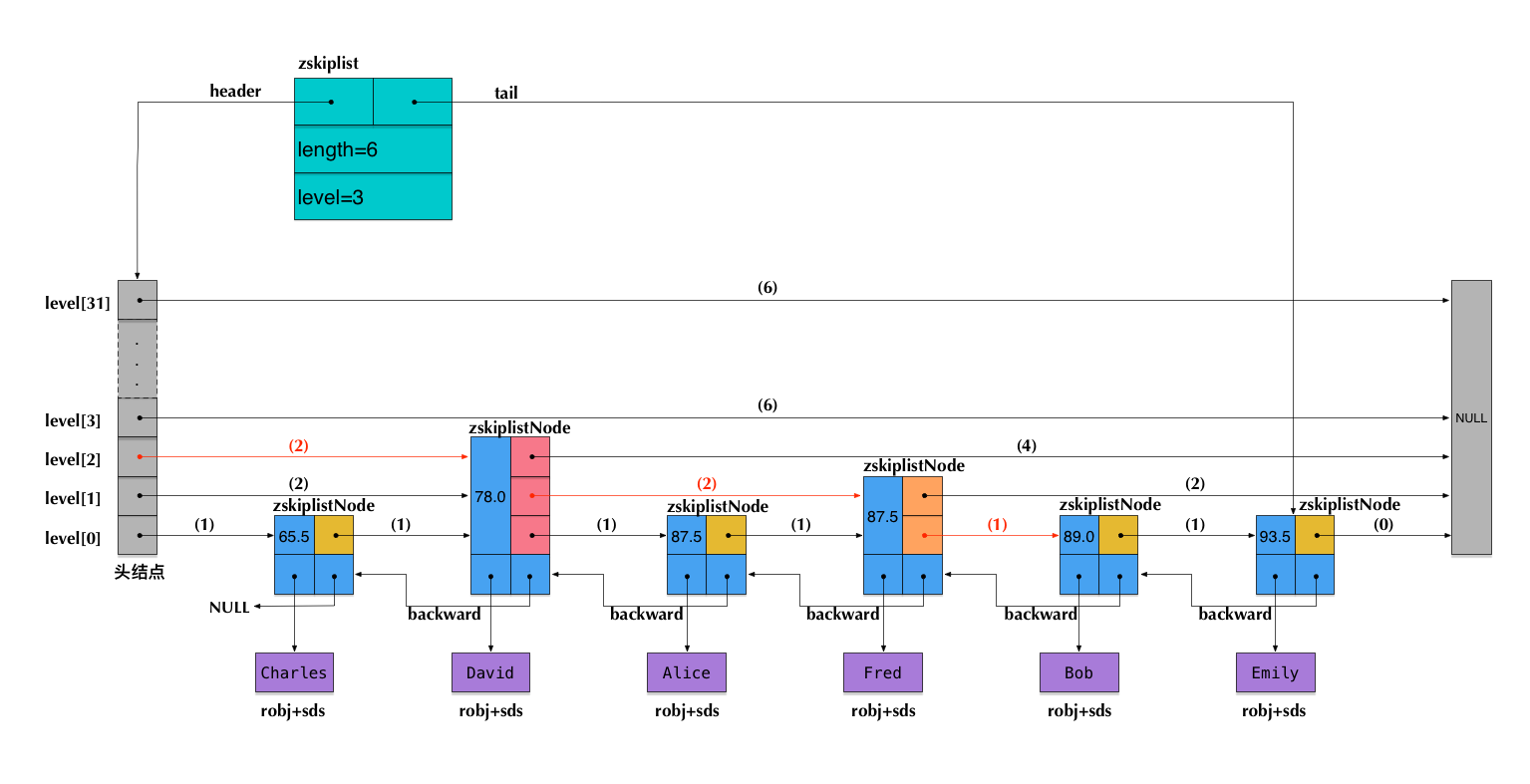
▶ 参考:
持久化
Redis 分别提供了 RDB 和 AOF 两种持久化模式
RDB: http://redisbook.readthedocs.io/en/latest/internal/rdb.html
- 在不同的时间点,将redis存储的数据生成快照并存储到磁盘等介质上;
- 对于RDB方式,redis会单独创建(fork)一个子进程来进行持久化,而主进程是不会进行任何IO操作,保证性能
- 在默认情况下, Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。你可以对 Redis 进行设置, 让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时, 自动保存一次数据集。你也可以通过调用 SAVE 或者 BGSAVE , 手动让 Redis 进行数据集保存操作。
AOF: https://redisbook.readthedocs.io/en/latest/internal/aof.html
- Append Only File,即只允许追加不允许改写的文件
- AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
- AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
RDB-AOF混合持久化: Redis 4.0 新功能简介:RDB-AOF 混合持久化 — blog.huangz.me
集群
官方方案(Redis Cluster)
对客户端来说,整个cluster被看做是一个整体,客户端可以连接任意一个node进行操作,就像操作单一Redis实例一样,当客户端操作的key没有分配到该node上时,Redis会返回转向指令,指向正确的node,这有点像浏览器页面的302 redirect跳转。客户端不需要连接集群所有节点,只要连接集群中任意一个节点即可。
- Redis Cluster中,Sharding采用slot(槽)的概念,一共分成16384个槽,这有点儿类pre sharding思路。
- 对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。
CRC16(key)%16384计算Key属于哪个槽 - Redis集群中的每个node(节点)负责分摊这16384个slot中的一部分。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。
- 为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。
- 如果主节点失效,Redis Cluster会根据选举算法从slave节点中选择一个上升为主节点。这非常类似前篇文章提到的Redis Sharding场景下服务器节点通过Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
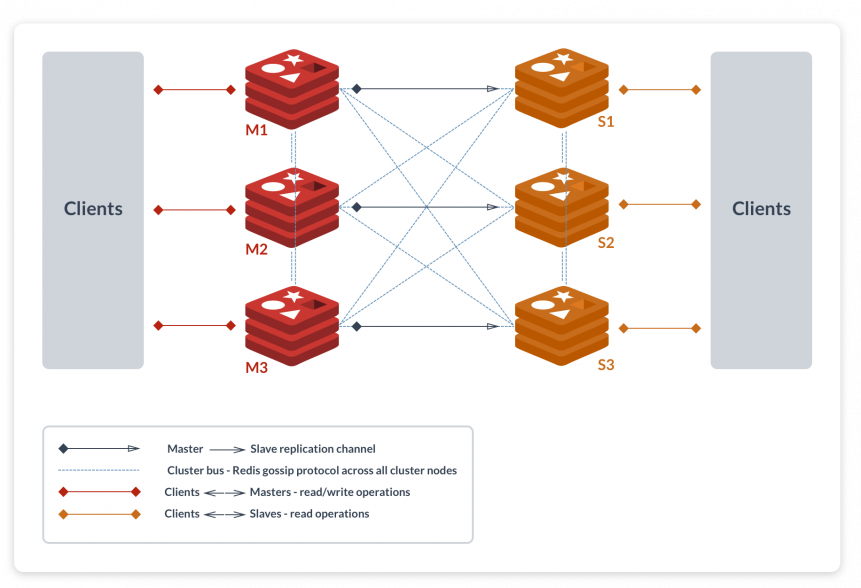
Cluster架构细节
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽
- 节点的fail是通过集群中超过半数的节点检测失效时才生效.
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
- cluster 负责维护槽对应哪个节点
- Redis投票机制:
- Redis集群中每一个节点都会参与投票,如果当半数以上的节点认为一个节点通信超时,则该节点fail。
