深度学习入门
机器学习 vs 深度学习
机器学习 通过算法分析数据,从结果中进行学习,然后将「学习后的算法」用来做出决策或进行预测,例子有我们熟悉的聚类、贝叶斯网络和视觉数据映射等等。
深度学习,深度学习是机器学习的一个子集,和其它所有机器学习一样都是基于算法。然而它并非像「数据分类」一样根据任务选择的算法,而是模仿人类大脑结构与运算过程——识别非结构化输入的数据,输出精确地行为和决策。
机器学习可以是监督的也可以是非监督的,这意味着大型神经网络可以接受「标签化输入」,但并不需要。
深度学习是机器学习中一种基于对数据进行表征学习的算法。表征学习的目标是寻求更好的表示方法并创建更好的模型来从大规模未标记数据中学习这些表示方法。
一部分最成功的深度学习方法涉及到对人工神经网络的运用。“深度”是一个术语。它指的是一个神经网络中的层的数量。浅层神经网络有一个所谓的隐藏层,而深度神经网络则不止一个隐藏层。
当一个神经网络处理输入时,它通过输入数据和输出数据创造层,这种级别的深度学习让神经网络从原始数据中「自动抽取特征」而无需人工来贴标签。
神经网络由大量被称为神经元的简单处理器构成,处理器用数学公式模仿人类大脑中的神经元。这些人造神经元就是神经网络最基础的「部件」。
简而言之,每一个神经元接受两个或更多的输入,处理它们,然后输出一个结果。一些神经元从额外的传感器接收输入,然后其他神经元被其他已激活的神经元激活。神经元可能激活其它的神经元,或者通过触发的行动影响外部环境。所有的行为都是在「自动生成」的隐藏层中发生的,每个连续的图层都会输入前一层的输出。
参考 「机器学习」还是「深度学习」,哪个更适合你? @Ref
深度学习框架
TensorFlow
Caffe2
深度学习框架Caffe开发时秉承的理念是“表达、速度和模块化”,最初是源于2013年的机器视觉项目,此后,Caffe还得到扩展吸收了其他的应用,如语音和多媒体。
因为速度放在优先位置 ,所以Caffe完全用C+ +实现,并且支持CUDA加速,而且根据需要可以在CPU和GPU处理间进行切换。分发内容包括免费的用于普通分类任务的开源参考模型,以及其他由Caffe用户社区创造和分享的模型。
一个新的由Facebook 支持的Caffe迭代版本称为Caffe2,现在正在开发过程中,即将进行1.0发布。其目标是为了简化分布式训练和移动部署,提供对于诸如FPGA等新类型硬件的支持,并且利用先进的如16位浮点数训练的特性。
MXNet
MXNet是一个可移植的、可伸缩的深度学习库,是亚马逊的DNN框架的选择,结合了神经网络几何的象征性声明与张量操作的命令性编程。
MXNet可跨多个主机扩展到多个GPU,接近线性扩展效率为85%,具有出色的开发速度、可编程性和可移植性。它支持Python,R,Scala,Julia和C ++,支持程度各不相同,它允许你混合符号和命令式编程风格。
DeepLearning4j
Java和Scala在Hadoop和Spark之上的深度学习框架。
神经网络
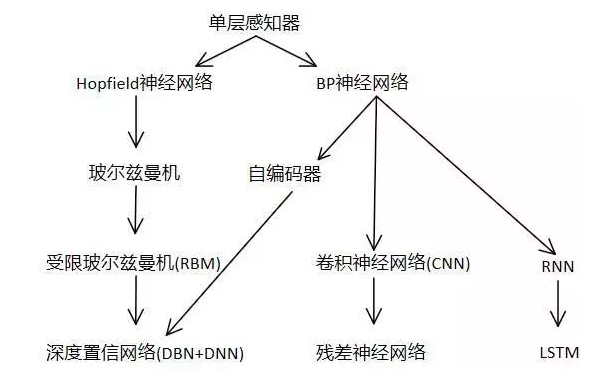
神经网络的种类:
- 基础神经网络:单层感知器,线性神经网络,BP神经网络,Hopfield神经网络等
- 进阶神经网络:玻尔兹曼机,受限玻尔兹曼机,递归神经网络等
- 深度神经网络:深度置信网络,卷积神经网络,深度残差网络,LSTM网络等
神经网络的发展图: