《亿级流量网站架构核心技术》 - 读书笔记

一些概念和测试基准
本章内容包括: 系统可用性的概念和指标, 系统性能的概念和指标, 如何严谨地做性能测试.
系统可用性的概念和指标
高可用性(high availability,缩写为 HA),IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统与构成该系统的各个组件相比可以更长时间运行
其度量方式,是根据系统损害、无法使用的时间,以及由无法运作恢复到可运作状况的时间,与系统总运作时间的比较。计算公式为: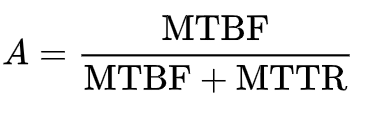
A(可用性),MTBF(平均故障间隔),MDT(平均修复时间)
在线系统和执行关键任务的系统通常要求其可用性要达到5个9标准(99.999%)。
- 3个9:(1-99.9%) x 365 x 24 =8.76小时,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
- 4个9:(1-99.99%) x 365 x 24 =0.876小时=52.6分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
- 5个9:(1-99.999%) x 365 x 24 x 60 =5.26分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
那么X个9里的X只代表数字3~5,为什么没有1~2,也没有大于6的呢?我们接着往下计算:
- 1个9:(1-90%)x365=36.5天
- 2个9:(1-99%)x365=3.65天
- 6个9:(1-99.9999%)x365x24x60x60=31秒
可以看到1个9和、2个9分别表示一年时间内业务可能中断的时间是36.5天、3.65天,这种级别的可靠性或许还不配使用“可靠性”这个词;而6个9则表示一年内业务中断时间最多是31秒,那么这个级别的可靠性并非实现不了,而是要做到从5个9》6个9的可靠性提升的话,后者需要付出比前者几倍的成本,所以在企业里大家都只谈(3~5)个9。
系统性能的概念和指标
① 系统延迟(Latency): 系统在处理一个请求或一个任务时的延迟, 有平均值, 中位数, TP 三种衡量指标:
- 平均值(Avg): 延迟的评测性能指标原则: 不要用平均值! 例如测试了10次,有9次是1ms,而有1次是1s,那么平均数据就是100ms,很明显,这完全不能反应性能测试的情况
- 中位数(Mean): 可能会比平均数要稍微靠谱一些,所谓中位数的意就是把将一组数据按大小顺序排列,处在最中间位置的一个数叫做这组数据的中位数 ,这意味着至少有50%的数据低于或高于这个中位数。
- TP指标(Top Percentile): 这是最为正确的统计做法 ,也就是英文中的 Top Percentile ,Top百分数,是一个统计学里的术语,与平均数、中位数都是一类。
- TP50:指在一个时间段内(如5分钟),统计该方法每次调用所消耗的时间,并将这些时间按从小到大的顺序进行排序,取第50%的那个值作为TP50 值;正确使用TP50做监控: 配置此监控指标对应的报警阀值后,需要保证在这个时间段内该方法所有调用的消耗时间至少有50%的值要小于此阀值,否则系统将会报警。
- TP90: 通过上面的定义, 90%的请求中最长耗时; TP90也即要求 比这个耗时还长的请求次数 比例应该在总次数的10%以下
- TP99: 与TP50/90值计算方式一致,它们分别代表着对方法的不同性能要求,TP50相对较低,TP90则比较高,TP99,TP999则对方法性能要求很高
Amazon AWS 定义的 P99: https://docs.aws.amazon.com/zh_cn/elasticbeanstalk/latest/dg/health-enhanced-metrics.html
② 吞吐量(Throughput): 每秒可处理的请求数/事务数, 等于并发数/平均响应时间
