![]()
HBase简介
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。
- HBase适用于简单数据写入(如“消息类”应用)和海量、结构简单数据的查询(如“详单类”应用),适合稀疏表;
- 作为大数据MapReduce的后台数据源,以支撑离线分析型应用;
基于HDFS分布式文件系统, 可扩展性+;
场景:
Facebook的消息类应用,包括Messages、Chats、Emails和SMS系统,用的都是HBase;
淘宝的WEB版阿里旺旺,后台是HBase;
小米的米聊用的也是HBase;
概念: 表, 行, 列族, 列, 版本
- 行(Row): HBase 中的一行包含一个行键和一个或多个与其相关的值的列。在存储行时,行按字母顺序排序。
出于这个原因,行键的设计非常重要。目标是以相关行相互靠近的方式存储数据。常用的行键模式是网站域。如果你的行键是域名,则你可能应该将它们存储在相反的位置(org.apache.www,org.apache.mail,org.apache.jira)。这样,表中的所有 Apache 域都彼此靠近,而不是根据子域的第一个字母分布。 - 列(Column): HBase 中的列由一个列族和一个列限定符组成,它们由:(冒号)字符分隔。
- 列族(Column Family): 出于性能原因,列族在物理上共同存在一组列和它们的值。在 HBase 中每个列族都有一组存储属性,例如其值是否应缓存在内存中,数据如何压缩或其行编码是如何编码的等等。表中的每一行都有相同的列族,但给定的行可能不会在给定的列族中存储任何内容。列族一旦确定后,就不能轻易修改,因为它会影响到 HBase 真实的物理存储结构,但是列族中的列标识(Column Qualifier)以及其对应的值可以动态增删。
- 列限定符(Column Qualifier): 列限定符被添加到列族中,以提供给定数据段的索引。鉴于列族的content,列限定符可能是content:html,而另一个可能是content:pdf。虽然列族在创建表时是固定的,但列限定符是可变的,并且在行之间可能差别很大。
- 单元格(Cell) 单元格是行、列族和列限定符的组合,并且包含值和时间戳,它表示值的版本。
- 时间戳(Timestamp) 时间戳与每个值一起编写,并且是给定版本的值的标识符。默认情况下,时间戳表示写入数据时 RegionServer 上的时间,但可以在将数据放入单元格时指定不同的时间戳值。
概念视图

上面的数据有相同的Row key = “com.cnn.www”, 每行表示一个数据版本, 共有5个版本(Time Stamp表示),
有两个列族 contents 和anchor, 两个列族下分别有contents:html, anchor:cnnsi.com, anchor:my.look.ca三个列,
用json格式表示概念视图:
{ |
物理视图

物理存储是按照列族(family)分布的, 相同的列族在连续的物理空间存储.
如下图, 一张表里有不同的列族CF1, CF2, 每个列族下面有自己的qualifier, 可以看到一张表的数据被按照列族分布在不同的物理位置。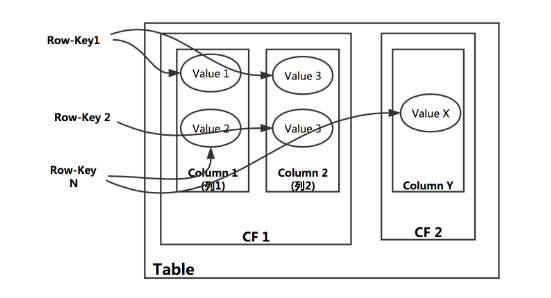
TTL
HBase的生存时间(TTL)是针对列族设置的, 一旦达到到期时间,HBase 将自动删除行。修改一个列族的TTL如下:disable 'table1' #先禁用表
alter 'table1', {NAME=>'col_family1', TTL => '100'} #指明修改哪个列族, 100的单位是秒
enable 'table1'
从上面可以看到, TTL虽然是针对列族的参数, 但是给某个列族修改/增加TTL需要暂时disable表, 所以在生产环境里最好还是在建表的时候就给每个列族指定好TTL
安装
@TODO
客户端API: 基础
包括hbase shell命令行 和Java API
命令行
hbase shell: 进入hbase shell, 然后可以用以下的hbase命令行list: list all tablehelp 'list': 查看帮助status: 查看状态create 'table1','col_family1','col_family2': 创建表, 并包含两个列族alter 'table1', NAME => 'col_family1', TTL => '604800': 修改列族的TTL(秒)describe 'table1': 查看表描述put 'table1', 'rowkey1', 'col_family1:col111', 'value': 插入一条数据, 格式为put 表名, 行键, 列族:列, 值get 'table1', 'rowkey1': 查询记录, 格式为get 表名, 行键get 'table1', 'rowkey1', 'col_family1:col111': 查询记录, 格式为get 表名, 行键, 列族:列get 'table1', 'rowkey1', { COLUMN => 