- 当集群中任意节点的master(主机)挂掉,且这个节点没有slave(从机),则整个集群进入fail状态。
集群安装
- 使用redis-trib.rb创建集群
redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 - 添加主节点:
redis-trib.rb add-node 127.0.0.1:7007 127.0.0.1:7001 - 当添加了一个主节点后,需要重新分配哈希槽:
redis-trib.rb reshard 127.0.0.1:7001 - 添加从节点, 添加一个port为7008的Redis实例做为7007的从节点:
redis-trib.rb add-node --slave --master-id cad9f7413ec6842c971dbcc2c48b4ca959eb5db4 127.0.0.1:7008 127.0.0.1:7001- 注: 主节点id可以在client中使用
cluster nodes命令查询。
- 注: 主节点id可以在client中使用
- 删除节点:
redis-trib.rb del-node 要删除的节点的ip和端口 节点id
扩容
只需要把改变的槽移动到新的节点上
分片方案(Redis Sharding)
Redis Sharding是一种客户端Sharding方式。
Java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool, jedis的特点:
- 采用一致性哈希算法(consistent hashing),将key和节点name同时hashing,采用的算法是MURMUR_HASH。采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
- ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
预分片(presharding)
@TODO
代理中间件(Tair/Codis)
上面分别介绍了多Redis服务器集群的两种方式,它们是基于客户端sharding的Redis Sharding,和基于服务端sharding的Redis Cluster。
Pre-Sharding方案实际上可以理解为预先分配一个相当大的集合,对Key哈希的结果落在这个集合中,集合的每个元素又与具体的物理节点存在多对一的路由映射关系,这张路由表由一个配置中心进行维护。
回过头来再细想下,一致性哈希中的虚拟节点,实际上也可以归类到Pre-Sharding方案中。换句话说,只要是key经过两次哈希,第一次Hash到虚拟节点,第二次Hash到物理节点,都可以算作Pre-Sharding。只不过区别在于,一致性哈希的第二次Hash其路由表是按照算法固定的,Tair/Codis的第二次Hash其路由表是第三方可配的。
扩容
详见: Redis集群的数据划分与扩容探讨 - Xueqiu Engineering Blog @Archived
主从同步
@TODO
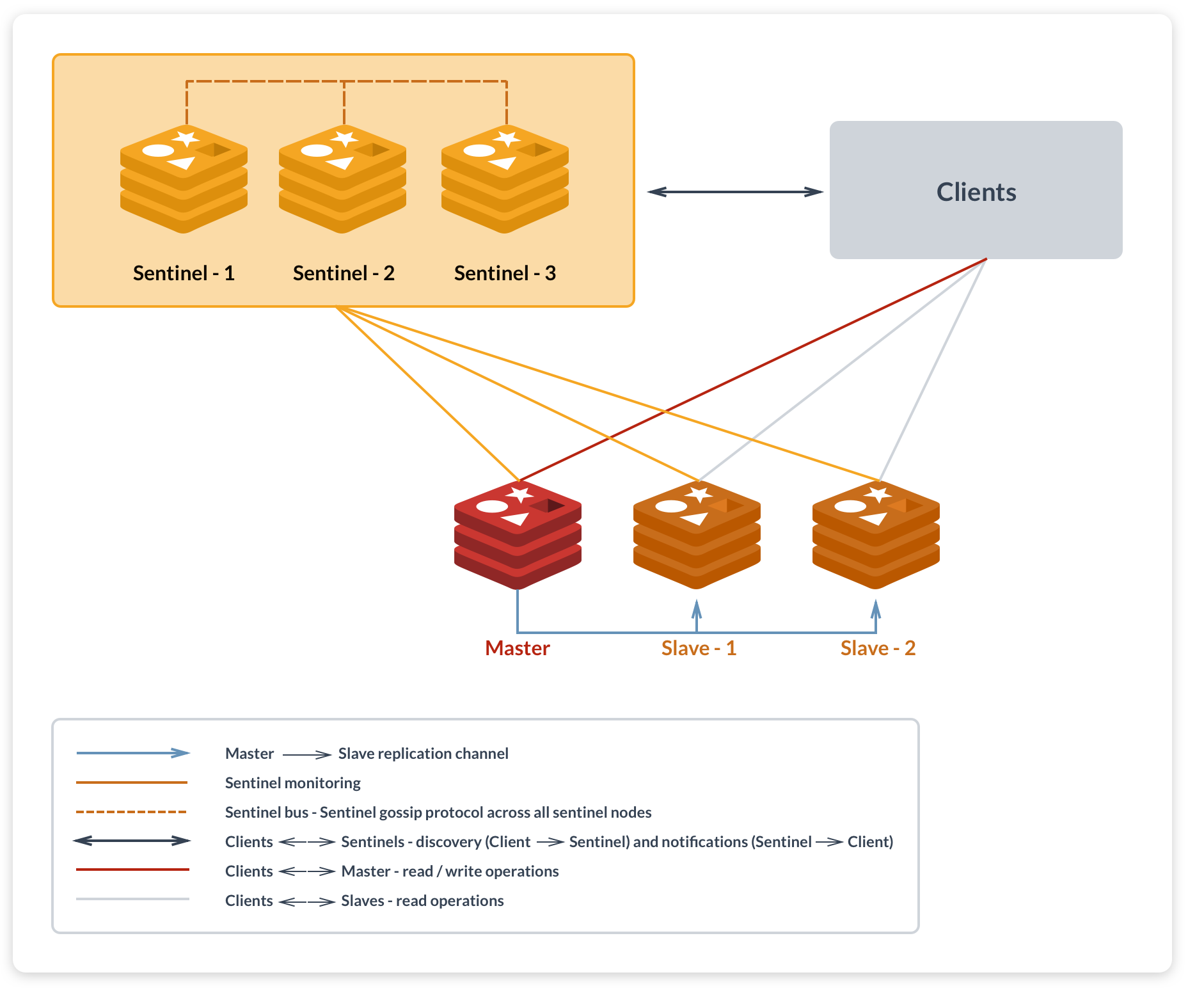
Sentinel
Redis-Sentinel是Redis官方推荐的高可用性(HA)解决方案,可以实现:
- Master宕机时自动切换到从
- 如果发现某个redis节点运行出现状况,能够通知另外一个进程(例如它的客户端);
运行sentinel有两种方式:redis-sentinel /path/to/sentinel.conf
redis-server /path/to/sentinel.conf --sentinel
配置文件解读
# 定义一个'mymaster', 2表示两个Sentinel认为Master挂掉了才算 |
事务处理
@TODO