- QPS: Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够响应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准。可用由PV粗略计算QPS的两种方法:
- 按照每天80%的请求集中在20%的时间,
峰值QPS= (PV*80%) / (24*3600*20%) - 按照峰值QPS是评价QPS的三倍计算,
峰值QPS= (PV*3) / (24*3600)
- 按照每天80%的请求集中在20%的时间,
- TPS: Transactions Per Second, 也就是事务数/秒。它是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,最终利用这些信息来估计得分。
- Java GC回收器的评估指标里也有吞吐量的概念: 系统总运行时间 = 应用程序耗时 + 总GC耗时。
③ 除了 Latency 和 Throughtput , 其他的性能衡量指标还有:
- PV: page view
- UV: user view;
- VU: 并发用户数, 也叫虚拟用户数(VU), 同时请求系统的用户数. 一般情况下, 大型系统(业务量大、机器多)做性能测试 5000 个并发用户就够了, 中小型系统做性能测试 1000 个并发用户就足够了;
如何严谨地做性能测试
一般来说,性能测试要统一考虑这么几个因素:Thoughput吞吐量,Latency响应时间,资源利用(CPU/MEM/IO/Bandwidth…),成功率,系统稳定性。
- 一,你得定义一个系统的响应时间latency,建议是TP99,以及成功率。比如路透的定义:99.9%的响应时间必需在1ms之内,平均响应时间在1ms以内,100%的请求成功。
- 二,在这个响应时间的限制下,找到最高的吞吐量。测试用的数据,需要有大中小各种尺寸的数据,并可以混合。最好使用生产线上的测试数据。
- 三,在这个吞吐量做Soak Test,比如:使用第二步测试得到的吞吐量连续7天的不间断的压测系统。然后收集CPU,内存,硬盘/网络IO,等指标,查看系统是否稳定,比如,CPU是平稳的,内存使用也是平稳的。那么,这个值就是系统的性能
- 四,找到系统的极限值。比如:在成功率100%的情况下(不考虑响应时间的长短),系统能坚持10分钟的吞吐量。
- 五,做Burst Test。用第二步得到的吞吐量执行5分钟,然后在第四步得到的极限值执行1分钟,再回到第二步的吞吐量执行5钟,再到第四步的权限值执行1分钟,如此往复个一段时间,比如2天。收集系统数据:CPU、内存、硬盘/网络IO等,观察他们的曲线,以及相应的响应时间,确保系统是稳定的。
- 六、低吞吐量和网络小包的测试。有时候,在低吞吐量的时候,可能会导致latency上升,比如TCP_NODELAY的参数没有开启会导致latency上升(详见TCP的那些事),而网络小包会导致带宽用不满也会导致性能上不去,所以,性能测试还需要根据实际情况有选择的测试一下这两咱场景。
高可用
本章内容包括: 负载均衡, 限流, 隔离, 降级, 超时与重试, 回滚, 压测与预案.
负载均衡与反向代理(Nginx)
这里不再介绍Nginx的具体配置
负载均衡(loadbalance)
Nginx目前提供了HTTP七层负载均衡(ngx_http_upstream_module), 意思是在OSI第七层应用层的负载均衡, 1.9版本也开始提供TCP四层负载均衡(ngx_stream_upstream_module)
upstream服务器配置
略
负载均衡算法
几种负载均衡算法:
- 轮询(Round Robin)
- 加权轮询(Weight Round Robin)
- 随机(Random)
- 加权随机(Weight Random)
- 源地址哈希(Hash)
- 一致性哈希(ConsistentHash)
- 最小连接数(Least Connections)