'col_family1:col111', VERSIONS=>1}: 查询记录, 格式为get 表名, 行键, {条件}, 其中COLUMN和VERSIONS是预定义的, 分别表示列和版本号count 'table1': 统计表的行数scan 'table1' , {'LIMIT' => 5}: 扫描一个表,{'LIMIT' => 5}是可选的scan 'table1', {COLUMNS => 'fam:col', STARTROW => 'executed|1530226272', STOPROW => 'executed|1530233472'}: 带条件的扫描scan 'hbase:meta'扫描 hbase:meta 表, 旧的HBase版本里该表叫:.META.scan 'hbase:meta', {COLUMNS => 'info:regioninfo'}参考 # META表deleteall 'table1', 'rowkey1', 'column': 删除该行键下”column”列的数据deleteall 'table1', 'rowkey1': 删除所有该行键下的数据truncate 'table1'清空表disable 'table1'然后drop 'table1': 删除表
Java API
@TODO
批处理(bacth)
批量处理操作:可以批量处理跨多行的不同操作,
许多基于列表的操作,如delete、get的列表操作都是基于batch 方法实现的.
Configuration conf = HBaseConfiguration.create(); |
Table vs BufferedMutator
In the new API, BufferedMutator is used.
You could change Table t = connection.getTable(TableName.valueOf("foo")) to BufferedMutator t = connection.getBufferedMutator(TableName.valueOf("foo")). And then change t.put(p) to t.mutate(p)
行锁
行锁 在客户端 API中仍然存在, 但是不鼓励使用,因为管理不好,会锁定整个RegionServer.
客户端API: 高级特性
过滤器
Get 和 Scan 实例可以用 filters 配置,以应用于 RegionServer.
所有的过滤器都在服务端生效, 叫做”谓词下推”( predicate push down)。这样可以保证过滤掉的数据不会被传送到客户端.
过滤器在客户端被创建, 通过RPC传送到服务器端, 然后在服务器端执行.
Hbase客户端api提供了几种过滤器:
- SingleColumnValueFilter : 列值过滤, 用于测试值的情况(相等,不等,范围 、、、)
- RegexStringComparator: 支持正则表达式的值比较
- SubstringComparator: 用于检测一个子串是否存在于值中。大小写不敏感。
- FamilyFilter: 用于过滤列族。 通常,在Scan中选择ColumnFamilie优于在过滤器中做。
- QualifierFilter: 用于基于列名(即 Qualifier)过滤.
- ColumnPrefixFilter: 可基于列名(即Qualifier)前缀过滤。
- RowFilter: 通常认为行选择时Scan采用 startRow/stopRow 方法比较好。然而 RowFilter 也可以用。
下面是列值过滤器的一个例子:
SingleColumnValueFilter filter = new SingleColumnValueFilter(
cf,
column,
CompareOp.EQUAL,
Bytes.toBytes("my value")
);
scan.setFilter(filter);
计数器
一种支持的数据类型,值得一提的是“计数器”(如, 具有原子递增能力的数值)。参考 HTable的 Increment .
同步计数器在区域服务器中完成,不是客户端。
incr '<table>', '<row>', '<column>', |<increment-value>| |
协处理器
@TODO
批处理客户端
Hive
Hive+HBase: 使用Hive读取Hbase中的数据。
我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现的。
参考: Hive和HBase整合用户指南
Apache Pig
如果不满足Hvie提供的HQL查询, 还可以用Pig Latin脚本实现更复杂的MapReduce Job,
Pig支持对Hbase表的读写, Hbase表中的”列”可以映射到Pig的元组
MapReduce
与Hadoop MapReduce Java API的整合
HBase架构 & 原理
本章包括HBase底层实现(LSM Tree), META表设计, 查询数据时HBase都做了什么? 查询时间复杂度分析, Region拆分策略.