性能测试
- redis 性能测试的基本命令如下:
redis-benchmark [option] [option value] - 以下实例同时执行 10000 个请求来检测性能:
redis-benchmark -n 10000 -q- -c: 指定并发连接数
- -n: 指定请求数
- -d: 以字节的形式指定 SET/GET 值的数据大小
安装&配置
- 启动: /opt/apps/redis/bin/redis-server /opt/conf/redis/${port}.conf
- conf文件: http://yijiebuyi.com/blog/bc2b3d3e010bf87ba55267f95ab3aa71.html
源码
事件驱动详解
Redis 事件驱动详解 - Redis 源码日志 - 极客学院Wiki
附录
INFO返回信息
server 部分记录了 Redis 服务器的信息,它包含以下域:
- redis_version : Redis 服务器版本
- redis_git_sha1 : Git SHA1
- redis_git_dirty : Git dirty flag
- os : Redis 服务器的宿主操作系统
- arch_bits : 架构(32 或 64 位)
- multiplexing_api : Redis 所使用的事件处理机制
- gcc_version : 编译 Redis 时所使用的 GCC 版本
- process_id : 服务器进程的 PID
- run_id : Redis 服务器的随机标识符(用于 Sentinel 和集群)
- tcp_port : TCP/IP 监听端口
- uptime_in_seconds : 自 Redis 服务器启动以来,经过的秒数
- uptime_in_days : 自 Redis 服务器启动以来,经过的天数
- lru_clock : 以分钟为单位进行自增的时钟,用于 LRU 管理
clients 部分记录了已连接客户端的信息,它包含以下域:
- connected_clients : 已连接客户端的数量(不包括通过从属服务器连接的客户端)
- client_longest_output_list : 当前连接的客户端当中,最长的输出列表
- client_longest_input_buf : 当前连接的客户端当中,最大输入缓存
- blocked_clients : 正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量
memory 部分记录了服务器的内存信息,它包含以下域:
- used_memory : 由 Redis 分配器分配的内存总量,以字节(byte)为单位
- used_memory_human : 以人类可读的格式返回 Redis 分配的内存总量
- used_memory_rss : 从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致。
- used_memory_peak : Redis 的内存消耗峰值(以字节为单位)
- used_memory_peak_human : 以人类可读的格式返回 Redis 的内存消耗峰值
- used_memory_lua : Lua 引擎所使用的内存大小(以字节为单位)
- mem_fragmentation_ratio : used_memory_rss 和 used_memory 之间的比率
mem_allocator : 在编译时指定的, Redis 所使用的内存分配器。可以是 libc 、 jemalloc 或者 tcmalloc 。
在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。