- 低并发优先(Active Weight)
Nginx配置中常用的负载均衡:
- round robin(轮询): 默认的
- ip哈希:
ip_hash, 根据客户端ip - 哈希:
hash $uri:根据uri进行哈希hash $key consistent:一致性哈希
一致性哈希(consistent hashing):
一致哈希(consistent hashing)是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n个关键字重新映射,其中K是关键字的数量,n是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
- 首先求出服务器(节点)的哈希值,并将其配置到0~2^32的圆(continuum)上。// 为什么哈希范围是2^32? 四字节
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台memcached服务器上。
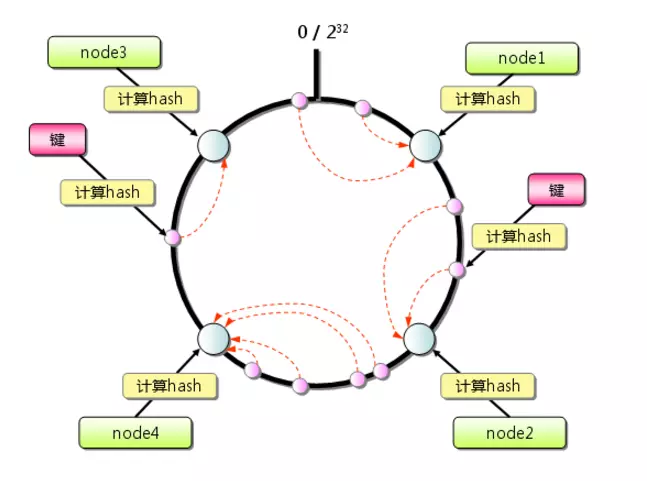
- 如果增加一个服务器节点, 如下图, 新增 node5 节点, 只有在圆(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响
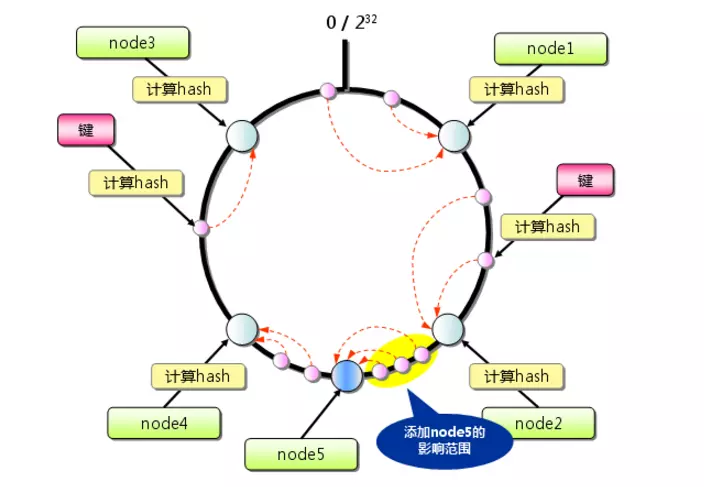
一致性哈希存在的问题: 在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜。
解决方式: 虚拟节点
失败重试机制
主要针对在Nginx的upstream和proxy_pass进行配置, 作用是实现”多少时间内失败多少次, 则从upstream列表里摘除”
upstream心跳检查
失败重试是被动的去摘除upstream无效机器, 心跳检测可以认为是一种主动的检查并摘除无效机器, 主要在upstream的check里, 有http和tcp两种
长连接(keepalive)
- client与nginx之间的长连接:
http里的keepalive_timeout 300s 300s;- 第一个参数: client和nginx建立的长连接, 如果在此时间内没有实际消息发送, nginx将主动关闭此连接(默认是75秒)
- 第二个参数: nginx向client发送response的http头, 其中的
Keep-Alive: timeout=xx
- nginx与upstream之间的长连接:
upstream里的keepalive 100这里的100指的是每个Worker与upstream服务器可缓存的最大连接数,
降级
服务降级,当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
降级预案
即可以降级的功能点, 降级服务需要从服务端链路考虑, 根据用户访问的服务调用链路决定哪里可以降级. 一般情况下可以考虑降级的点有:
- 页面降级(整个页面or页面片段):非核心业务的页面, 在紧急情况下可以降级, 可以利用nginx把该页面直接跳转一个静态页
- 页面异步请求:比如异步加载的信息, 在紧急情况下可以降级
- 非核心功能降级:比如商品详情页的推荐/热销
- 读降级:紧急情况下只读缓存, 适用于一致性要求不高的情况
- 写降级:在高并发抢购这种情景下, 可以先更新cache, 然后异步写回数据库
- 风控降级:识别机器人, 根据用户画像和用户风控等级降级, 需要提前做好用户风控等级的功能
降级后的处理方式一般有:返回默认值, 返回静态页面, 从缓存读数据而不是数据库
自动降级
- 超时降级: 访问数据库, 非本地接口(RPC, HTTP)超时, 需要提前设置合理的超时时间/重试机制/重试次数
- 故障降级: 远程调用的接口RPC抛异常, HTTP服务500错误等,
- 流量降级: 超过限流阈值时..
人工开关降级
开关可以放在Redis, Zookeeper上.