架构介绍
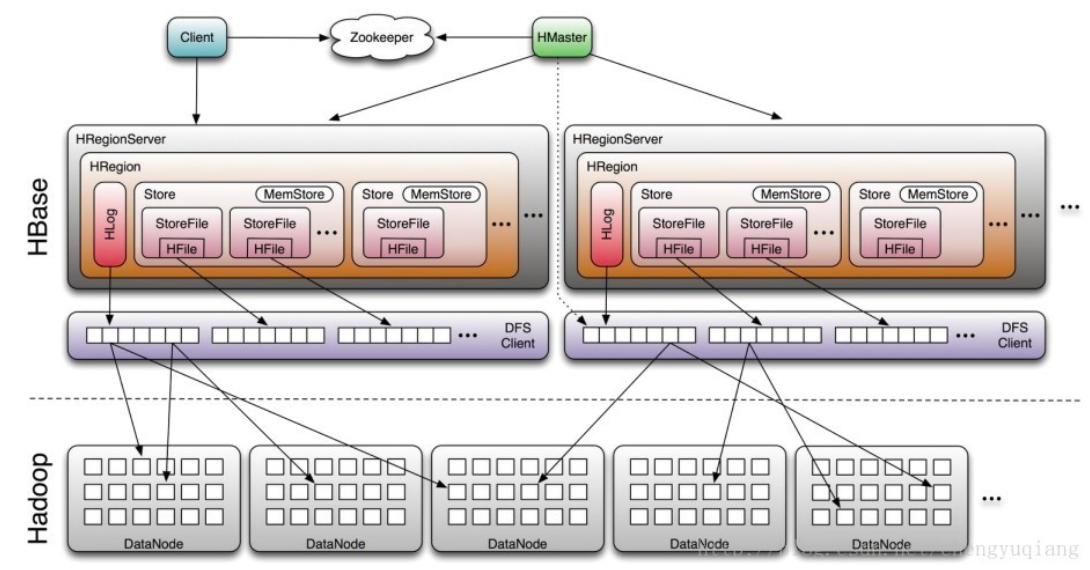
HBase包含3个重要组件:Zookeeper、HMaster和HRegionServer。
- (1)Zookeeper: 为整个HBase集群提供协助服务,包括:
- a. 存放整个 HBase集群的元数据以及集群的状态信息。
- b. 实现HMaster主从节点的failover。
ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),
并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover,或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。
ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。
- (2)HMaster: 主要用于监控和操作集群中的所有HRegionServer。HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的MasterElection机制保证总有一个Master在运行,HMaster 主要负责Table和Region的管理工作:
- a. 管理用户对表的增删改查操作
- b. 管理HRegionServer的负载均衡,调整Region分布
- c. Region Split后,负责新Region的分布
- d. 在HRegionServer停机后,负责失效HRegionServer上Region迁移
- (3)HRegion Server: HBase中最核心的模块,主要负责响应用户I/O请求,向HDFS文件系统中读写数据。
- a. 存放和管理本地HRegion。
- b. 读写HDFS,管理Table中的数据。
- c. Client直接通过HRegionServer读写数据(从HMaster中获取元数据,找到RowKey所在的HRegion/HRegionServer后)。
HMaster
@TODO
HRegion Server
@TODO [[#HBase #RegionServer 架构和存储]]
MemStore
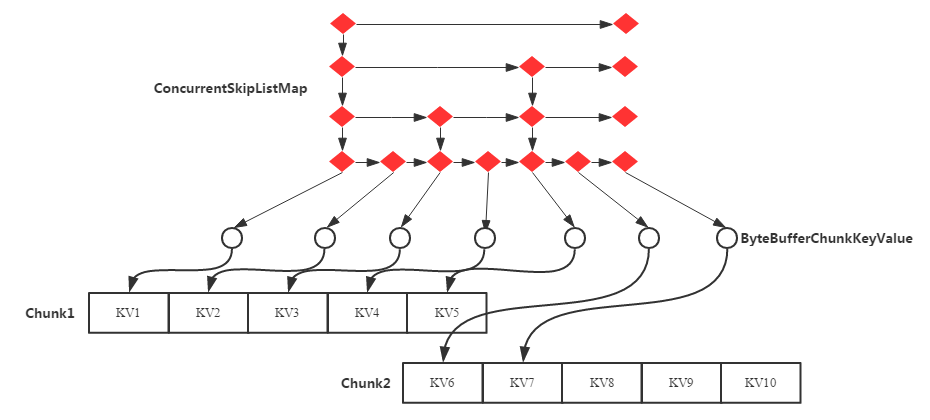
StoreFile(HFile)
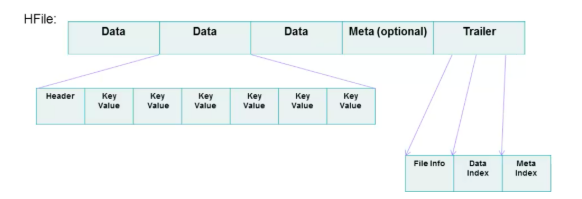
HFile 的文件长度是变长的,仅 FILE INFO/Trailer 部分是定长,Trailer 中有指针指向其他数据块的起始点。而 Index 数据块则记录了每个 Data 块和 Meta 块的起始点。Data 块和 Meta 块都是可有可无的,但对于大多数 HFile,都有 Data 块。
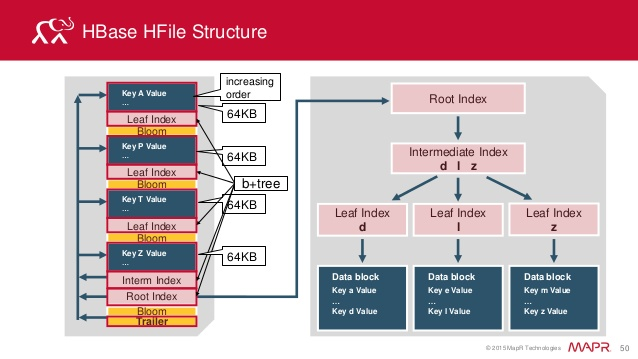
图2 的说明: HFile分为trailer,索引块,数据块,bloom过滤器。
- Data Block主要存储用户的key-value数据 // 1个Data Block默认为64kb
- Index Block: 存储了每一个Data Block的索引信息{Offset,Size,FirstKey}, 如上图,Index Block 是三层索引