当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。
内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。
当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。
Because Redis does not have control over how its allocations are mapped to memory pages, high used_memory_rss is often the result of a spike in memory usage.当 Redis 释放内存时,分配器可能会,也可能不会,将内存返还给操作系统。
如果 Redis 释放了内存,却没有将内存返还给操作系统,那么 used_memory 的值可能和操作系统显示的 Redis 内存占用并不一致。
查看 used_memory_peak 的值可以验证这种情况是否发生。
persistence 部分记录了跟 RDB 持久化和 AOF 持久化有关的信息,它包含以下域:
- loading : 一个标志值,记录了服务器是否正在载入持久化文件。
- rdb_changes_since_last_save : 距离最近一次成功创建持久化文件之后,经过了多少秒。
- rdb_bgsave_in_progress : 一个标志值,记录了服务器是否正在创建 RDB 文件。
- rdb_last_save_time : 最近一次成功创建 RDB 文件的 UNIX 时间戳。
- rdb_last_bgsave_status : 一个标志值,记录了最近一次创建 RDB 文件的结果是成功还是失败。
- rdb_last_bgsave_time_sec : 记录了最近一次创建 RDB 文件耗费的秒数。
- rdb_current_bgsave_time_sec : 如果服务器正在创建 RDB 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。
- aof_enabled : 一个标志值,记录了 AOF 是否处于打开状态。
- aof_rewrite_in_progress : 一个标志值,记录了服务器是否正在创建 AOF 文件。
- aof_rewrite_scheduled : 一个标志值,记录了在 RDB 文件创建完毕之后,是否需要执行预约的 AOF 重写操作。
- aof_last_rewrite_time_sec : 最近一次创建 AOF 文件耗费的时长。
- aof_current_rewrite_time_sec : 如果服务器正在创建 AOF 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数。
- aof_last_bgrewrite_status : 一个标志值,记录了最近一次创建 AOF 文件的结果是成功还是失败。
如果 AOF 持久化功能处于开启状态,那么这个部分还会加上以下域:
- aof_current_size : AOF 文件目前的大小。
- aof_base_size : 服务器启动时或者 AOF 重写最近一次执行之后,AOF 文件的大小。
- aof_pending_rewrite : 一个标志值,记录了是否有 AOF 重写操作在等待 RDB 文件创建完毕之后执行。
- aof_buffer_length : AOF 缓冲区的大小。
- aof_rewrite_buffer_length : AOF 重写缓冲区的大小。
- aof_pending_bio_fsync : 后台 I/O 队列里面,等待执行的 fsync 调用数量。