读写服务降级
- 库存扣减案例: 正常情况下扣减Redis, 同步扣减DB, 当流量过大时, 降级为发送一条扣减消息, 然后异步写入DB实现最终一致性
多级降级
从用户到系统, 降级离用户越近, 最终落到后端系统的QPS越低, 对后端系统的保护就越好
- 页面JS降级开关
- 接入层降级开关, 一般是Nginx
- 后端应用降级开关
通过Hystrix实现熔断降级
@TODO
Dubbo
@TODO
集群容错
几种常用高可用策略:
- 失效转移(failover): 当出现失败,重试其他服务器,通常用于读操作等幂等行为(保证调用 1 次与 N 次效果相同),重试会带来更长延迟。
- 快速失败(failfast): 只发起一次调用,失败立即报错,通常用于非幂等性的写操作。
- 失效安全(failsafe): 出现异常时忽略,但记录这一次失败,存入日志中。// 失败安全策略的核心是即使失败了也不会影响整个调用流程。通常情况下用于旁路系统或流程中,它的失败不影响核心业务的正确性。在实现上,当出现调用失败时,会忽略此错误,并记录一条日志,同时返回一个空结果,在上游看来调用是成功的。
- 失败通知(failback): 客户端需要能够获取到服务调用失败的具体信息,通过对失败错误码等异常信息的判断,决定后续的执行策略,例如非幂等性的服务调用。// Dubbo中的Failback策略中,如果调用失败,则此次失败相当于Failsafe,将返回一个空结果。而与Failsafe不同的是,Failback策略会将这次调用加入内存中的失败列表中,对于这个列表中的失败调用,会在另一个线程中进行异步重试,重试如果再发生失败,则会忽略,即使重试调用成功,原来的调用方也感知不到了。因此它通常适合于,对于实时性要求不高,且不需要返回值的一些异步操作。
超时与重试
在实际开发过程中,笔者见过太多故障是因为没有设置超时或者设置得不对而造成的。而这些故障都是因为没有意识到超时设置的重要性而造成的。如果应用不设置超时,则可能会导致请求响应慢,慢请求累积导致连锁反应,甚至造成应用雪崩。
而有些中间件或者框架在超时后会进行重试(如设置超时重试两次),读服务天然适合重试,但写服务大多不能重试(如写订单,如果写服务是幂等的,则重试是允许的),重试次数太多会导致多倍请求流量,即模拟了DDoS攻击,后果可能是灾难,因此,务必设置合理的重试机制,并且应该和熔断、快速失败机制配合。
Nginx超时设置
- 客户端超时设置: 对于客户端超时主要设置有读取请求头超时时间、读取请求体超时时间、发送响应超时时间、长连接超时时间。
keepalive_timeout time [header_timeout]:- time默认是75s, 表示长连接的超时时间(客户端在75s期间没有任何请求, Nginx将会主动发送FIN关闭连接);
- header_timeout会通过HTTP头
Keep-Alive: timeout=xx告知客户端长连接超时时间,
- 上游服务器(upstream)超时:
- 超时设置:
proxy_connect_timeout time:与后端/上游服务器建立连接的超时时间,默认为60s,此时间不超过75s。 - 重试设置:
proxy_next_upstream_tries number:设置重试次数,默认0表示不限制,注意此重试次数指的是所有请求次数(包括第一次和之后的重试次数之和)。proxy_next_upstream_timeout time:设置重试最大超时时间,默认0表示不限制。
- 超时设置:
- DNS解析超时: @TODO
Web容器超时设置
以Tomcat为例:
connectionTimeout: 当client与tomcat建立连接之后, 在”connectionTimeout”时间之内, 仍然没有得到client的请求数据, 此时连接将会被断开, connectionTimeout只会在链接建立之后, 得到client发送http-request信息前有效.socket.soTimeout: 从收到client请求后, 到返回数据, 这段超时时间 @UncertainkeepAliveTimeout: 当无实际数据交互时,连接被保持的时间,单位:毫秒。在未指定此属性时,将使用connectionTimeout作为keepAliveTimeout。
不过我们通常在tomcat前面还有nginx等代理服务器,我们通常希望链接keepAlive的机制由代理服务器控制,比如nginx来决定链接是否需要“保持活性”(注意,与keep_alive不同),当然nginx服务器只会保留极少的长连接,几乎所有的链接都会在使用结束后主动close;有nginx与client保持,而不再是tomcat与client保持。
Apache HttpClient(客户端)超时设置
- connectionTimeout: 建立连接超时时间, 指Client发出请求后, 到建立连接这段超时时间, 如果在该时间仍没有完成连接的建立会抛出connectionTimeout异常;
- socketTimeout: 等待响应超时时间, 指Client对Url发起请求(连接已经建立), 到收到服务端的Response这段超时时间