- Trailer主要记录 Data Index的索引信息{Data Index Offset, Data Block Count}
- Bloom filter主要用来快速定位Key是否在HFile。// Bloom Block 的数据是在启动的时候就已经加载到内存里,除了 Block Cache 和 MemStore 以外,这个也对 HBase 随机读性能的优化起着至关重要的作用。生成 HFile 的时候,会将 key 经过三次 hash 最终落到 Bloom Block 位数组的某三位上,并将其由0更改成1,以此标记该 key 的确存在这个 HFile 文件之中,查询的时候不需要将文件打开并检索,避免了一次 I/O 操作。然而随着 HFile 的膨胀,Bloom Block会越来越大。
HFile 的 Data Index
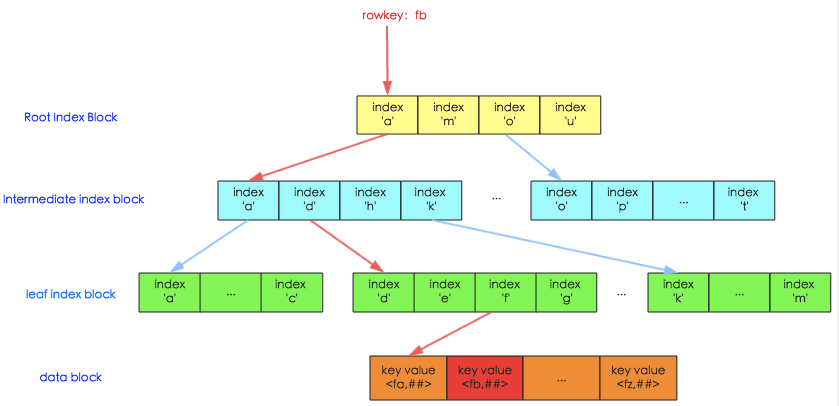
图中上面三层为索引层,在数据量不大的时候只有最上面一层,数据量大了之后开始分裂为多层,最多三层,如图所示。最下面一层为数据层,存储用户的实际keyvalue数据。这个索引树结构类似于InnoSQL的聚集索引,只是HBase并没有辅助索引的概念。
图中红线表示一次查询的索引过程(HBase中相关类为HFileBlockIndex和HFileReaderV2),基本流程可以表示为:
- 用户输入rowkey为fb,在root index block中通过二分查找定位到fb在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为root index block常驻内存,所以这个过程很快。
- 将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index ‘d’和’h’之间,接下来访问索引’d’指向的叶子节点。
- 同理,将索引’d’指向的中间节点索引块加载到内存,一样通过二分查找定位找到fb在index ‘f’和’g’之间,最后需要访问索引’f’指向的数据块节点。
- 将索引’f’指向的数据块加载到内存,通过遍历的方式找到对应的keyvalue。
上述流程中因为 中间节点、 叶子节点 和 数据块 都需要加载到内存,所以io次数正常为3次。但是实际上HBase为block提供了缓存机制,可以将频繁使用的block缓存在内存中,可以进一步加快实际读取过程。所以,在HBase中,通常一次随机读请求最多会产生3次io,如果数据量小(只有一层索引),数据已经缓存到了内存,就不会产生io。
ROOT & META表
早期的设计(0.96.0)之前是被称之为三层查询架构: ROOT -> META -> Region.
-ROOT-和.META.是两个特殊的表。其中.META. 表记录 Region 分区信息,同时,.META. 也可以有多个 Region 分区,同时-ROOT-表又记录.META. 表的 Region 信息,但-ROOT-只有一个 Region,而-ROOT-表的位置由 Hbase 的集群管控框架,即 Zookeeper 记录。
- -ROOT-:记录.META.表的Region信息。
- .META.:记录用户表的Region信息。