- aof_delayed_fsync : 被延迟的 fsync 调用数量。
stats 部分记录了一般统计信息,它包含以下域:
- total_connections_received : 服务器已接受的连接请求数量。
- total_commands_processed : 服务器已执行的命令数量。
- instantaneous_ops_per_sec : 服务器每秒钟执行的命令数量。
- rejected_connections : 因为最大客户端数量限制而被拒绝的连接请求数量。
- expired_keys : 因为过期而被自动删除的数据库键数量。
- evicted_keys : 因为最大内存容量限制而被驱逐(evict)的键数量。
- keyspace_hits : 查找数据库键成功的次数。
- keyspace_misses : 查找数据库键失败的次数。
- pubsub_channels : 目前被订阅的频道数量。
- pubsub_patterns : 目前被订阅的模式数量。
- latest_fork_usec : 最近一次 fork() 操作耗费的毫秒数。
replication : 主/从复制信息
- role : 如果当前服务器没有在复制任何其他服务器,那么这个域的值就是 master ;否则的话,这个域的值就是 slave。注意,在创建复制链的时候,一个从服务器也可能是另一个服务器的主服务器。
如果当前服务器是一个从服务器的话,那么这个部分还会加上以下域:
- master_host : 主服务器的 IP 地址。
- master_port : 主服务器的 TCP 监听端口号。
- master_link_status : 复制连接当前的状态, up 表示连接正常, down 表示连接断开。
- master_last_io_seconds_ago : 距离最近一次与主服务器进行通信已经过去了多少秒钟。
- master_sync_in_progress : 一个标志值,记录了主服务器是否正在与这个从服务器进行同步。
如果同步操作正在进行,那么这个部分还会加上以下域:
- master_sync_left_bytes : 距离同步完成还缺少多少字节数据。
- master_sync_last_io_seconds_ago : 距离最近一次因为 SYNC 操作而进行 I/O 已经过去了多少秒。
如果主从服务器之间的连接处于断线状态,那么这个部分还会加上以下域:
- master_link_down_since_seconds : 主从服务器连接断开了多少秒。
cpu 部分记录了 CPU 的计算量统计信息,它包含以下域:
- used_cpu_sys : Redis 服务器耗费的系统 CPU 。
- used_cpu_user : Redis 服务器耗费的用户 CPU 。
- used_cpu_sys_children : 后台进程耗费的系统 CPU 。
- used_cpu_user_children : 后台进程耗费的用户 CPU 。
commandstats 部分记录了各种不同类型的命令的执行统计信息,比如命令执行的次数、命令耗费的 CPU 时间、执行每个命令耗费的平均 CPU 时间等等。对于每种类型的命令,这个部分都会添加一行以下格式的信息:
- cmdstat_XXX:calls=XXX,usec=XXX,usecpercall=XXX
cluster 部分记录了和集群有关的信息,它包含以下域:
- cluster_enabled : 一个标志值,记录集群功能是否已经开启。
- keyspace 部分记录了数据库相关的统计信息,比如数据库的键数量、数据库已经被删除的过期键数量等。对于每个数据库,这个部分都会添加一行以下格式的信息: dbXXX:keys=XXX,expires=XXX