数据库客户端连接超时设置
@TODO
总结
本章主要介绍了如何在Web应用访问的整个链路上进行超时时间设置。通过配置合理的超时时间,防止出现某服务的依赖服务超时时间太长且响应慢,以致自己响应慢甚至崩溃。
客户端和服务器端都应该设置超时时间,而且客户端根据场景可以设置比服务器端更长的超时时间。如果存在多级依赖关系,如A调用B,B调用C,则超时设置应该是A>B>C,否则可能会一直重试,引起DDoS攻击效果。不过最终如何选择还是要看场景,有时候客户端设置的超时时间就是要比服务器端的短,可以通过在服务器端实施限流/降级等手段防止DDoS攻击。
超时之后应该有相应的策略来处理,常见的策略有重试(等一会儿再试、尝试其他分组服务、尝试其他机房服务,重试算法可考虑使用如指数退避算法)、摘掉不存活节点(负载均衡/分布式缓存场景下)、托底(返回历史数据/静态数据/缓存数据)、等待页或者错误页。对于非幂等写服务应避免重试,或者可以考虑提前生成唯一流水号来保证写服务操作通过判断流水号来实现幂等操作。
在进行数据库/缓存服务器操作时,记得经常检查慢查询,慢查询通常是引起服务出问题的罪魁祸首。也要考虑在超时严重时,直接将该服务降级,待该服务修复后再取消降级。
对于有负载均衡的中间件,请考虑配置心跳/存活检查,而不是惰性检查。
超时重试必然导致请求响应时间增加,最坏情况下的响应时间=重试次数×单次超时时间,这很可能严重影响用户体验,导致用户不断刷新页面来重复请求,最后导致服务接收的请求太多而挂掉,因此除了控制单次超时时间,也要控制好用户能忍受的最长超时时间。
超时时间太短会导致服务调用成功率降低,超时时间太长又会导致本应成功的调用却失败了,这也要根据实际场景来选择最适合当前业务的超时时间,甚至是程序动态自动计算超时时间。
比如商品详情页的库存状态服务,可以设置较短的超时时间,当超时时降级返回有货,而结算页服务就需要设置稍微长一些的超时时间保证确实有货。在实际开发中,不要轻视超时时间,很多重大事故都是因为超时时间不合理导致的,设置超时时间一定是只有好处没有坏处的,请立即Review你的代码吧。
回顾: TCP协议里的重试机制:
Client发给Server端SYN包后, Server端要返给Client一个SYN-ACK, 然后Server要等待Client发过来的ACK,
Server发送SYN-ACK并等待ACK的过程是有重试机制的, 重试的间隔时间从1s开始每次都翻倍,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s。
隔离
- 进线程隔离
- 集群隔离
- 机房隔离
- 读写隔离
- 动静隔离: 静态资源放CDN
- 爬虫隔离
- 热点隔离: 诸如秒杀, 抢购做成独立系统
- 资源隔离
限流
限流算法
- 令牌桶:
- 漏桶:
应用级限流
- 限制总并发数/连接数: Tomcat的几个参数 acceptCount, maxConnections, maxThreads
- 限制单个接口的请求数:
- 限制某个时间窗口的请求数:用Guava的Cache, 时间戳做Key, 访问次数AtomicLong做Value. . . 缺点是无法应对突发流量, 瞬时请求可能都被允许
- 平滑限流:Guava的RateLimiter提供的令牌桶算法可以对请求进行速率平均化, 比如5request/秒, 每隔200ms处理一个请求
Nginx层限流
Nginx提供了两个限流模块:
- 限制总并发数的
ngx_http_limit_conn_module - 漏桶算法的
ngx_http_limit_req_module
高性能
本章内容: 缓存, 连接池, 异步并发, 数据库拆分, 任务系统拆分, 队列.
有关并发的参考→ 架构-并发系统-C100K
应用级缓存
本章以Java应用缓存为例.
缓存回收策略
- 基于空间和容量: 超过xx时回收
- 基于存活时间(TTL): 缓存数据从创建开始计算, 过期则清除
- 基于Java GC:
- 软引用
- 弱引用
- 基于回收算法:
- FIFO
- LRU: Least Recently Used, 最近最不常访问的被淘汰, 访问时间距离现在最久远的被淘汰(较常用)
- LFU: Least Frequently Used, 在一段时间内访问次数最少的被淘汰, 访问频率最少的被淘汰(可能需要预热)
Java应用级缓存的类型
- 堆内缓存: 用Java软引用/弱引用对象作为缓存, 不需要序列化. Guava的Cache, Ehcache3.x
- GuavaCache提供了基于容量, 基于JavaGC和TTL的淘汰策略
- 堆外缓存: 缓存在JVM内存之外, 减少GC次数, 但是需要序列化的时间开销, Ehcache3.x, MapDB
缓存的设计模式
首先介绍三个名词:
SoR(SystemofRecord): 记录系统, 一般是DB;
Cache: Cache的访问速度比SoR要快, 数据放在Cache中可以提升访问速度, 减少回源次数;
回源: 缓存没有命中, 需要去SoR取数据, 这叫做回源;
Cache Aside
即代码围绕着缓存写, 由业务层的代码读取/更新缓存.