从0.96版本以后,三层架构被改为二层架构,-ROOT-表被去掉了。直接把.META.表所在的RegionServer信息存储到了zk中的/hbase/meta-region-server。再后来引入了namespace,.META.表这样别扭的名字被修改成了hbase:meta。
META表的缓存设计
Meta缓存的数据结构设计的很巧妙,首先采用了copy on write的思想,自定义了一个CopyOnWriteArrayMap。copy on write即可以支持并发读,当写的时候采用拷贝引用的方式快速变更。HBase自定义了一个数组Map,其中数组结构第一层为表,数组部分的查询采用二分查找;第二层是startkey;当有RegionLocation信息需要更新时,采用System.arraycopy实现快速拷贝更新。
图: 通过table和rowkey快速定位到对应的Region(复杂度是多少?):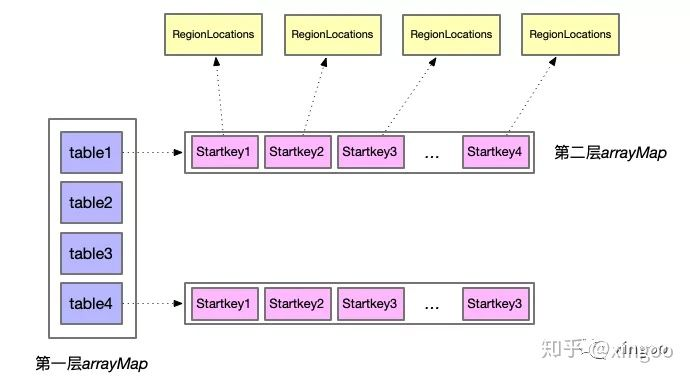
LSM Tree
[[#HBase LSM-Tree原理]] @TODO
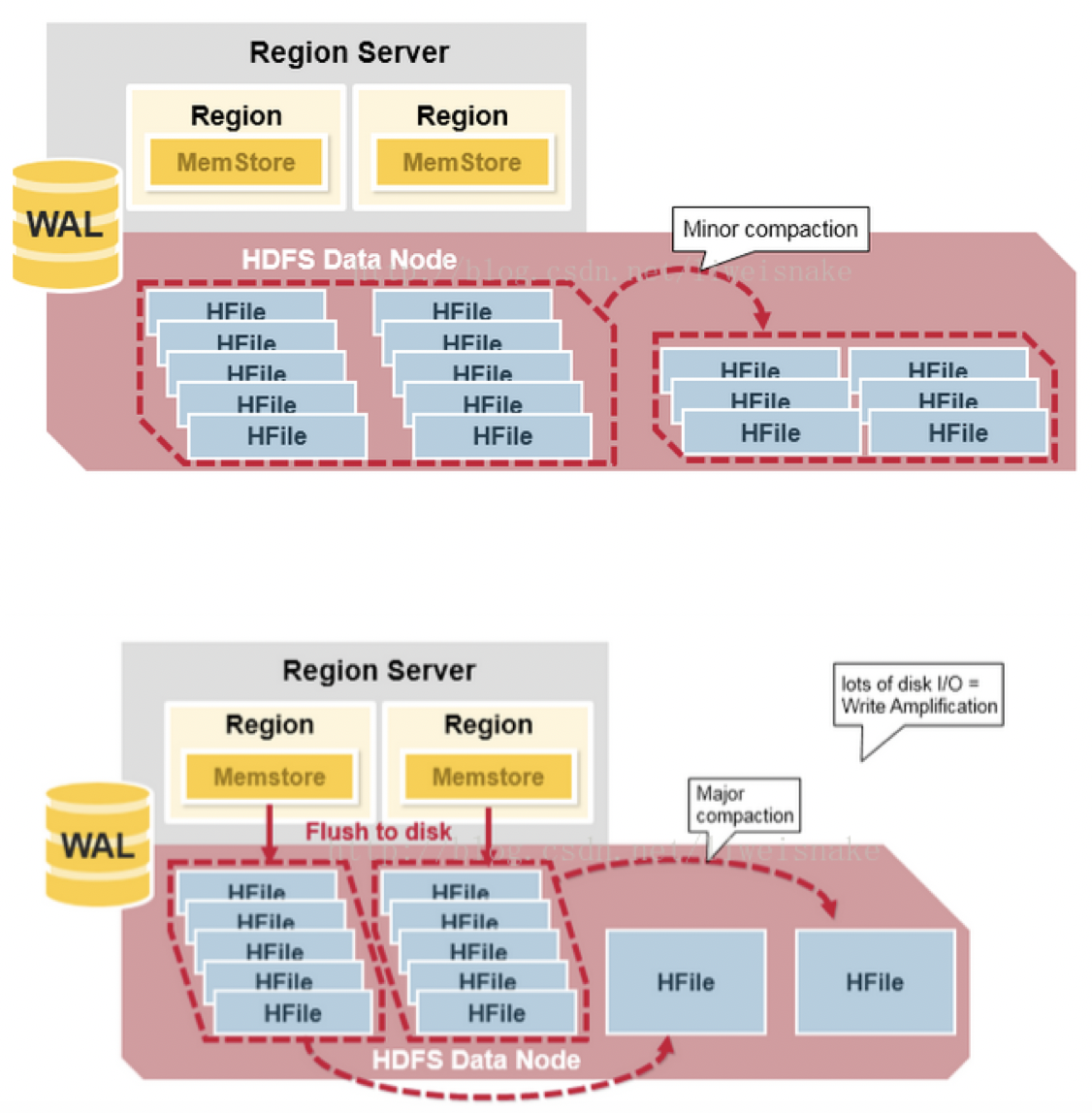
Minor & Major Compact
当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(major compact),将对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对 StoreFile进行分割(split),等分为两个StoreFile。
其中,minor compaction是自动将相关的小文件做一些适当的紧凑,但不彻底;
而major compaction则是放在午夜跑的定时任务,将文件做最大化的紧凑。这时候LSM树的磁盘树数量很少, 被并入一个大的树
Region拆分策略
HBase的表由多个Regions组成,这些Regions分布在多个Region Server上面。
Region的拆分逻辑是通过CompactSplitThread线程的requestSplit方法来触发的,每当执行MemstoreFlush操作时都会调用该方法进行判断,看是否有必要对目标Region进行拆分。Region的拆分有三种策略:
- ConstantSizeRegionSplitPolicy:在0.94之前只有这个策略。当region中的一个store(对应一个columnfamily的一个storefile)超过了配置参数hbase.hregion.max.filesize时拆分成两个,该配置参数默认为10GB。region拆分线是最大storefile的中间rowkey。
- IncreasingToUpperBoundRegionSplitPolicy:0.94默认策略。拆分阈值是
Min (R^2 * “hbase.hregion.memstore.flush.size”, “hbase.hregion.max.filesize”),其中R是一张表中位于同一个regionserver的region的数目。hbase.hregion.memstore.flush.size默认是128MB,后一个参数默认是10GB。因此,如果region没有预拆分,默认的行为是,表的第一个region会位于一个regionserver上,然后当达到1^2*128MB=128MB,region被拆分成2个,它们仍然位于同一个regionserver上,因此,随着region的增加,拆分阈值也增加:128MB、512MB、1152MB、2GB、3.2GB、4.6GB、6.2GB,依次类推,直至达到9个region之后,拆分阈值就恒定为10GB。这可以控制一个regionserver拥有的region个数在小数据量的时候不会太少,在大的数据量时候不会太多。region拆分线是最大storefile的中间rowkey。 KeyPrefixRegionSplitPolicy:你可以配置用来对你的rowkey进行分组所依赖的前缀长度,然后该策略保证region的拆分线不会在一组拥有相同前缀的rowkey的中间,也就是说,拆分后的region中,相同前缀的rowkey会一直位于同一个region上。其他的拆分策略与IncreasingToUpperBoundRegionSplitPolicy是一样的。
如何配置策略?
通过配置参数hbase.regionserver.region.split.policy来配置,这是全局的。可以针对单独的表进行配置,用表的APIHTableDescriptor.setValue()可以配置。另外,后一种配置还可以使用自定义的拆分策略类。
应用场景 & 性能优化
表的设计
在HBase中表的概念并不是那么重要, 数据的物理存储是基于列族的.
Row Key设计
设计合理的 Row Key设计可以加速scan操作, 还可以在大量写入数据时让多个RegionServer分担负载.
Region是HBase中扩展和负载均衡的基本单元, Region本质上是以Row Key的字典顺序连续存储的, 这种设计优化了scan的操作,
一个Table最初只有一个Region, 当一个Region过大时, 系统会在中间键(middle key)将这个Region拆分成两个大致相等的子Region。
Row Key设计不好就会造成读写热点问题,造成大量客户端直接访问集群某一个或者极少数的节点,造成节点性能下降或者Region不可用
几种Row key设计方案:
- key长度不宜过长, 否则占用过多存储空间;
- 如果有大量的对时间范围的scan查询, 时间戳适合放在Row key后面, 还有一种常用的设计方式是用
Long.MAX - Timestamp, 这样scan()可以先取到时间戳最新的行; - 避免Row key前缀是递增序列, 比如 时间戳 or 递增的user_id, 这样会导致某个Region成为读写热点, 有如下几种解决方案
- 如果uid这种递增id做Row key前缀(前几位几乎相同), 可以把uid的字符倒序排列;
- 对做Row key前缀的属性进行哈希, 这种做法可以完全解决Region读写热点问题, 所有的数据都是均匀写在每个Region上, 但是scan几乎不可能;
- 哈希和预分区结合使用, 预分区一开始就预建好了N个region,这些region都维护着自已的”start-end keys”, 可以使用
hash mod N计算出应该属于哪个region; 但是scan会带来一些额外的操作, 一般用多线程scan每个分区然后汇总结果;