- 读:先读Cache, 没有读到再读SoR, 并更新Cache
- 写(更新):
- 方案1: 先更新SoR, 再更新Cache
- 方案2: 先更新SoR, 再失效Cache, 读取的时候再把SoR的数据写入Cache
CacheAside存在的问题:
如果并发更新Cache, 会出现Cache和SoR数据不一致的情况(A更新了SoR, 还没来得及更新Cache, B线程插入进来更新SoR并更新Cache, 之后A线程更新Cache), 这种有两种解决方式:
- 用canal订阅数据库(SoR)的binlog, 增量更新Cache, 缓存的更新会有延迟;
- 通过对请求合理的hash, 让同一个读服务落到同一个实例;
Cache as SoR
即Cache和SoR是一个整体, 业务层代码只对Cache进行读写, 然后Cache再委托给SoR进行真实的读写. 有三种实现模式:Read-Throught, Write-Throught, Write-Behind:
- Read-Throught: 读cache, 如果没有读到, 由cache把SoR的数据更新到缓存里. GuavaCache提供了此模式, 创建Cache时需要指定一个CacheLoader, 从Cache未能读到数据时, GuavaCache委托CacheLoader从SoR读取, 用户代码只需要调用cache. get
- Write-Throught: 用户调用cache. set, 缓存更新后, 同步写到SoR, 不需要用户代码干预
- Write-Behind: 与上面的区别是, Write-Behind是异步批量写SoR
Copy Pattern
- Copy-On-Road: 读时复制
- Copy-On-Write: 写时复制
数据库拆分(分库分表)
- 垂直切分: 一般根据业务来
- 垂直分表: 通俗的说法叫做“大表拆小表”,拆分是基于关系型数据库中的“列”(字段)进行的。通常情况,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中
- 垂直分库: 按照业务模块来划分出不同的数据库,而不是像早期一样将所有的数据表都放到同一个数据库中。
- 水平切分:
- 哈希分库: 比如根据自增主键对库的总数取余操作, 可以多次哈希, 第一次哈希分库, 第二次分表:
- 例子: UserId后四位mod32分到32个库中,同时再将UserId后四位Div32Mod32将每个库分为32个表,共计分为1024张表。
- 范围分库: 比如根据自增主键范围切分,
- 优点: 单表大小可控,天然水平扩展。
- 缺点: 无法解决集中写入瓶颈的问题。
- 哈希分库: 比如根据自增主键对库的总数取余操作, 可以多次哈希, 第一次哈希分库, 第二次分表:
分库分表带来的问题
- 跨库join的问题解决方案:
- 字段冗余
- Redis存储索引
- 夸库事务: @TODO
唯一ID
- 利用数据库自增ID:
- 优点:最简单。
- 缺点:单点风险、单机性能瓶颈。
- TwitterSnowflake
- 优点:高性能高可用、易拓展。
- 缺点:需要独立的集群以及ZK。
- UUID, GUID
案例
这里是一些”一句话解决方案”.
最佳实践list
- LVS/F5/HAProxy负载均衡 -> Nginx/Apache -> Redis/Memcached
- Kafka,ActiveMQ负责解耦的消息队列
- RPC框架Thrift, 序列化Protobuf
- 分布式框架Zookeeper
- Mysql分表分库的Cobar
- 通用搜索引擎ElasticSearch
如何存储密码
- bcrypt:带盐的散列算法, 可以指定costfactor, 10表示2^10次方次运算, 返回的散列值包括盐和加密后的文本
- Dropbox是如何安全地存储用户密码的 #
AES256(bcrypt(SHA512(pwd), salt(10)))
附录:名词解释
- 高可用High-Availability、高可扩展性(高可伸缩性)High-Scalability
- 解耦LooselyCoupled
- 吞吐量Throughput(QPS/TPS)、并发量C10K
- 冗余Redundancy、分区Partitions、缓存Caches、代理Proxies、索引Indexes、队列Queues
- 集群Cluster、主从Master-Slave、水平/垂直切分Sharding
- 请求负载均衡LoadBalancing、请求路由Route、状态复制Replication
- 故障转移Failover、故障回复Failback、心跳检测Healthcheck/Heartbeat
- 纵向扩展Scale-up、横向扩展Scale-out
- 自动升降级Auto-upgrade/downgrade
- scaleup:纵向扩展, 指提高单台机器的存储(RAM, HD)上限
- scaleout:横向扩展, 多台主机