对于”哈希和预分区结合使用”的方案, 在上传时,客户端需要跟N个regionserver保持连接,
在查询时,无论是连续区域查询,还是单条查询,都需要访问N个逻辑分区,这意味着与N个regionserver都要建立连接。
当集群规模较大(即N较大)时,连接开销是巨大的。因此,这种方案只适用于小规模集群(N小于20)。
在小集群情况下,直接让客户端遍历所有分区时,如果采取多线程查询,启动线程数为k(k小于等于N),不同线程的查询负载会落到不同regionserver上。
也就是说,原本一个regionserver执行一次操作就能完成的查询,采取方案后每个regionserver都要执行一次操作才能完成。
性能优化
① Server端优化:
- JVM内存优化:
export HBASE_REGIONSERVER_OPT="-Xmx8g -Xms8g -Xmn128m -XX:+UseParNewGC -XX:UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+printGCDetails -XX:+PrintGCTimeStamps -Xloggc:${HBASE_HOME}/logs/gc-${hostname}-hbase.log" - 使用压缩: GZIP, LZO, Zippy/Snappy, 创建表的时候指定列族的压缩格式:
create 'testtable',{NAME => 'colfam1',COMPRESSION => 'GZ'} - 预分Region: 在建表的时候预先创建多个Region, 并规定好每个Region存储的Rowkey范围, 通过对数据的特性进行分析预先创建分区可以有效的解决HBase中的数据倾斜问题
- 防止拆分/合并风暴:
- 考虑这种情况:拆分之后的两个子region都已恒定的速率增大,导致在同一时刻进行拆分,但是如果两个region拆分之后继续以恒定的速率增长导致子子region又一起拆分,这种情况被称为拆分/合并风暴,这将导致磁盘IO的飙升。这种情况下,与其依赖HBase的自动拆分,用户不如手动使用split和major_compact命令来管理,因为手动管理的话可以将这些region的拆分/合并时机分割开来,尽量分散IO负载。
- 碰到这种情况的时候不要忘记把配置文件中的
hbase.hregion.max.filesize设置为非常大(但是major_compat时会耗时很长, 尽量在维护期间做major_compat)
region热点问题: 通过合理设计row key解决;
Major Compaction是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。
另外,一般情况下,Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
② 客户端API优化:
- 禁用自动刷写
Table.setAutoFlush(false)
比较elasticsearch 和 hbase
海量日志数据存储用 elasticsearch 和 hbase 哪个好? - 知乎
- 1)两者都可以通过扩展集群来加大可存储的数据量。随着数据量的增加,es的读写性能会有所下降
- 2)数据更新es数据更新是对文档进行更新,需要先将es中的数据取出,设置更新字段后再写入es。hbase是列存储的,可以方便地更新任意字段的值。
- 3)查询复杂度hbase支持简单的行、列或范围查询,若没有对查询字段做二级索引的话会引发扫全表操作,性能较差。而ES提供了丰富的查询语法,支持对多种类型的精确匹配、模糊匹配、范围查询、聚合等操作,ES对字段做了反向索引,支持全文检索, 即使在亿级数据量下还可以达到秒级的查询响应速度。
- 4)字段扩展性hbase和es都对非结构化数据存储提供了良好的支持。es可以通过动态字段方便地对字段进行扩展,而hbase本身就是基于列存储的,可以很方便地添加qualifier来实现字段的扩展
源码
hbase-client 源码分析
施工中
createConnection()
Configuration configuration = HBaseConfiguration.create(); |
创建connection过程如下:ConnectionFactory.createConnection(Configuration conf), 返回的是一个HConnectionImplementation的对象, 调用了HConnectionImplementation的构造函数:HConnectionImplementation(Configuration conf, boolean managed, ExecutorService pool, User user)
看一下HConnectionImplementation构造都做了哪些初始化:{
this.asyncProcess = this.createAsyncProcess(this.conf);
this.rpcClient = RpcClientFactory.createClient(this.conf, this.clusterId, this.metrics);
}
getTable()
Connection connection = ConnectionFactory.createConnection(configuration); |
Connection.getTable()实际调用到了HConnectionImplementation.getTable()
返回了一个新对象: new HTable(tableName, this, this.connectionConfig, this.rpcCallerFactory, this.rpcControllerFactory, pool)
HTable有几个重要成员:
connection,
multiAp,
locator
在HTable初始化时, 上面几个成员按如下顺序初始化:this.multiAp = this.connection.getAsyncProcess();
this.locator = new HRegionLocator(this.tableName, this.connection);
put()
Put put = new Put(rowKey.getBytes()); |
HTable.put(Put) 并不会立刻发送RPC请求, 而是等多次请求后再一次backgroundFlushCommits,submit(tableName, buffer, true, null, false);